 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks
Feb 07, 2025



Realizing the vision of using AI agents to automate critical IT tasks depends on the ability to measure and understand effectiveness of proposed solutions. We introduce ITBench, a framework that offers a systematic methodology for benchmarking AI agents to address real-world IT automation tasks. Our initial release targets three key areas: Site Reliability Engineering (SRE), Compliance and Security Operations (CISO), and Financial Operations (FinOps). The design enables AI researchers to understand the challenges and opportunities of AI agents for IT automation with push-button workflows and interpretable metrics. ITBench includes an initial set of 94 real-world scenarios, which can be easily extended by community contributions. Our results show that agents powered by state-of-the-art models resolve only 13.8% of SRE scenarios, 25.2% of CISO scenarios, and 0% of FinOps scenarios. We expect ITBench to be a key enabler of AI-driven IT automation that is correct, safe, and fast.
CodeSift: An LLM-Based Reference-Less Framework for Automatic Code Validation
Aug 28, 2024



The advent of large language models (LLMs) has greatly facilitated code generation, but ensuring the functional correctness of generated code remains a challenge. Traditional validation methods are often time-consuming, error-prone, and impractical for large volumes of code. We introduce CodeSift, a novel framework that leverages LLMs as the first-line filter of code validation without the need for execution, reference code, or human feedback, thereby reducing the validation effort. We assess the effectiveness of our method across three diverse datasets encompassing two programming languages. Our results indicate that CodeSift outperforms state-of-the-art code evaluation methods. Internal testing conducted with subject matter experts reveals that the output generated by CodeSift is in line with human preference, reinforcing its effectiveness as a dependable automated code validation tool.
Incorporating Customer Reviews in Size and Fit Recommendation systems for Fashion E-Commerce
Aug 11, 2022


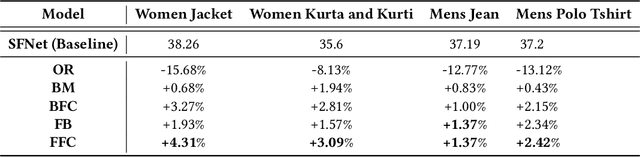
With the huge growth in e-commerce domain, product recommendations have become an increasing field of interest amongst e-commerce companies. One of the more difficult tasks in product recommendations is size and fit predictions. There are a lot of size related returns and refunds in e-fashion domain which causes inconvenience to the customers as well as costs the company. Thus having a good size and fit recommendation system, which can predict the correct sizes for the customers will not only reduce size related returns and refunds but also improve customer experience. Early works in this field used traditional machine learning approaches to estimate customer and product sizes from purchase history. These methods suffered from cold start problem due to huge sparsity in the customer-product data. More recently, people have used deep learning to address this problem by embedding customer and product features. But none of them incorporates valuable customer feedback present on product pages along with the customer and product features. We propose a novel approach which can use information from customer reviews along with customer and product features for size and fit predictions. We demonstrate the effectiveness of our approach compared to using just product and customer features on 4 datasets. Our method shows an improvement of 1.37% - 4.31% in F1 (macro) score over the baseline across the 4 different datasets.
A Weakly Supervised Model for Solving Math word Problems
Apr 14, 2021
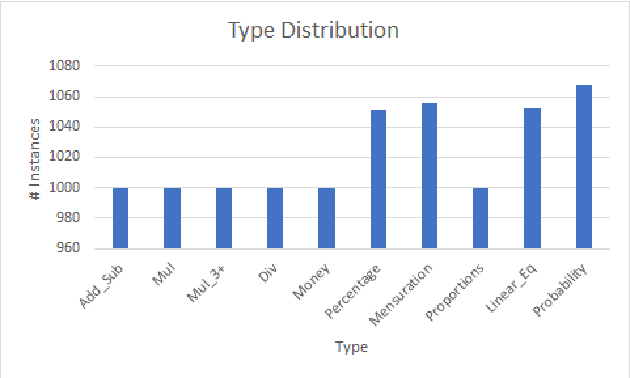
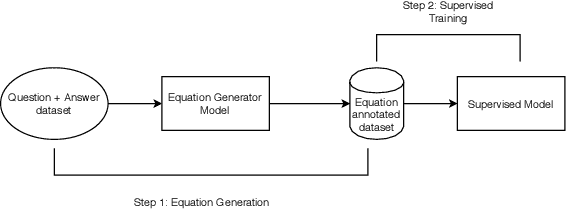
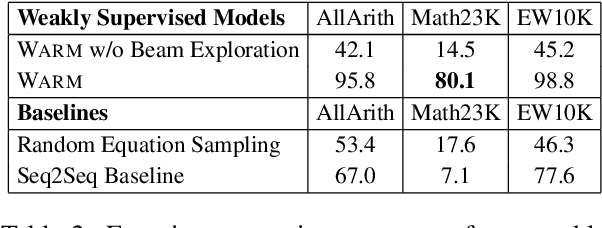
Solving math word problems (MWPs) is an important and challenging problem in natural language processing. Existing approaches to solve MWPs require full supervision in the form of intermediate equations. However, labeling every math word problem with its corresponding equations is a time-consuming and expensive task. In order to address this challenge of equation annotation, we propose a weakly supervised model for solving math word problems by requiring only the final answer as supervision. We approach this problem by first learning to generate the equation using the problem description and the final answer, which we then use to train a supervised MWP solver. We propose and compare various weakly supervised techniques to learn to generate equations directly from the problem description and answer. Through extensive experiment, we demonstrate that even without using equations for supervision, our approach achieves an accuracy of 56.0 on the standard Math23K dataset. We also curate and release a new dataset for MWPs in English consisting of 10227 instances suitable for training weakly supervised models.
Data Programming using Semi-Supervision and Subset Selection
Aug 22, 2020
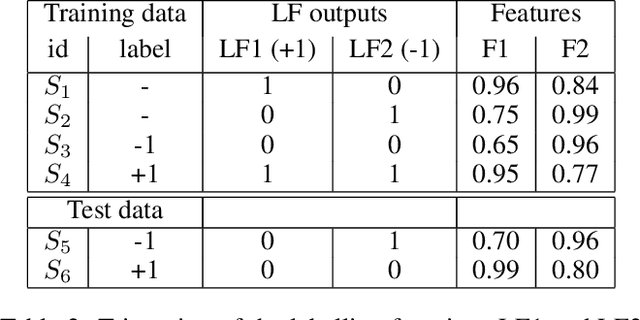
The paradigm of data programming~\cite{bach2019snorkel} has shown a lot of promise in using weak supervision in the form of rules and labelling functions to learn in scenarios where labelled data is not available. Another approach which has shown a lot of promise is that of semi-supervised learning where we augment small amounts of labelled data with a large unlabelled dataset. In this work, we argue that by not using any labelled data, data programming based approaches can yield sub-optimal performance, particularly, in cases when the labelling functions are noisy. The first contribution of this work is to study a framework of joint learning which combines un-supervised consensus from labelling functions with semi-supervised learning and \emph{jointly learns a model} to efficiently use the rules/labelling functions along with semi-supervised loss functions on the feature space. Next, we also study a subset selection approach to \emph{select} the set of examples which can be used as the labelled set. We evaluate our techniques on synthetic data as well as four publicly available datasets and show improvement over state-of-the-art techniques\footnote{Source code of the paper at \url{https://github.com/ayushbits/Semi-Supervised-LFs-Subset-Selection}}.
Data Programming using Continuous and Quality-Guided Labeling Functions
Nov 22, 2019
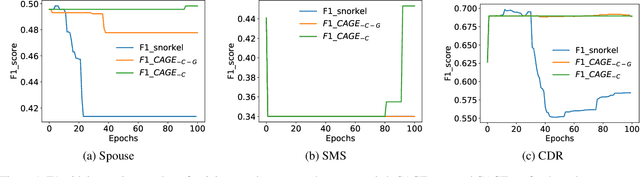

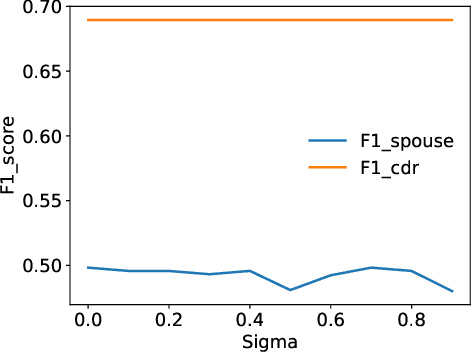
Scarcity of labeled data is a bottleneck for supervised learning models. A paradigm that has evolved for dealing with this problem is data programming. An existing data programming paradigm allows human supervision to be provided as a set of discrete labeling functions (LF) that output possibly noisy labels to input instances and a generative modelfor consolidating the weak labels. We enhance and generalize this paradigm by supporting functions that output a continuous score (instead of a hard label) that noisily correlates with labels. We show across five applications that continuous LFs are more natural to program and lead to improved recall. We also show that accuracy of existing generative models is unstable with respect to initialization, training epochs, and learning rates. We give control to the data programmer to guide the training process by providing intuitive quality guides with each LF. We propose an elegant method of incorporating these guides into the generative model. Our overall method, called CAGE, makes the data programming paradigm more reliable than other tricks based on initialization, sign-penalties, or soft-accuracy constraints.