 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-as-a-Judge for Reference-less Automatic Code Validation and Refinement for Natural Language to Bash in IT Automation
Jun 12, 2025



In an effort to automatically evaluate and select the best model and improve code quality for automatic incident remediation in IT Automation, it is crucial to verify if the generated code for remediation action is syntactically and semantically correct and whether it can be executed correctly as intended. There are three approaches: 1) conventional methods use surface form similarity metrics (token match, exact match, etc.) which have numerous limitations, 2) execution-based evaluation focuses more on code functionality based on pass/fail judgments for given test-cases, and 3) LLM-as-a-Judge employs LLMs for automated evaluation to judge if it is a correct answer for a given problem based on pre-defined metrics. In this work, we focused on enhancing LLM-as-a-Judge using bidirectional functionality matching and logic representation for reference-less automatic validation and refinement for Bash code generation to select the best model for automatic incident remediation in IT Automation. We used execution-based evaluation as ground-truth to evaluate our LLM-as-a-Judge metrics. Results show high accuracy and agreement with execution-based evaluation (and up to 8% over baseline). Finally, we built Reflection code agents to utilize judgments and feedback from our evaluation metrics which achieved significant improvement (up to 24% increase in accuracy) for automatic code refinement.
CodeSift: An LLM-Based Reference-Less Framework for Automatic Code Validation
Aug 28, 2024



The advent of large language models (LLMs) has greatly facilitated code generation, but ensuring the functional correctness of generated code remains a challenge. Traditional validation methods are often time-consuming, error-prone, and impractical for large volumes of code. We introduce CodeSift, a novel framework that leverages LLMs as the first-line filter of code validation without the need for execution, reference code, or human feedback, thereby reducing the validation effort. We assess the effectiveness of our method across three diverse datasets encompassing two programming languages. Our results indicate that CodeSift outperforms state-of-the-art code evaluation methods. Internal testing conducted with subject matter experts reveals that the output generated by CodeSift is in line with human preference, reinforcing its effectiveness as a dependable automated code validation tool.
Tackling Execution-Based Evaluation for NL2Bash
May 10, 2024
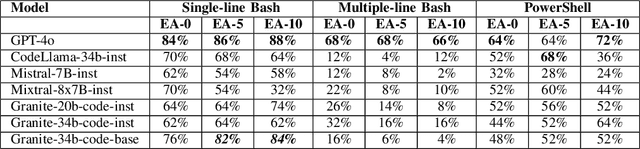


Given recent advancement of Large Language Models (LLMs), the task of translating from natural language prompts to different programming languages (code generation) attracts immense attention for wide application in different domains. Specially code generation for Bash (NL2Bash) is widely used to generate Bash scripts for automating different tasks, such as performance monitoring, compilation, system administration, system diagnostics, etc. Besides code generation, validating synthetic code is critical before using them for any application. Different methods for code validation are proposed, both direct (execution evaluation) and indirect validations (i.e. exact/partial match, BLEU score). Among these, Execution-based Evaluation (EE) can validate the predicted code by comparing the execution output of model prediction and expected output in system. However, designing and implementing such an execution-based evaluation system for NL2Bash is not a trivial task. In this paper, we present a machinery for execution-based evaluation for NL2Bash. We create a set of 50 prompts to evaluate some popular LLMs for NL2Bash. We also analyze several advantages and challenges of EE such as syntactically different yet semantically equivalent Bash scripts generated by different LLMs, or syntactically correct but semantically incorrect Bash scripts, and how we capture and process them correctly.