 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Granular Multimodal Clue Fusion for Meme Understanding
Mar 16, 2025With the continuous emergence of various social media platforms frequently used in daily life, the multimodal meme understanding (MMU) task has been garnering increasing attention. MMU aims to explore and comprehend the meanings of memes from various perspectives by performing tasks such as metaphor recognition, sentiment analysis, intention detection, and offensiveness detection. Despite making progress, limitations persist due to the loss of fine-grained metaphorical visual clue and the neglect of multimodal text-image weak correlation. To overcome these limitations, we propose a multi-granular multimodal clue fusion model (MGMCF) to advance MMU. Firstly, we design an object-level semantic mining module to extract object-level image feature clues, achieving fine-grained feature clue extraction and enhancing the model's ability to capture metaphorical details and semantics. Secondly, we propose a brand-new global-local cross-modal interaction model to address the weak correlation between text and images. This model facilitates effective interaction between global multimodal contextual clues and local unimodal feature clues, strengthening their representations through a bidirectional cross-modal attention mechanism. Finally, we devise a dual-semantic guided training strategy to enhance the model's understanding and alignment of multimodal representations in the semantic space. Experiments conducted on the widely-used MET-MEME bilingual dataset demonstrate significant improvements over state-of-the-art baselines. Specifically, there is an 8.14% increase in precision for offensiveness detection task, and respective accuracy enhancements of 3.53%, 3.89%, and 3.52% for metaphor recognition, sentiment analysis, and intention detection tasks. These results, underpinned by in-depth analyses, underscore the effectiveness and potential of our approach for advancing MMU.
ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks
Feb 07, 2025



Realizing the vision of using AI agents to automate critical IT tasks depends on the ability to measure and understand effectiveness of proposed solutions. We introduce ITBench, a framework that offers a systematic methodology for benchmarking AI agents to address real-world IT automation tasks. Our initial release targets three key areas: Site Reliability Engineering (SRE), Compliance and Security Operations (CISO), and Financial Operations (FinOps). The design enables AI researchers to understand the challenges and opportunities of AI agents for IT automation with push-button workflows and interpretable metrics. ITBench includes an initial set of 94 real-world scenarios, which can be easily extended by community contributions. Our results show that agents powered by state-of-the-art models resolve only 13.8% of SRE scenarios, 25.2% of CISO scenarios, and 0% of FinOps scenarios. We expect ITBench to be a key enabler of AI-driven IT automation that is correct, safe, and fast.
CodeSift: An LLM-Based Reference-Less Framework for Automatic Code Validation
Aug 28, 2024



The advent of large language models (LLMs) has greatly facilitated code generation, but ensuring the functional correctness of generated code remains a challenge. Traditional validation methods are often time-consuming, error-prone, and impractical for large volumes of code. We introduce CodeSift, a novel framework that leverages LLMs as the first-line filter of code validation without the need for execution, reference code, or human feedback, thereby reducing the validation effort. We assess the effectiveness of our method across three diverse datasets encompassing two programming languages. Our results indicate that CodeSift outperforms state-of-the-art code evaluation methods. Internal testing conducted with subject matter experts reveals that the output generated by CodeSift is in line with human preference, reinforcing its effectiveness as a dependable automated code validation tool.
Repairing Adversarial Texts through Perturbation
Dec 29, 2021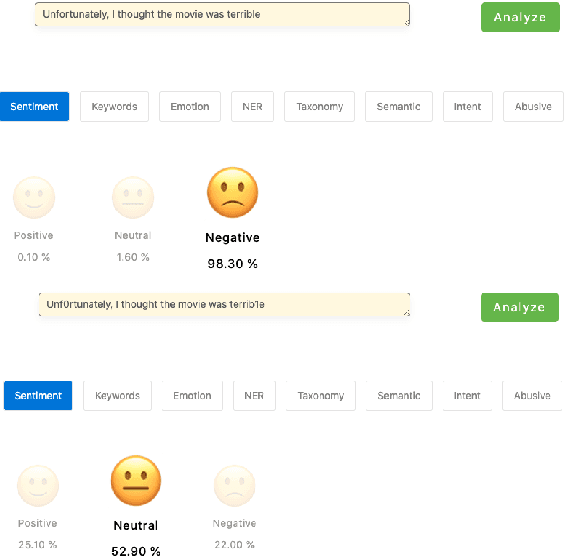
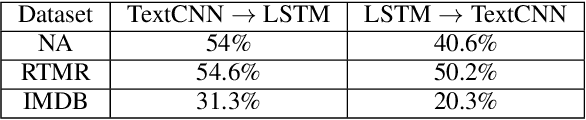
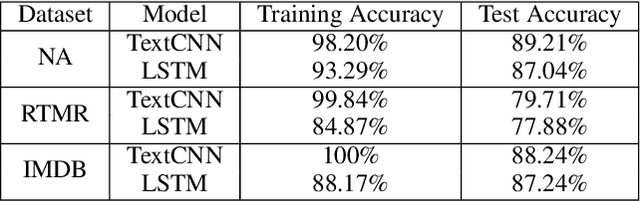
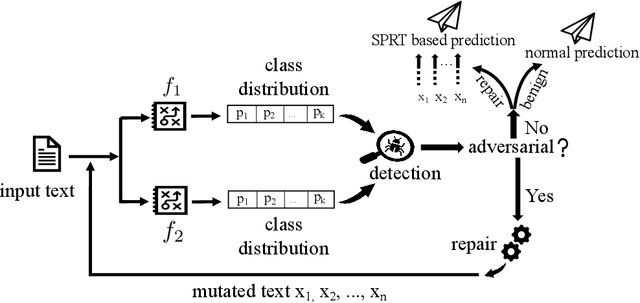
It is known that neural networks are subject to attacks through adversarial perturbations, i.e., inputs which are maliciously crafted through perturbations to induce wrong predictions. Furthermore, such attacks are impossible to eliminate, i.e., the adversarial perturbation is still possible after applying mitigation methods such as adversarial training. Multiple approaches have been developed to detect and reject such adversarial inputs, mostly in the image domain. Rejecting suspicious inputs however may not be always feasible or ideal. First, normal inputs may be rejected due to false alarms generated by the detection algorithm. Second, denial-of-service attacks may be conducted by feeding such systems with adversarial inputs. To address the gap, in this work, we propose an approach to automatically repair adversarial texts at runtime. Given a text which is suspected to be adversarial, we novelly apply multiple adversarial perturbation methods in a positive way to identify a repair, i.e., a slightly mutated but semantically equivalent text that the neural network correctly classifies. Our approach has been experimented with multiple models trained for natural language processing tasks and the results show that our approach is effective, i.e., it successfully repairs about 80\% of the adversarial texts. Furthermore, depending on the applied perturbation method, an adversarial text could be repaired in as short as one second on average.
Automatic Fairness Testing of Neural Classifiers through Adversarial Sampling
Jul 29, 2021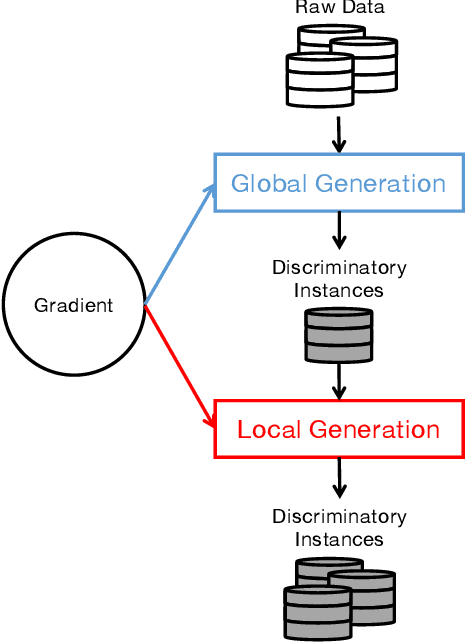

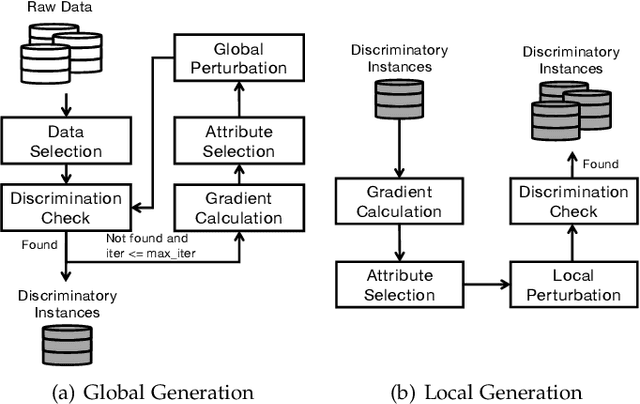
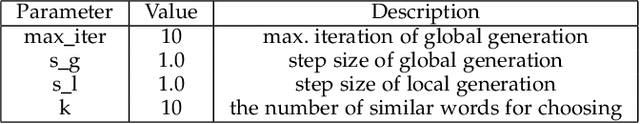
Although deep learning has demonstrated astonishing performance in many applications, there are still concerns about its dependability. One desirable property of deep learning applications with societal impact is fairness (i.e., non-discrimination). Unfortunately, discrimination might be intrinsically embedded into the models due to the discrimination in the training data. As a countermeasure, fairness testing systemically identifies discriminatory samples, which can be used to retrain the model and improve the model's fairness. Existing fairness testing approaches however have two major limitations. Firstly, they only work well on traditional machine learning models and have poor performance (e.g., effectiveness and efficiency) on deep learning models. Secondly, they only work on simple structured (e.g., tabular) data and are not applicable for domains such as text. In this work, we bridge the gap by proposing a scalable and effective approach for systematically searching for discriminatory samples while extending existing fairness testing approaches to address a more challenging domain, i.e., text classification. Compared with state-of-the-art methods, our approach only employs lightweight procedures like gradient computation and clustering, which is significantly more scalable and effective. Experimental results show that on average, our approach explores the search space much more effectively (9.62 and 2.38 times more than the state-of-the-art methods respectively on tabular and text datasets) and generates much more discriminatory samples (24.95 and 2.68 times) within a same reasonable time. Moreover, the retrained models reduce discrimination by 57.2% and 60.2% respectively on average.
Probabilistic Verification of Neural Networks Against Group Fairness
Jul 18, 2021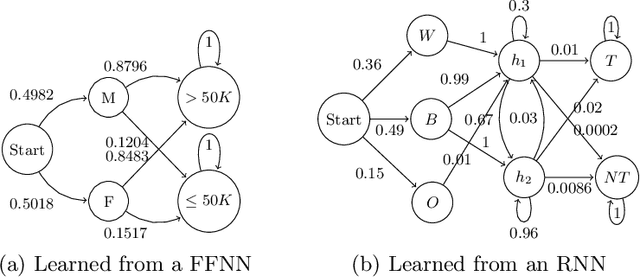
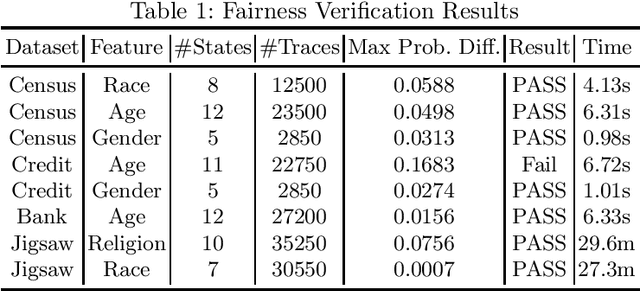

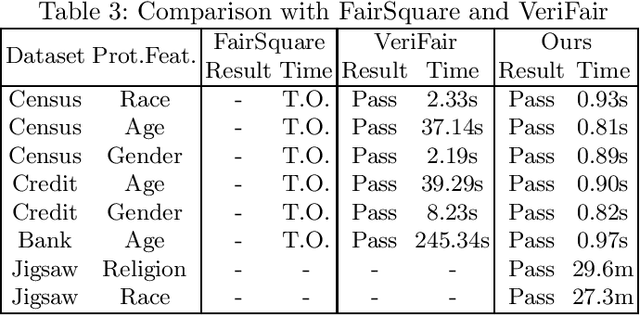
Fairness is crucial for neural networks which are used in applications with important societal implication. Recently, there have been multiple attempts on improving fairness of neural networks, with a focus on fairness testing (e.g., generating individual discriminatory instances) and fairness training (e.g., enhancing fairness through augmented training). In this work, we propose an approach to formally verify neural networks against fairness, with a focus on independence-based fairness such as group fairness. Our method is built upon an approach for learning Markov Chains from a user-provided neural network (i.e., a feed-forward neural network or a recurrent neural network) which is guaranteed to facilitate sound analysis. The learned Markov Chain not only allows us to verify (with Probably Approximate Correctness guarantee) whether the neural network is fair or not, but also facilities sensitivity analysis which helps to understand why fairness is violated. We demonstrate that with our analysis results, the neural weights can be optimized to improve fairness. Our approach has been evaluated with multiple models trained on benchmark datasets and the experiment results show that our approach is effective and efficient.
Rethinking Natural Adversarial Examples for Classification Models
Feb 23, 2021
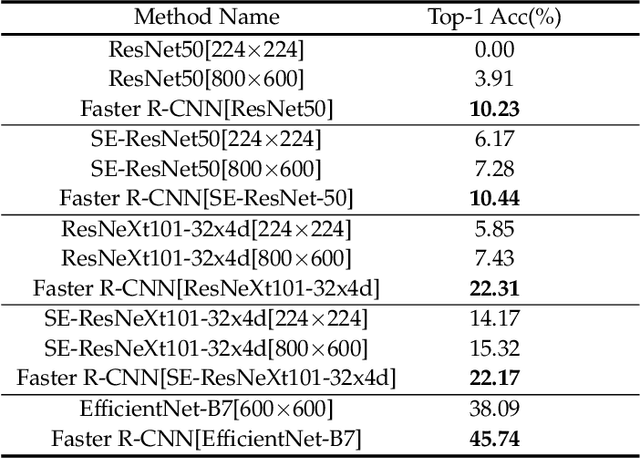


Recently, it was found that many real-world examples without intentional modifications can fool machine learning models, and such examples are called "natural adversarial examples". ImageNet-A is a famous dataset of natural adversarial examples. By analyzing this dataset, we hypothesized that large, cluttered and/or unusual background is an important reason why the images in this dataset are difficult to be classified. We validated the hypothesis by reducing the background influence in ImageNet-A examples with object detection techniques. Experiments showed that the object detection models with various classification models as backbones obtained much higher accuracy than their corresponding classification models. A detection model based on the classification model EfficientNet-B7 achieved a top-1 accuracy of 53.95%, surpassing previous state-of-the-art classification models trained on ImageNet, suggesting that accurate localization information can significantly boost the performance of classification models on ImageNet-A. We then manually cropped the objects in images from ImageNet-A and created a new dataset, named ImageNet-A-Plus. A human test on the new dataset showed that the deep learning-based classifiers still performed quite poorly compared with humans. Therefore, the new dataset can be used to study the robustness of classification models to the internal variance of objects without considering the background disturbance.
Towards Repairing Neural Networks Correctly
Dec 03, 2020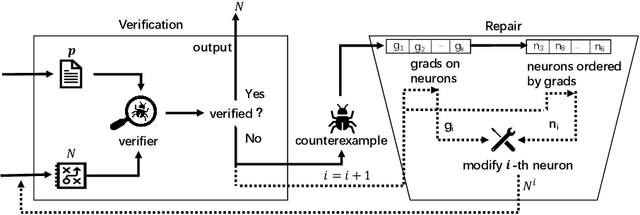
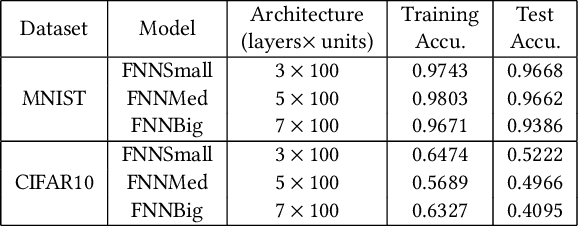
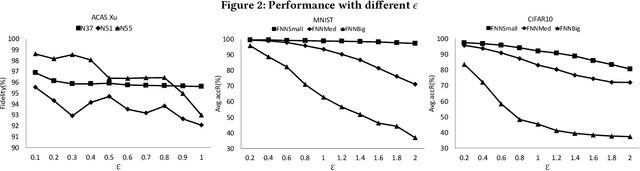
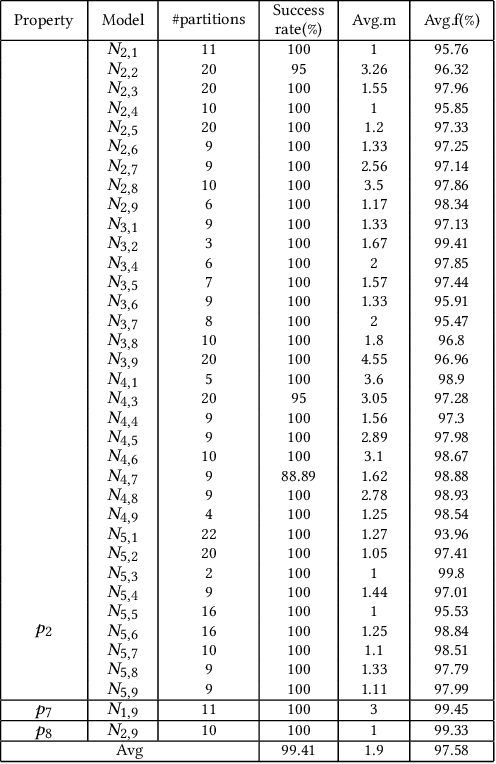
Neural networks are increasingly applied to support decision making in safety-critical applications (like autonomous cars, unmanned aerial vehicles and face recognition based authentication). While many impressive static verification techniques have been proposed to tackle the correctness problem of neural networks, it is possible that static verification may never be sufficiently scalable to handle real-world neural networks. In this work, we propose a runtime verification method to ensure the correctness of neural networks. Given a neural network and a desirable safety property, we adopt state-of-the-art static verification techniques to identify strategically locations to introduce additional gates which "correct" neural network behaviors at runtime. Experiment results show that our approach effectively generates neural networks which are guaranteed to satisfy the properties, whilst being consistent with the original neural network most of the time.
Analyzing Recurrent Neural Network by Probabilistic Abstraction
Sep 22, 2019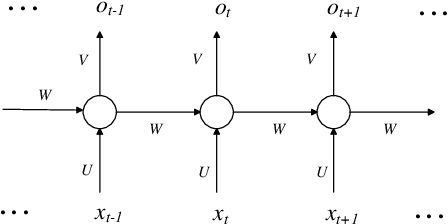

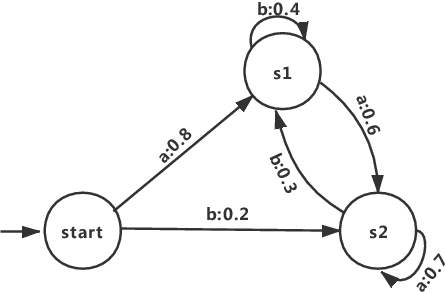
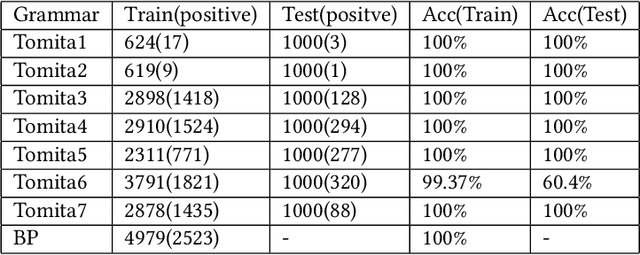
Neural network is becoming the dominant approach for solving many real-world problems like computer vision and natural language processing due to its exceptional performance as an end-to-end solution. However, deep learning models are complex and work in a black-box manner in general. This hinders humans from understanding how such systems make decisions or analyzing them using traditional software analysis techniques like testing and verification. To solve this problem and bridge the gap, several recent approaches have proposed to extract simple models in the form of finite-state automata or weighted automata for human understanding and reasoning. The results are however not encouraging due to multiple reasons like low accuracy and scalability issue. In this work, we propose to extract models in the form of probabilistic automata from recurrent neural network models instead. Our work distinguishes itself from existing approaches in two important ways. One is that we extract probabilistic models to compensate for the limited expressiveness of simple models (compared to that of deep neural networks). This is inspired by the observation that human reasoning is often `probabilistic'. The other is that we identify the right level of abstraction based on hierarchical clustering so that the models are extracted in a task-specific way. We conducted experiments on several real-world datasets using state-of-the-art RNN architectures including GRU and LSTM. The result shows that our approach improves existing model extraction approaches significantly and can produce simple models which accurately mimic the original models.