 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsights on Adversarial Attacks for Tabular Machine Learning via a Systematic Literature Review
Jun 18, 2025
Adversarial attacks in machine learning have been extensively reviewed in areas like computer vision and NLP, but research on tabular data remains scattered. This paper provides the first systematic literature review focused on adversarial attacks targeting tabular machine learning models. We highlight key trends, categorize attack strategies and analyze how they address practical considerations for real-world applicability. Additionally, we outline current challenges and open research questions. By offering a clear and structured overview, this review aims to guide future efforts in understanding and addressing adversarial vulnerabilities in tabular machine learning.
TabularBench: Benchmarking Adversarial Robustness for Tabular Deep Learning in Real-world Use-cases
Aug 14, 2024



While adversarial robustness in computer vision is a mature research field, fewer researchers have tackled the evasion attacks against tabular deep learning, and even fewer investigated robustification mechanisms and reliable defenses. We hypothesize that this lag in the research on tabular adversarial attacks is in part due to the lack of standardized benchmarks. To fill this gap, we propose TabularBench, the first comprehensive benchmark of robustness of tabular deep learning classification models. We evaluated adversarial robustness with CAA, an ensemble of gradient and search attacks which was recently demonstrated as the most effective attack against a tabular model. In addition to our open benchmark (https://github.com/serval-uni-lu/tabularbench) where we welcome submissions of new models and defenses, we implement 7 robustification mechanisms inspired by state-of-the-art defenses in computer vision and propose the largest benchmark of robust tabular deep learning over 200 models across five critical scenarios in finance, healthcare and security. We curated real datasets for each use case, augmented with hundreds of thousands of realistic synthetic inputs, and trained and assessed our models with and without data augmentations. We open-source our library that provides API access to all our pre-trained robust tabular models, and the largest datasets of real and synthetic tabular inputs. Finally, we analyze the impact of various defenses on the robustness and provide actionable insights to design new defenses and robustification mechanisms.
Constrained Adaptive Attack: Effective Adversarial Attack Against Deep Neural Networks for Tabular Data
Jun 02, 2024



State-of-the-art deep learning models for tabular data have recently achieved acceptable performance to be deployed in industrial settings. However, the robustness of these models remains scarcely explored. Contrary to computer vision, there are no effective attacks to properly evaluate the adversarial robustness of deep tabular models due to intrinsic properties of tabular data, such as categorical features, immutability, and feature relationship constraints. To fill this gap, we first propose CAPGD, a gradient attack that overcomes the failures of existing gradient attacks with adaptive mechanisms. This new attack does not require parameter tuning and further degrades the accuracy, up to 81% points compared to the previous gradient attacks. Second, we design CAA, an efficient evasion attack that combines our CAPGD attack and MOEVA, the best search-based attack. We demonstrate the effectiveness of our attacks on five architectures and four critical use cases. Our empirical study demonstrates that CAA outperforms all existing attacks in 17 over the 20 settings, and leads to a drop in the accuracy by up to 96.1% points and 21.9% points compared to CAPGD and MOEVA respectively while being up to five times faster than MOEVA. Given the effectiveness and efficiency of our new attacks, we argue that they should become the minimal test for any new defense or robust architectures in tabular machine learning.
Constrained Adaptive Attacks: Realistic Evaluation of Adversarial Examples and Robust Training of Deep Neural Networks for Tabular Data
Nov 08, 2023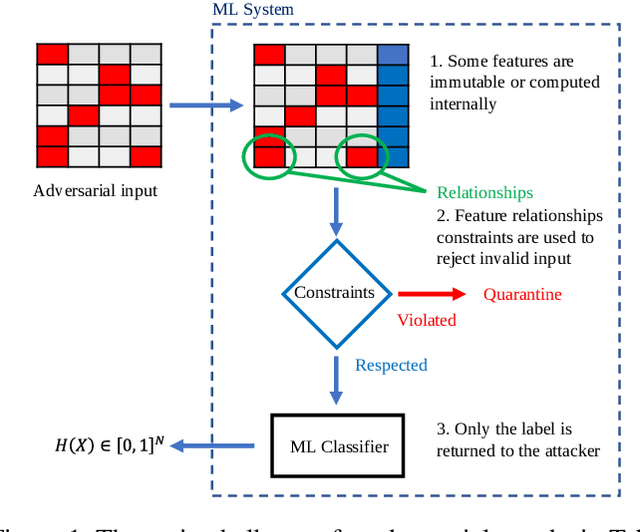



State-of-the-art deep learning models for tabular data have recently achieved acceptable performance to be deployed in industrial settings. However, the robustness of these models remains scarcely explored. Contrary to computer vision, there is to date no realistic protocol to properly evaluate the adversarial robustness of deep tabular models due to intrinsic properties of tabular data such as categorical features, immutability, and feature relationship constraints. To fill this gap, we propose CAA, the first efficient evasion attack for constrained tabular deep learning models. CAA is an iterative parameter-free attack that combines gradient and search attacks to generate adversarial examples under constraints. We leverage CAA to build a benchmark of deep tabular models across three popular use cases: credit scoring, phishing and botnet attacks detection. Our benchmark supports ten threat models with increasing capabilities of the attacker, and reflects real-world attack scenarios for each use case. Overall, our results demonstrate how domain knowledge, adversarial training, and attack budgets impact the robustness assessment of deep tabular models and provide security practitioners with a set of recommendations to improve the robustness of deep tabular models against various evasion attack scenarios.
On The Empirical Effectiveness of Unrealistic Adversarial Hardening Against Realistic Adversarial Attacks
Feb 07, 2022



While the literature on security attacks and defense of Machine Learning (ML) systems mostly focuses on unrealistic adversarial examples, recent research has raised concern about the under-explored field of realistic adversarial attacks and their implications on the robustness of real-world systems. Our paper paves the way for a better understanding of adversarial robustness against realistic attacks and makes two major contributions. First, we conduct a study on three real-world use cases (text classification, botnet detection, malware detection)) and five datasets in order to evaluate whether unrealistic adversarial examples can be used to protect models against realistic examples. Our results reveal discrepancies across the use cases, where unrealistic examples can either be as effective as the realistic ones or may offer only limited improvement. Second, to explain these results, we analyze the latent representation of the adversarial examples generated with realistic and unrealistic attacks. We shed light on the patterns that discriminate which unrealistic examples can be used for effective hardening. We release our code, datasets and models to support future research in exploring how to reduce the gap between unrealistic and realistic adversarial attacks.
A Unified Framework for Adversarial Attack and Defense in Constrained Feature Space
Dec 02, 2021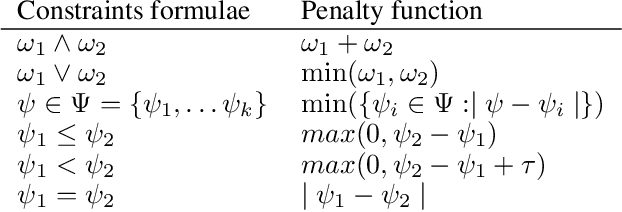
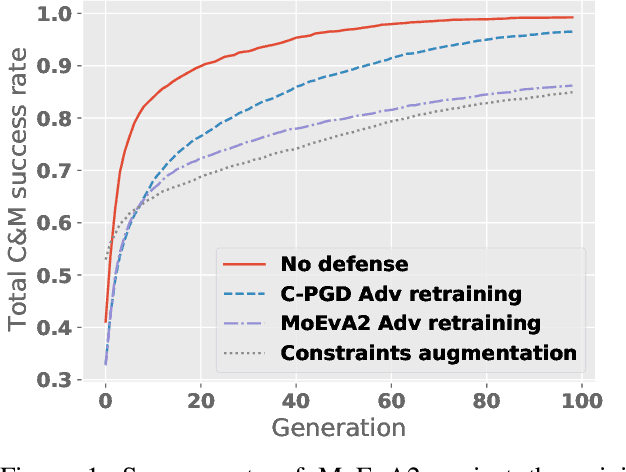
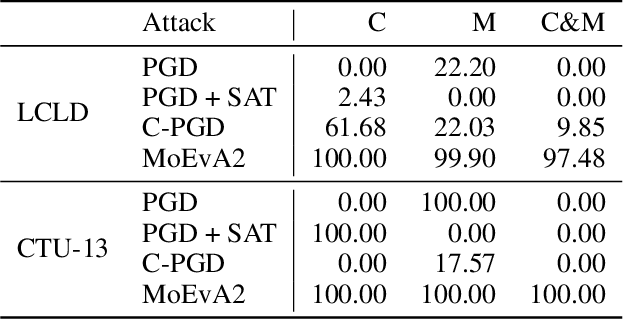
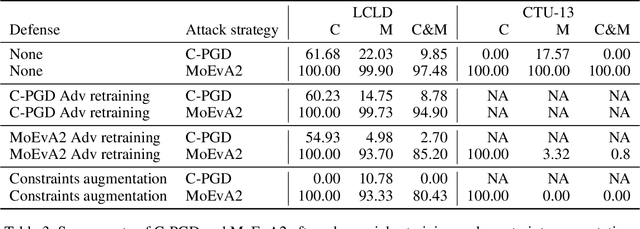
The generation of feasible adversarial examples is necessary for properly assessing models that work on constrained feature space. However, it remains a challenging task to enforce constraints into attacks that were designed for computer vision. We propose a unified framework to generate feasible adversarial examples that satisfy given domain constraints. Our framework supports the use cases reported in the literature and can handle both linear and non-linear constraints. We instantiate our framework into two algorithms: a gradient-based attack that introduces constraints in the loss function to maximize, and a multi-objective search algorithm that aims for misclassification, perturbation minimization, and constraint satisfaction. We show that our approach is effective on two datasets from different domains, with a success rate of up to 100%, where state-of-the-art attacks fail to generate a single feasible example. In addition to adversarial retraining, we propose to introduce engineered non-convex constraints to improve model adversarial robustness. We demonstrate that this new defense is as effective as adversarial retraining. Our framework forms the starting point for research on constrained adversarial attacks and provides relevant baselines and datasets that future research can exploit.