 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation of a State of the Art Text-to-SQL Model: Lessons Learned and Challenges Found
Paper and Code
Dec 09, 2023


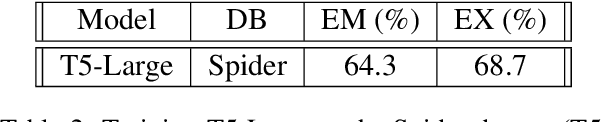
There are many recent advanced developments for the Text-to-SQL task, where the Picard model is one of the the top performing models as measured by the Spider dataset competition. However, bringing Text-to-SQL systems to realistic use-cases through domain adaptation remains a tough challenge. We analyze how well the base T5 Language Model and Picard perform on query structures different from the Spider dataset, we fine-tuned the base model on the Spider data and on independent databases (DB). To avoid accessing the DB content online during inference, we also present an alternative way to disambiguate the values in an input question using a rule-based approach that relies on an intermediate representation of the semantic concepts of an input question. In our results we show in what cases T5 and Picard can deliver good performance, we share the lessons learned, and discuss current domain adaptation challenges.