 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinOps Agent -- A Use-Case for IT Infrastructure and Cost Optimization
Oct 29, 2025



FinOps (Finance + Operations) represents an operational framework and cultural practice which maximizes cloud business value through collaborative financial accountability across engineering, finance, and business teams. FinOps practitioners face a fundamental challenge: billing data arrives in heterogeneous formats, taxonomies, and metrics from multiple cloud providers and internal systems which eventually lead to synthesizing actionable insights, and making time-sensitive decisions. To address this challenge, we propose leveraging autonomous, goal-driven AI agents for FinOps automation. In this paper, we built a FinOps agent for a typical use-case for IT infrastructure and cost optimization. We built a system simulating a realistic end-to-end industry process starting with retrieving data from various sources to consolidating and analyzing the data to generate recommendations for optimization. We defined a set of metrics to evaluate our agent using several open-source and close-source language models and it shows that the agent was able to understand, plan, and execute tasks as well as an actual FinOps practitioner.
LLM-as-a-Judge for Reference-less Automatic Code Validation and Refinement for Natural Language to Bash in IT Automation
Jun 12, 2025In an effort to automatically evaluate and select the best model and improve code quality for automatic incident remediation in IT Automation, it is crucial to verify if the generated code for remediation action is syntactically and semantically correct and whether it can be executed correctly as intended. There are three approaches: 1) conventional methods use surface form similarity metrics (token match, exact match, etc.) which have numerous limitations, 2) execution-based evaluation focuses more on code functionality based on pass/fail judgments for given test-cases, and 3) LLM-as-a-Judge employs LLMs for automated evaluation to judge if it is a correct answer for a given problem based on pre-defined metrics. In this work, we focused on enhancing LLM-as-a-Judge using bidirectional functionality matching and logic representation for reference-less automatic validation and refinement for Bash code generation to select the best model for automatic incident remediation in IT Automation. We used execution-based evaluation as ground-truth to evaluate our LLM-as-a-Judge metrics. Results show high accuracy and agreement with execution-based evaluation (and up to 8% over baseline). Finally, we built Reflection code agents to utilize judgments and feedback from our evaluation metrics which achieved significant improvement (up to 24% increase in accuracy) for automatic code refinement.
Tackling Execution-Based Evaluation for NL2Bash
May 10, 2024Given recent advancement of Large Language Models (LLMs), the task of translating from natural language prompts to different programming languages (code generation) attracts immense attention for wide application in different domains. Specially code generation for Bash (NL2Bash) is widely used to generate Bash scripts for automating different tasks, such as performance monitoring, compilation, system administration, system diagnostics, etc. Besides code generation, validating synthetic code is critical before using them for any application. Different methods for code validation are proposed, both direct (execution evaluation) and indirect validations (i.e. exact/partial match, BLEU score). Among these, Execution-based Evaluation (EE) can validate the predicted code by comparing the execution output of model prediction and expected output in system. However, designing and implementing such an execution-based evaluation system for NL2Bash is not a trivial task. In this paper, we present a machinery for execution-based evaluation for NL2Bash. We create a set of 50 prompts to evaluate some popular LLMs for NL2Bash. We also analyze several advantages and challenges of EE such as syntactically different yet semantically equivalent Bash scripts generated by different LLMs, or syntactically correct but semantically incorrect Bash scripts, and how we capture and process them correctly.
Domain Adaptation of a State of the Art Text-to-SQL Model: Lessons Learned and Challenges Found
Dec 09, 2023


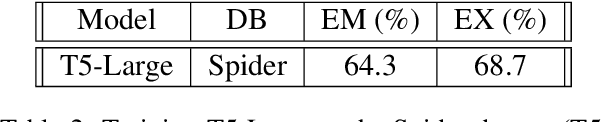
There are many recent advanced developments for the Text-to-SQL task, where the Picard model is one of the the top performing models as measured by the Spider dataset competition. However, bringing Text-to-SQL systems to realistic use-cases through domain adaptation remains a tough challenge. We analyze how well the base T5 Language Model and Picard perform on query structures different from the Spider dataset, we fine-tuned the base model on the Spider data and on independent databases (DB). To avoid accessing the DB content online during inference, we also present an alternative way to disambiguate the values in an input question using a rule-based approach that relies on an intermediate representation of the semantic concepts of an input question. In our results we show in what cases T5 and Picard can deliver good performance, we share the lessons learned, and discuss current domain adaptation challenges.
Recognizing and Splitting Conditional Sentences for Automation of Business Processes Management
Apr 01, 2021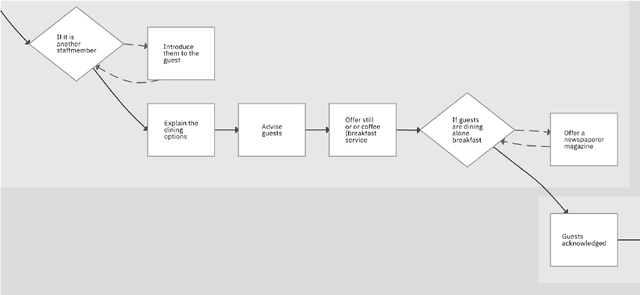


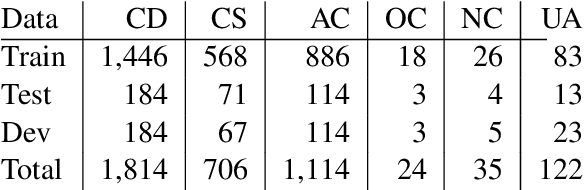
Business Process Management (BPM) is the discipline which is responsible for management of discovering, analyzing, redesigning, monitoring, and controlling business processes. One of the most crucial tasks of BPM is discovering and modelling business processes from text documents. In this paper, we present our system that resolves an end-to-end problem consisting of 1) recognizing conditional sentences from technical documents, 2) finding boundaries to extract conditional and resultant clauses from each conditional sentence, and 3) categorizing resultant clause as Action or Consequence which later helps to generate new steps in our business process model automatically. We created a new dataset and three models solve this problem. Our best model achieved very promising results of 83.82, 87.84, and 85.75 for Precision, Recall, and F1, respectively, for extracting Condition, Action, and Consequence clauses using Exact Match metric.