 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Generalizable Multimodal Representations for Software Vulnerability Detection
Apr 28, 2026Source code and its accompanying comments are complementary yet naturally aligned modalities-code encodes structural logic while comments capture developer intent. However, existing vulnerability detection methods mostly rely on single-modality code representations, overlooking the complementary semantic information embedded in comments and thus limiting their generalization across complex code structures and logical relationships. To address this, we propose MultiVul, a multimodal contrastive framework that aligns code and comment representations through dual similarity learning and consistency regularization, augmented with diverse code-text pairs to improve robustness. Experiments on widely adopted DiverseVul and Devign datasets across four large language models (LLMs) (i.e., DeepSeek-Coder-6.7B, Qwen2.5-Coder-7B, StarCoder2-7B, and CodeLlama-7B) show that MultiVul achieves up to 27.07% F1 improvement over prompting-based methods and 13.37% over code-only Fine-Tuning, while maintaining comparable inference efficiency.
Defective Task Descriptions in LLM-Based Code Generation: Detection and Analysis
Apr 27, 2026Large language models are widely used for code generation, yet they rely on an implicit assumption that the task descriptions are sufficiently detailed and well-formed. However, in practice, users may provide defective descriptions, which can have a strong effect on code correctness. To address this issue, we develop SpecValidator, a lightweight classifier based on a small model that has been parameter-efficiently finetuned, to automatically detect task description defects. We evaluate SpecValidator on three types of defects, Lexical Vagueness, Under-Specification and Syntax-Formatting on 3 benchmarks with task descriptions of varying structure and complexity. Our results show that SpecValidator achieves defect detection of F1 = 0.804 and MCC = 0.745, significantly outperforming GPT-5-mini (F1 = 0.469 and MCC = 0.281) and Claude Sonnet 4 (F1 = 0.518 and MCC = 0.359). Perhaps more importantly, our analysis indicates that SpecValidator can generalize to unseen issues and detect unknown Under-Specification defects in the original (real) descriptions of the benchmarks used. Our results also show that the robustness of LLMs in task description defects depends primarily on the type of defect and the characteristics of the task description, rather than the capacity of the model, with Under-Specification defects being the most severe. We further found that benchmarks with richer contextual grounding, such as LiveCodeBench, exhibit substantially greater resilience, highlighting the importance of structured task descriptions for reliable LLM-based code generation.
Towards a more efficient bias detection in financial language models
Mar 09, 2026Bias in financial language models constitutes a major obstacle to their adoption in real-world applications. Detecting such bias is challenging, as it requires identifying inputs whose predictions change when varying properties unrelated to the decision, such as demographic attributes. Existing approaches typically rely on exhaustive mutation and pairwise prediction analysis over large corpora, which is effective but computationally expensive-particularly for large language models and can become impractical in continuous retraining and releasing processes. Aiming at reducing this cost, we conduct a large-scale study of bias in five financial language models, examining similarities in their bias tendencies across protected attributes and exploring cross-model-guided bias detection to identify bias-revealing inputs earlier. Our study uses approximately 17k real financial news sentences, mutated to construct over 125k original-mutant pairs. Results show that all models exhibit bias under both atomic (0.58\%-6.05\%) and intersectional (0.75\%-5.97\%) settings. Moreover, we observe consistent patterns in bias-revealing inputs across models, enabling substantial reuse and cost reduction in bias detection. For example, up to 73\% of FinMA's biased behaviours can be uncovered using only 20\% of the input pairs when guided by properties derived from DistilRoBERTa outputs.
Impact of LLMs news Sentiment Analysis on Stock Price Movement Prediction
Jan 22, 2026This paper addresses stock price movement prediction by leveraging LLM-based news sentiment analysis. Earlier works have largely focused on proposing and assessing sentiment analysis models and stock movement prediction methods, however, separately. Although promising results have been achieved, a clear and in-depth understanding of the benefit of the news sentiment to this task, as well as a comprehensive assessment of different architecture types in this context, is still lacking. Herein, we conduct an evaluation study that compares 3 different LLMs, namely, DeBERTa, RoBERTa and FinBERT, for sentiment-driven stock prediction. Our results suggest that DeBERTa outperforms the other two models with an accuracy of 75% and that an ensemble model that combines the three models can increase the accuracy to about 80%. Also, we see that sentiment news features can benefit (slightly) some stock market prediction models, i.e., LSTM-, PatchTST- and tPatchGNN-based classifiers and PatchTST- and TimesNet-based regression tasks models.
When Prompts Go Wrong: Evaluating Code Model Robustness to Ambiguous, Contradictory, and Incomplete Task Descriptions
Jul 27, 2025
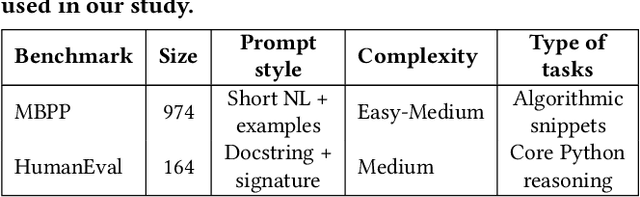
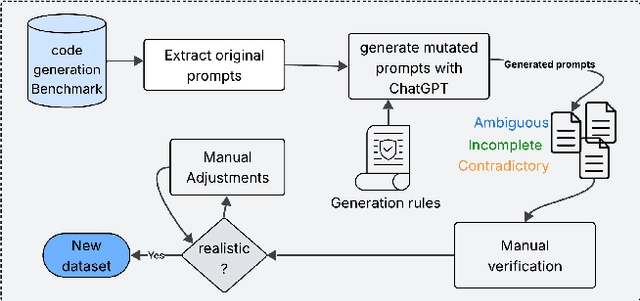
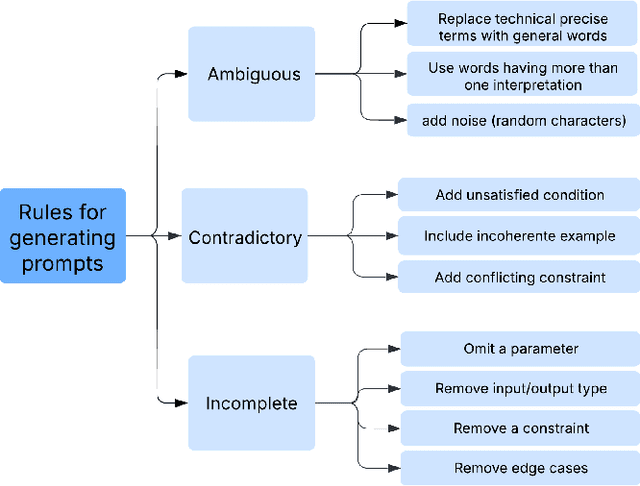
Large Language Models (LLMs) have demonstrated impressive performance in code generation tasks under idealized conditions, where task descriptions are clear and precise. However, in practice, task descriptions frequently exhibit ambiguity, incompleteness, or internal contradictions. In this paper, we present the first empirical study examining the robustness of state-of-the-art code generation models when faced with such unclear task descriptions. We extend the HumanEval and MBPP benchmarks by systematically introducing realistic task descriptions flaws through guided mutation strategies, producing a dataset that mirrors the messiness of informal developer instructions. We evaluate multiple LLMs of varying sizes and architectures, analyzing their functional correctness and failure modes across task descriptions categories. Our findings reveal that even minor imperfections in task description phrasing can cause significant performance degradation, with contradictory task descriptions resulting in numerous logical errors. Moreover, while larger models tend to be more resilient than smaller variants, they are not immune to the challenges posed by unclear requirements. We further analyze semantic error patterns and identify correlations between description clarity, model behavior, and error types. Our results underscore the critical need for developing LLMs that are not only powerful but also robust to the imperfections inherent in natural user tasks, highlighting important considerations for improving model training strategies, designing more realistic evaluation benchmarks, and ensuring reliable deployment in practical software development environments.
HInter: Exposing Hidden Intersectional Bias in Large Language Models
Mar 15, 2025Large Language Models (LLMs) may portray discrimination towards certain individuals, especially those characterized by multiple attributes (aka intersectional bias). Discovering intersectional bias in LLMs is challenging, as it involves complex inputs on multiple attributes (e.g. race and gender). To address this challenge, we propose HInter, a test technique that synergistically combines mutation analysis, dependency parsing and metamorphic oracles to automatically detect intersectional bias in LLMs. HInter generates test inputs by systematically mutating sentences using multiple mutations, validates inputs via a dependency invariant and detects biases by checking the LLM response on the original and mutated sentences. We evaluate HInter using six LLM architectures and 18 LLM models (GPT3.5, Llama2, BERT, etc) and find that 14.61% of the inputs generated by HInter expose intersectional bias. Results also show that our dependency invariant reduces false positives (incorrect test inputs) by an order of magnitude. Finally, we observed that 16.62% of intersectional bias errors are hidden, meaning that their corresponding atomic cases do not trigger biases. Overall, this work emphasize the importance of testing LLMs for intersectional bias.
Importance Guided Data Augmentation for Neural-Based Code Understanding
Feb 24, 2024Pre-trained code models lead the era of code intelligence. Many models have been designed with impressive performance recently. However, one important problem, data augmentation for code data that automatically helps developers prepare training data lacks study in the field of code learning. In this paper, we introduce a general data augmentation framework, GenCode, to enhance the training of code understanding models. GenCode follows a generation-and-selection paradigm to prepare useful training codes. Specifically, it uses code transformation techniques to generate new code candidates first and then selects important ones as the training data by importance metrics. To evaluate the effectiveness of GenCode with a general importance metric -- loss value, we conduct experiments on four code understanding tasks (e.g., code clone detection) and three pre-trained code models (e.g., CodeT5). Compared to the state-of-the-art (SOTA) code augmentation method, MixCode, GenCode produces code models with 2.92% higher accuracy and 4.90% robustness on average.
Hazards in Deep Learning Testing: Prevalence, Impact and Recommendations
Sep 11, 2023Much research on Machine Learning testing relies on empirical studies that evaluate and show their potential. However, in this context empirical results are sensitive to a number of parameters that can adversely impact the results of the experiments and potentially lead to wrong conclusions (Type I errors, i.e., incorrectly rejecting the Null Hypothesis). To this end, we survey the related literature and identify 10 commonly adopted empirical evaluation hazards that may significantly impact experimental results. We then perform a sensitivity analysis on 30 influential studies that were published in top-tier SE venues, against our hazard set and demonstrate their criticality. Our findings indicate that all 10 hazards we identify have the potential to invalidate experimental findings, such as those made by the related literature, and should be handled properly. Going a step further, we propose a point set of 10 good empirical practices that has the potential to mitigate the impact of the hazards. We believe our work forms the first step towards raising awareness of the common pitfalls and good practices within the software engineering community and hopefully contribute towards setting particular expectations for empirical research in the field of deep learning testing.
Evaluating the Robustness of Test Selection Methods for Deep Neural Networks
Jul 29, 2023Testing deep learning-based systems is crucial but challenging due to the required time and labor for labeling collected raw data. To alleviate the labeling effort, multiple test selection methods have been proposed where only a subset of test data needs to be labeled while satisfying testing requirements. However, we observe that such methods with reported promising results are only evaluated under simple scenarios, e.g., testing on original test data. This brings a question to us: are they always reliable? In this paper, we explore when and to what extent test selection methods fail for testing. Specifically, first, we identify potential pitfalls of 11 selection methods from top-tier venues based on their construction. Second, we conduct a study on five datasets with two model architectures per dataset to empirically confirm the existence of these pitfalls. Furthermore, we demonstrate how pitfalls can break the reliability of these methods. Concretely, methods for fault detection suffer from test data that are: 1) correctly classified but uncertain, or 2) misclassified but confident. Remarkably, the test relative coverage achieved by such methods drops by up to 86.85%. On the other hand, methods for performance estimation are sensitive to the choice of intermediate-layer output. The effectiveness of such methods can be even worse than random selection when using an inappropriate layer.
Boosting Source Code Learning with Data Augmentation: An Empirical Study
Mar 13, 2023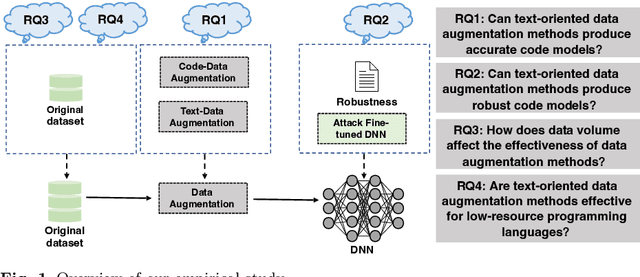
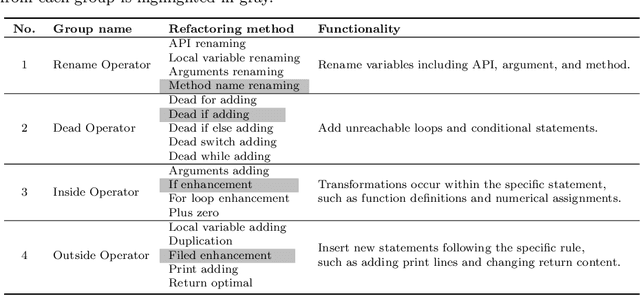
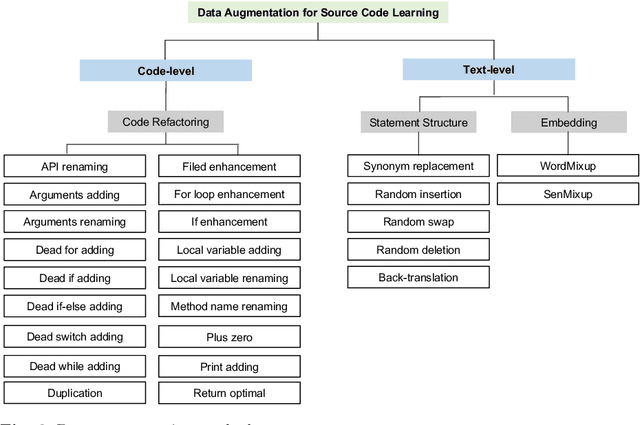
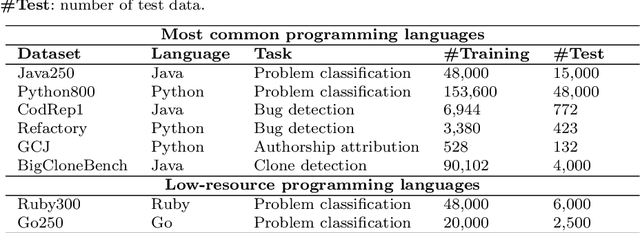
The next era of program understanding is being propelled by the use of machine learning to solve software problems. Recent studies have shown surprising results of source code learning, which applies deep neural networks (DNNs) to various critical software tasks, e.g., bug detection and clone detection. This success can be greatly attributed to the utilization of massive high-quality training data, and in practice, data augmentation, which is a technique used to produce additional training data, has been widely adopted in various domains, such as computer vision. However, in source code learning, data augmentation has not been extensively studied, and existing practice is limited to simple syntax-preserved methods, such as code refactoring. Essentially, source code is often represented in two ways, namely, sequentially as text data and structurally as graph data, when it is used as training data in source code learning. Inspired by these analogy relations, we take an early step to investigate whether data augmentation methods that are originally used for text and graphs are effective in improving the training quality of source code learning. To that end, we first collect and categorize data augmentation methods in the literature. Second, we conduct a comprehensive empirical study on four critical tasks and 11 DNN architectures to explore the effectiveness of 12 data augmentation methods (including code refactoring and 11 other methods for text and graph data). Our results identify the data augmentation methods that can produce more accurate and robust models for source code learning, including those based on mixup (e.g., SenMixup for texts and Manifold-Mixup for graphs), and those that slightly break the syntax of source code (e.g., random swap and random deletion for texts).