 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHInter: Exposing Hidden Intersectional Bias in Large Language Models
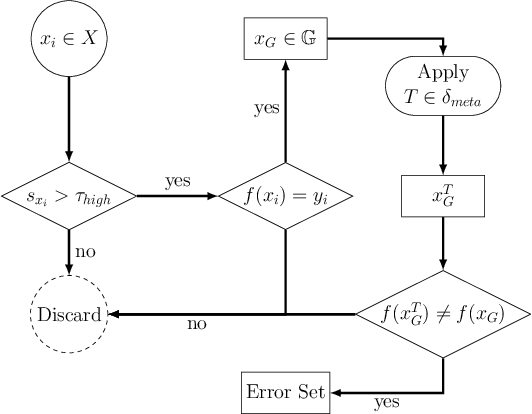
Mar 15, 2025Large Language Models (LLMs) may portray discrimination towards certain individuals, especially those characterized by multiple attributes (aka intersectional bias). Discovering intersectional bias in LLMs is challenging, as it involves complex inputs on multiple attributes (e.g. race and gender). To address this challenge, we propose HInter, a test technique that synergistically combines mutation analysis, dependency parsing and metamorphic oracles to automatically detect intersectional bias in LLMs. HInter generates test inputs by systematically mutating sentences using multiple mutations, validates inputs via a dependency invariant and detects biases by checking the LLM response on the original and mutated sentences. We evaluate HInter using six LLM architectures and 18 LLM models (GPT3.5, Llama2, BERT, etc) and find that 14.61% of the inputs generated by HInter expose intersectional bias. Results also show that our dependency invariant reduces false positives (incorrect test inputs) by an order of magnitude. Finally, we observed that 16.62% of intersectional bias errors are hidden, meaning that their corresponding atomic cases do not trigger biases. Overall, this work emphasize the importance of testing LLMs for intersectional bias.
Generative AI for Internet of Things Security: Challenges and Opportunities
Feb 13, 2025As Generative AI (GenAI) continues to gain prominence and utility across various sectors, their integration into the realm of Internet of Things (IoT) security evolves rapidly. This work delves into an examination of the state-of-the-art literature and practical applications on how GenAI could improve and be applied in the security landscape of IoT. Our investigation aims to map the current state of GenAI implementation within IoT security, exploring their potential to fortify security measures further. Through the compilation, synthesis, and analysis of the latest advancements in GenAI technologies applied to IoT, this paper not only introduces fresh insights into the field, but also lays the groundwork for future research directions. It explains the prevailing challenges within IoT security, discusses the effectiveness of GenAI in addressing these issues, and identifies significant research gaps through MITRE Mitigations. Accompanied with three case studies, we provide a comprehensive overview of the progress and future prospects of GenAI applications in IoT security. This study serves as a foundational resource to improve IoT security through the innovative application of GenAI, thus contributing to the broader discourse on IoT security and technology integration.
Distribution-aware Fairness Test Generation
May 08, 2023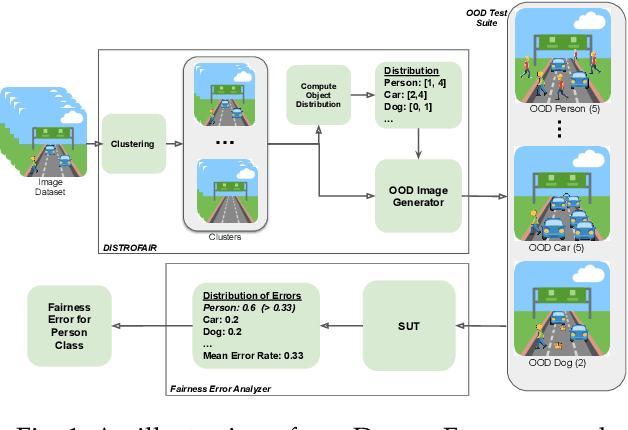

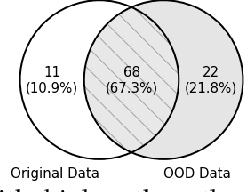

This work addresses how to validate group fairness in image recognition software. We propose a distribution-aware fairness testing approach (called DistroFair) that systematically exposes class-level fairness violations in image classifiers via a synergistic combination of out-of-distribution (OOD) testing and semantic-preserving image mutation. DistroFair automatically learns the distribution (e.g., number/orientation) of objects in a set of images. Then it systematically mutates objects in the images to become OOD using three semantic-preserving image mutations -- object deletion, object insertion and object rotation. We evaluate DistroFair using two well-known datasets (CityScapes and MS-COCO) and three major, commercial image recognition software (namely, Amazon Rekognition, Google Cloud Vision and Azure Computer Vision). Results show that about 21% of images generated by DistroFair reveal class-level fairness violations using either ground truth or metamorphic oracles. DistroFair is up to 2.3x more effective than two main baselines, i.e., (a) an approach which focuses on generating images only within the distribution (ID) and (b) fairness analysis using only the original image dataset. We further observed that DistroFair is efficient, it generates 460 images per hour, on average. Finally, we evaluate the semantic validity of our approach via a user study with 81 participants, using 30 real images and 30 corresponding mutated images generated by DistroFair. We found that images generated by DistroFair are 80% as realistic as real-world images.
Repairing Adversarial Texts through Perturbation
Dec 29, 2021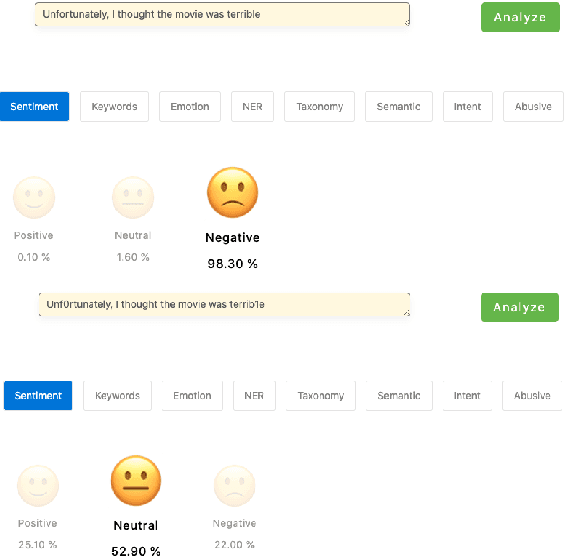
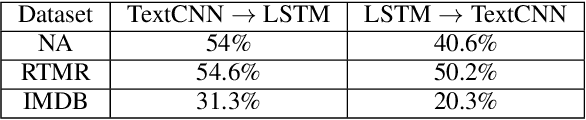
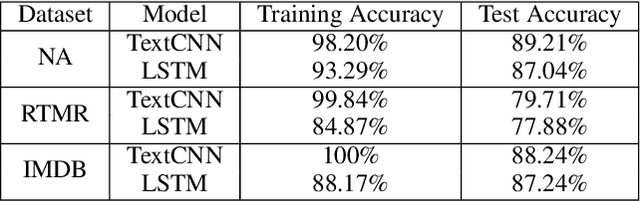
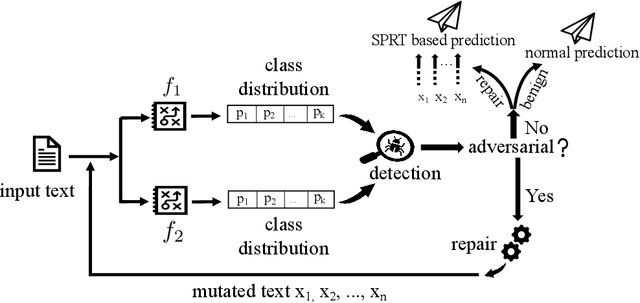
It is known that neural networks are subject to attacks through adversarial perturbations, i.e., inputs which are maliciously crafted through perturbations to induce wrong predictions. Furthermore, such attacks are impossible to eliminate, i.e., the adversarial perturbation is still possible after applying mitigation methods such as adversarial training. Multiple approaches have been developed to detect and reject such adversarial inputs, mostly in the image domain. Rejecting suspicious inputs however may not be always feasible or ideal. First, normal inputs may be rejected due to false alarms generated by the detection algorithm. Second, denial-of-service attacks may be conducted by feeding such systems with adversarial inputs. To address the gap, in this work, we propose an approach to automatically repair adversarial texts at runtime. Given a text which is suspected to be adversarial, we novelly apply multiple adversarial perturbation methods in a positive way to identify a repair, i.e., a slightly mutated but semantically equivalent text that the neural network correctly classifies. Our approach has been experimented with multiple models trained for natural language processing tasks and the results show that our approach is effective, i.e., it successfully repairs about 80\% of the adversarial texts. Furthermore, depending on the applied perturbation method, an adversarial text could be repaired in as short as one second on average.
AequeVox: Automated Fairness Testing of Speech Recognition Systems
Oct 19, 2021
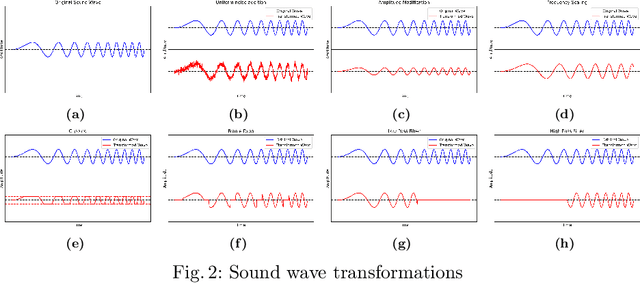

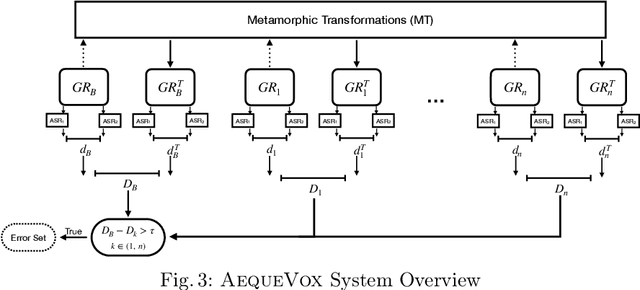
Automatic Speech Recognition (ASR) systems have become ubiquitous. They can be found in a variety of form factors and are increasingly important in our daily lives. As such, ensuring that these systems are equitable to different subgroups of the population is crucial. In this paper, we introduce, AequeVox, an automated testing framework for evaluating the fairness of ASR systems. AequeVox simulates different environments to assess the effectiveness of ASR systems for different populations. In addition, we investigate whether the chosen simulations are comprehensible to humans. We further propose a fault localization technique capable of identifying words that are not robust to these varying environments. Both components of AequeVox are able to operate in the absence of ground truth data. We evaluated AequeVox on speech from four different datasets using three different commercial ASRs. Our experiments reveal that non-native English, female and Nigerian English speakers generate 109%, 528.5% and 156.9% more errors, on average than native English, male and UK Midlands speakers, respectively. Our user study also reveals that 82.9% of the simulations (employed through speech transformations) had a comprehensibility rating above seven (out of ten), with the lowest rating being 6.78. This further validates the fairness violations discovered by AequeVox. Finally, we show that the non-robust words, as predicted by the fault localization technique embodied in AequeVox, show 223.8% more errors than the predicted robust words across all ASRs.
Adversarial Attacks and Mitigation for Anomaly Detectors of Cyber-Physical Systems
May 22, 2021
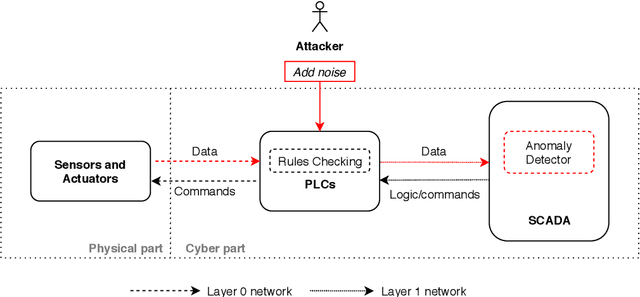

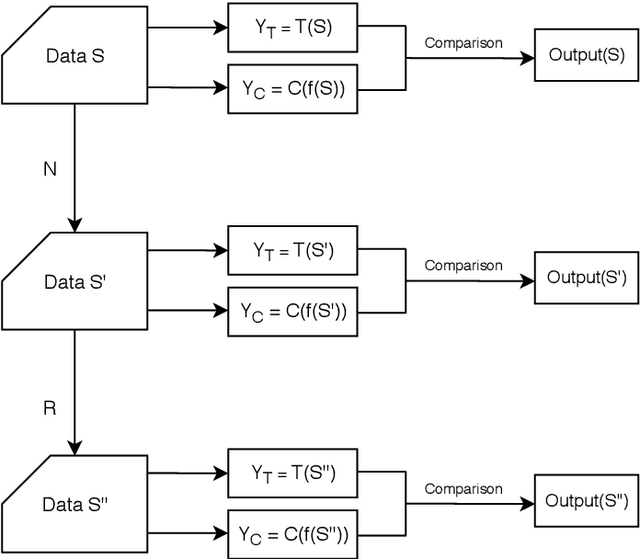
The threats faced by cyber-physical systems (CPSs) in critical infrastructure have motivated research into a multitude of attack detection mechanisms, including anomaly detectors based on neural network models. The effectiveness of anomaly detectors can be assessed by subjecting them to test suites of attacks, but less consideration has been given to adversarial attackers that craft noise specifically designed to deceive them. While successfully applied in domains such as images and audio, adversarial attacks are much harder to implement in CPSs due to the presence of other built-in defence mechanisms such as rule checkers(or invariant checkers). In this work, we present an adversarial attack that simultaneously evades the anomaly detectors and rule checkers of a CPS. Inspired by existing gradient-based approaches, our adversarial attack crafts noise over the sensor and actuator values, then uses a genetic algorithm to optimise the latter, ensuring that the neural network and the rule checking system are both deceived.We implemented our approach for two real-world critical infrastructure testbeds, successfully reducing the classification accuracy of their detectors by over 50% on average, while simultaneously avoiding detection by rule checkers. Finally, we explore whether these attacks can be mitigated by training the detectors on adversarial samples.
Astraea: Grammar-based Fairness Testing
Oct 06, 2020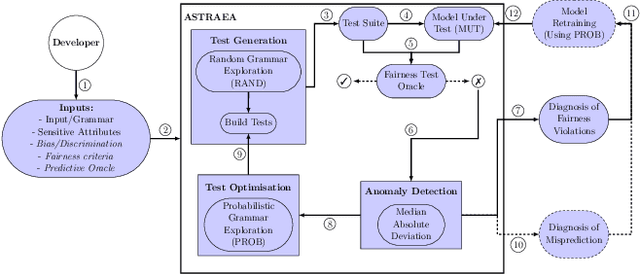

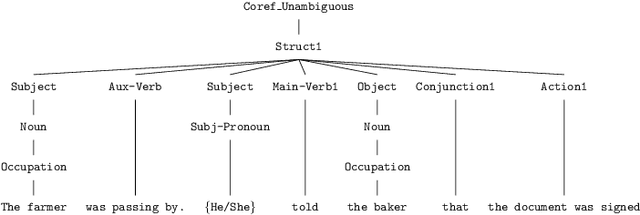

Software often produces biased outputs. In particular, machine learning (ML) based software are known to produce erroneous predictions when processing discriminatory inputs. Such unfair program behavior can be caused by societal bias. In the last few years, Amazon, Microsoft and Google have provided software services that produce unfair outputs, mostly due to societal bias (e.g. gender or race). In such events, developers are saddled with the task of conducting fairness testing. Fairness testing is challenging; developers are tasked with generating discriminatory inputs that reveal and explain biases. We propose a grammar-based fairness testing approach (called ASTRAEA) which leverages context-free grammars to generate discriminatory inputs that reveal fairness violations in software systems. Using probabilistic grammars, ASTRAEA also provides fault diagnosis by isolating the cause of observed software bias. ASTRAEA's diagnoses facilitate the improvement of ML fairness. ASTRAEA was evaluated on 18 software systems that provide three major natural language processing (NLP) services. In our evaluation, ASTRAEA generated fairness violations with a rate of ~18%. ASTRAEA generated over 573K discriminatory test cases and found over 102K fairness violations. Furthermore, ASTRAEA improves software fairness by ~76%, via model-retraining.
Securing Autonomous Service Robots through Fuzzing, Detection, and Mitigation
Mar 12, 2020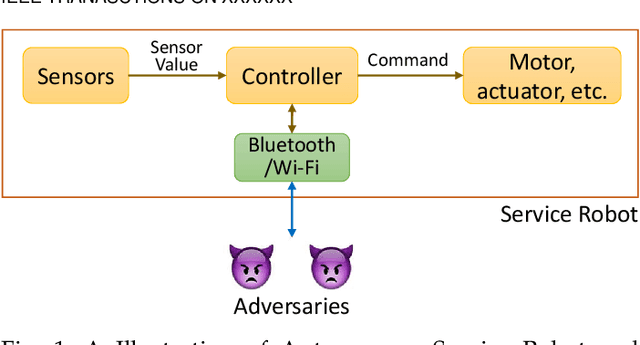
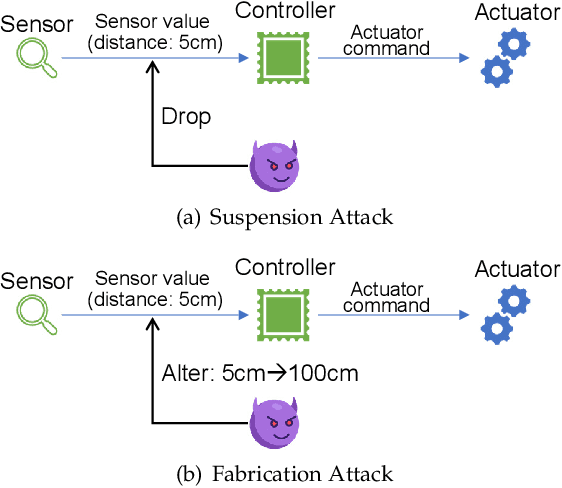


Autonomous service robots share social spaces with humans, usually working together for domestic or professional tasks. Cyber security breaches in such robots undermine the trust between humans and robots. In this paper, we investigate how to apprehend and inflict security threats at the design and implementation stage of a movable autonomous service robot. To this end, we leverage the idea of directed fuzzing and design RoboFuzz that systematically tests an autonomous service robot in line with the robot's states and the surrounding environment. The methodology of RoboFuzz is to study critical environmental parameters affecting the robot's state transitions and subject the robot control program with rational but harmful sensor values so as to compromise the robot. Furthermore, we develop detection and mitigation algorithms to counteract the impact of RoboFuzz. The difficulties mainly lie in the trade-off among limited computation resources, timely detection and the retention of work efficiency in mitigation. In particular, we propose detection and mitigation methods that take advantage of historical records of obstacles to detect inconsistent obstacle appearances regarding untrustworthy sensor values and navigate the movable robot to continue moving so as to carry on a planned task. By doing so, we manage to maintain a low cost for detection and mitigation but also retain the robot's work efficacy. We have prototyped the bundle of RoboFuzz, detection and mitigation algorithms in a real-world movable robot. Experimental results confirm that RoboFuzz makes a success rate of up to 93.3% in imposing concrete threats to the robot while the overall loss of work efficacy is merely 4.1% at the mitigation mode.
Exposing Backdoors in Robust Machine Learning Models
Feb 25, 2020


The introduction of robust optimisation has pushed the state-of-the-art in defending against adversarial attacks. However, the behaviour of such optimisation has not been studied in the light of a fundamentally different class of attacks called backdoors. In this paper, we demonstrate that adversarially robust models are susceptible to backdoor attacks. Subsequently, we observe that backdoors are reflected in the feature representation of such models. Then, this is leveraged to detect backdoor-infected models. Specifically, we use feature clustering to effectively detect backdoor-infected robust Deep Neural Networks (DNNs). In our evaluation of major classification tasks, our approach effectively detects robust DNNs infected with backdoors. Our investigation reveals that salient features of adversarially robust DNNs break the stealthy nature of backdoor attacks.
Callisto: Entropy based test generation and data quality assessment for Machine Learning Systems
Dec 11, 2019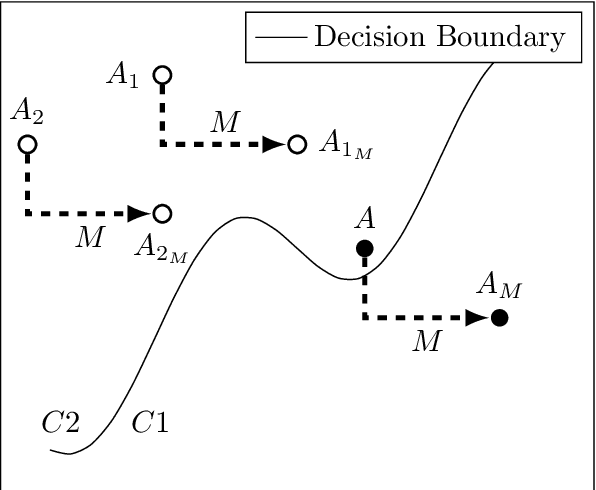

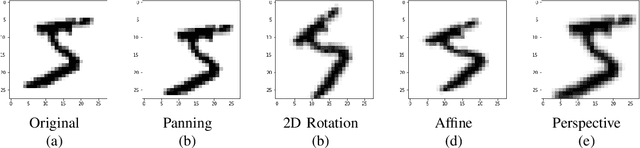
Machine Learning (ML) has seen massive progress in the last decade and as a result, there is a pressing need for validating ML-based systems. To this end, we propose, design and evaluate CALLISTO - a novel test generation and data quality assessment framework. To the best of our knowledge, CALLISTO is the first blackbox framework to leverage the uncertainty in the prediction and systematically generate new test cases for ML classifiers. Our evaluation of CALLISTO on four real world data sets reveals thousands of errors. We also show that leveraging the uncertainty in prediction can increase the number of erroneous test cases up to a factor of 20, as compared to when no such knowledge is used for testing. CALLISTO has the capability to detect low quality data in the datasets that may contain mislabelled data. We conduct and present an extensive user study to validate the results of CALLISTO on identifying low quality data from four state-of-the-art real world datasets.