 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Challenges in Tabular Membership Inference Attacks
Jan 22, 2026Membership Inference Attacks (MIAs) are currently a dominant approach for evaluating privacy in machine learning applications. Despite their significance in identifying records belonging to the training dataset, several concerns remain unexplored, particularly with regard to tabular data. In this paper, first, we provide an extensive review and analysis of MIAs considering two main learning paradigms: centralized and federated learning. We extend and refine the taxonomy for both. Second, we demonstrate the efficacy of MIAs in tabular data using several attack strategies, also including defenses. Furthermore, in a federated learning scenario, we consider the threat posed by an outsider adversary, which is often neglected. Third, we demonstrate the high vulnerability of single-outs (records with a unique signature) to MIAs. Lastly, we explore how MIAs transfer across model architectures. Our results point towards a general poor performance of these attacks in tabular data which contrasts with previous state-of-the-art. Notably, even attacks with limited attack performance can still successfully expose a large portion of single-outs. Moreover, our findings suggest that using different surrogate models makes MIAs more effective.
When Prompts Go Wrong: Evaluating Code Model Robustness to Ambiguous, Contradictory, and Incomplete Task Descriptions
Jul 27, 2025
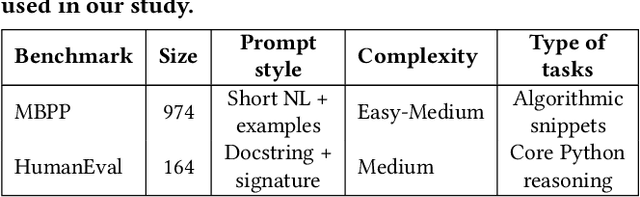
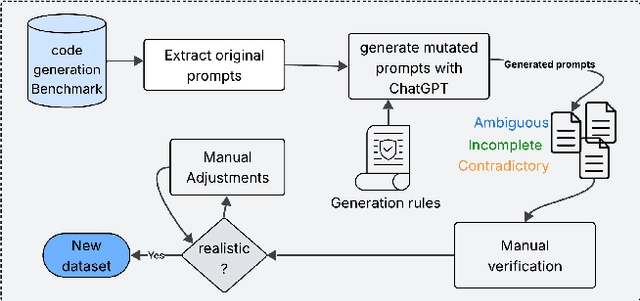
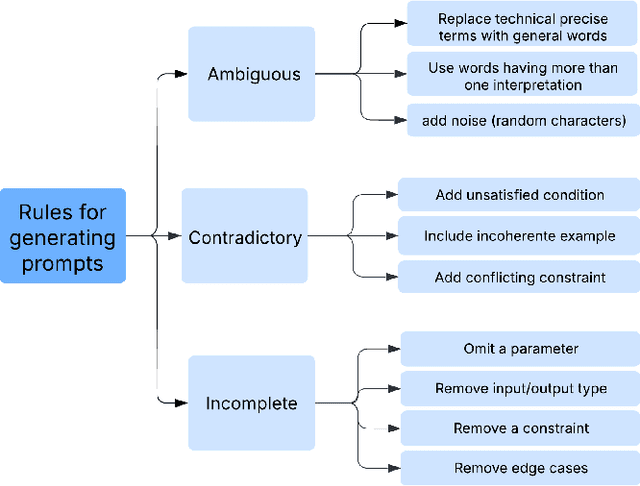
Large Language Models (LLMs) have demonstrated impressive performance in code generation tasks under idealized conditions, where task descriptions are clear and precise. However, in practice, task descriptions frequently exhibit ambiguity, incompleteness, or internal contradictions. In this paper, we present the first empirical study examining the robustness of state-of-the-art code generation models when faced with such unclear task descriptions. We extend the HumanEval and MBPP benchmarks by systematically introducing realistic task descriptions flaws through guided mutation strategies, producing a dataset that mirrors the messiness of informal developer instructions. We evaluate multiple LLMs of varying sizes and architectures, analyzing their functional correctness and failure modes across task descriptions categories. Our findings reveal that even minor imperfections in task description phrasing can cause significant performance degradation, with contradictory task descriptions resulting in numerous logical errors. Moreover, while larger models tend to be more resilient than smaller variants, they are not immune to the challenges posed by unclear requirements. We further analyze semantic error patterns and identify correlations between description clarity, model behavior, and error types. Our results underscore the critical need for developing LLMs that are not only powerful but also robust to the imperfections inherent in natural user tasks, highlighting important considerations for improving model training strategies, designing more realistic evaluation benchmarks, and ensuring reliable deployment in practical software development environments.
Insights on Adversarial Attacks for Tabular Machine Learning via a Systematic Literature Review
Jun 18, 2025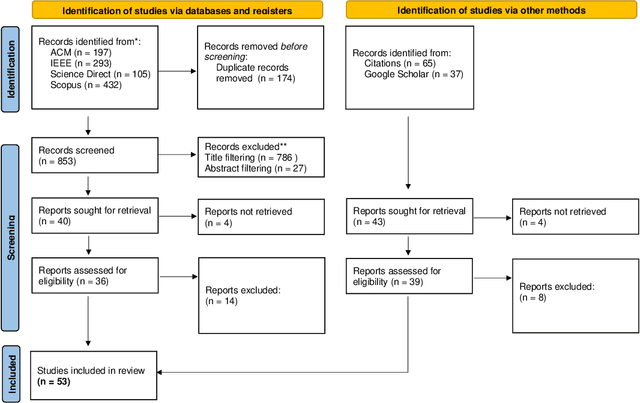
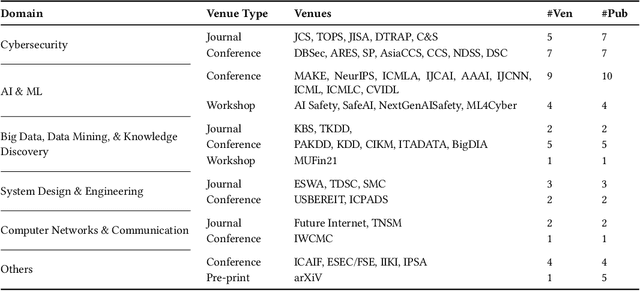
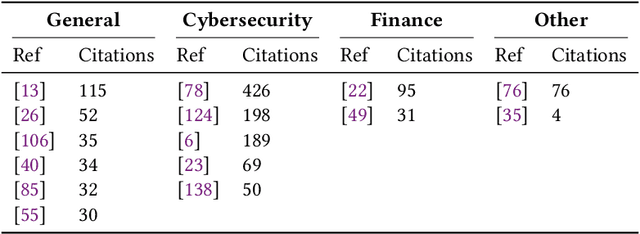
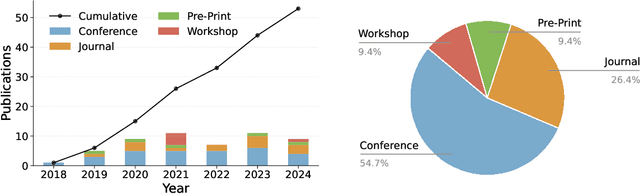
Adversarial attacks in machine learning have been extensively reviewed in areas like computer vision and NLP, but research on tabular data remains scattered. This paper provides the first systematic literature review focused on adversarial attacks targeting tabular machine learning models. We highlight key trends, categorize attack strategies and analyze how they address practical considerations for real-world applicability. Additionally, we outline current challenges and open research questions. By offering a clear and structured overview, this review aims to guide future efforts in understanding and addressing adversarial vulnerabilities in tabular machine learning.
Leveraging External Factors in Household-Level Electrical Consumption Forecasting using Hypernetworks
Jun 17, 2025Accurate electrical consumption forecasting is crucial for efficient energy management and resource allocation. While traditional time series forecasting relies on historical patterns and temporal dependencies, incorporating external factors -- such as weather indicators -- has shown significant potential for improving prediction accuracy in complex real-world applications. However, the inclusion of these additional features often degrades the performance of global predictive models trained on entire populations, despite improving individual household-level models. To address this challenge, we found that a hypernetwork architecture can effectively leverage external factors to enhance the accuracy of global electrical consumption forecasting models, by specifically adjusting the model weights to each consumer. We collected a comprehensive dataset spanning two years, comprising consumption data from over 6000 luxembourgish households and corresponding external factors such as weather indicators, holidays, and major local events. By comparing various forecasting models, we demonstrate that a hypernetwork approach outperforms existing methods when associated to external factors, reducing forecasting errors and achieving the best accuracy while maintaining the benefits of a global model.
Constraint-Guided Prediction Refinement via Deterministic Diffusion Trajectories
Jun 15, 2025Many real-world machine learning tasks require outputs that satisfy hard constraints, such as physical conservation laws, structured dependencies in graphs, or column-level relationships in tabular data. Existing approaches rely either on domain-specific architectures and losses or on strong assumptions on the constraint space, restricting their applicability to linear or convex constraints. We propose a general-purpose framework for constraint-aware refinement that leverages denoising diffusion implicit models (DDIMs). Starting from a coarse prediction, our method iteratively refines it through a deterministic diffusion trajectory guided by a learned prior and augmented by constraint gradient corrections. The approach accommodates a wide class of non-convex and nonlinear equality constraints and can be applied post hoc to any base model. We demonstrate the method in two representative domains: constrained adversarial attack generation on tabular data with column-level dependencies and in AC power flow prediction under Kirchhoff's laws. Across both settings, our diffusion-guided refinement improves both constraint satisfaction and performance while remaining lightweight and model-agnostic.
KCLNet: Physics-Informed Power Flow Prediction via Constraints Projections
Jun 15, 2025In the modern context of power systems, rapid, scalable, and physically plausible power flow predictions are essential for ensuring the grid's safe and efficient operation. While traditional numerical methods have proven robust, they require extensive computation to maintain physical fidelity under dynamic or contingency conditions. In contrast, recent advancements in artificial intelligence (AI) have significantly improved computational speed; however, they often fail to enforce fundamental physical laws during real-world contingencies, resulting in physically implausible predictions. In this work, we introduce KCLNet, a physics-informed graph neural network that incorporates Kirchhoff's Current Law as a hard constraint via hyperplane projections. KCLNet attains competitive prediction accuracy while ensuring zero KCL violations, thereby delivering reliable and physically consistent power flow predictions critical to secure the operation of modern smart grids.
TRIDENT: Temporally Restricted Inference via DFA-Enhanced Neural Traversal
Jun 11, 2025Large Language Models (LLMs) and other neural architectures have achieved impressive results across a variety of generative and classification tasks. However, they remain fundamentally ill-equipped to ensure that their outputs satisfy temporal constraints, such as those expressible in Linear Temporal Logic over finite traces (LTLf). In this paper, we introduce TRIDENT: a general and model-agnostic inference-time algorithm that guarantees compliance with such constraints without requiring any retraining. TRIDENT compiles LTLf formulas into a Deterministic Finite Automaton (DFA), which is used to guide a constrained variant of beam search. At each decoding step, transitions that would lead to constraint violations are masked, while remaining paths are dynamically re-ranked based on both the model's probabilities and the DFA's acceptance structure. We formally prove that the resulting sequences are guaranteed to satisfy the given LTLf constraints, and we empirically demonstrate that TRIDENT also improves output quality. We validate our approach on two distinct tasks: temporally constrained image-stream classification and controlled text generation. In both settings, TRIDENT achieves perfect constraint satisfaction, while comparison with the state of the art shows improved efficiency and high standard quality metrics.
SafePowerGraph-LLM: Novel Power Grid Graph Embedding and Optimization with Large Language Models
Jan 13, 2025

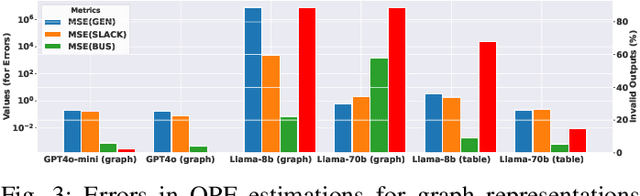

Efficiently solving Optimal Power Flow (OPF) problems in power systems is crucial for operational planning and grid management. There is a growing need for scalable algorithms capable of handling the increasing variability, constraints, and uncertainties in modern power networks while providing accurate and fast solutions. To address this, machine learning techniques, particularly Graph Neural Networks (GNNs) have emerged as promising approaches. This letter introduces SafePowerGraph-LLM, the first framework explicitly designed for solving OPF problems using Large Language Models (LLM)s. The proposed approach combines graph and tabular representations of power grids to effectively query LLMs, capturing the complex relationships and constraints in power systems. A new implementation of in-context learning and fine-tuning protocols for LLMs is introduced, tailored specifically for the OPF problem. SafePowerGraph-LLM demonstrates reliable performances using off-the-shelf LLM. Our study reveals the impact of LLM architecture, size, and fine-tuning and demonstrates our framework's ability to handle realistic grid components and constraints.
RobustBlack: Challenging Black-Box Adversarial Attacks on State-of-the-Art Defenses
Dec 30, 2024Although adversarial robustness has been extensively studied in white-box settings, recent advances in black-box attacks (including transfer- and query-based approaches) are primarily benchmarked against weak defenses, leaving a significant gap in the evaluation of their effectiveness against more recent and moderate robust models (e.g., those featured in the Robustbench leaderboard). In this paper, we question this lack of attention from black-box attacks to robust models. We establish a framework to evaluate the effectiveness of recent black-box attacks against both top-performing and standard defense mechanisms, on the ImageNet dataset. Our empirical evaluation reveals the following key findings: (1) the most advanced black-box attacks struggle to succeed even against simple adversarially trained models; (2) robust models that are optimized to withstand strong white-box attacks, such as AutoAttack, also exhibits enhanced resilience against black-box attacks; and (3) robustness alignment between the surrogate models and the target model plays a key factor in the success rate of transfer-based attacks
TabularBench: Benchmarking Adversarial Robustness for Tabular Deep Learning in Real-world Use-cases
Aug 14, 2024



While adversarial robustness in computer vision is a mature research field, fewer researchers have tackled the evasion attacks against tabular deep learning, and even fewer investigated robustification mechanisms and reliable defenses. We hypothesize that this lag in the research on tabular adversarial attacks is in part due to the lack of standardized benchmarks. To fill this gap, we propose TabularBench, the first comprehensive benchmark of robustness of tabular deep learning classification models. We evaluated adversarial robustness with CAA, an ensemble of gradient and search attacks which was recently demonstrated as the most effective attack against a tabular model. In addition to our open benchmark (https://github.com/serval-uni-lu/tabularbench) where we welcome submissions of new models and defenses, we implement 7 robustification mechanisms inspired by state-of-the-art defenses in computer vision and propose the largest benchmark of robust tabular deep learning over 200 models across five critical scenarios in finance, healthcare and security. We curated real datasets for each use case, augmented with hundreds of thousands of realistic synthetic inputs, and trained and assessed our models with and without data augmentations. We open-source our library that provides API access to all our pre-trained robust tabular models, and the largest datasets of real and synthetic tabular inputs. Finally, we analyze the impact of various defenses on the robustness and provide actionable insights to design new defenses and robustification mechanisms.