 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsights on Adversarial Attacks for Tabular Machine Learning via a Systematic Literature Review
Jun 18, 2025
Adversarial attacks in machine learning have been extensively reviewed in areas like computer vision and NLP, but research on tabular data remains scattered. This paper provides the first systematic literature review focused on adversarial attacks targeting tabular machine learning models. We highlight key trends, categorize attack strategies and analyze how they address practical considerations for real-world applicability. Additionally, we outline current challenges and open research questions. By offering a clear and structured overview, this review aims to guide future efforts in understanding and addressing adversarial vulnerabilities in tabular machine learning.
How Realistic Is Your Synthetic Data? Constraining Deep Generative Models for Tabular Data
Feb 07, 2024



Deep Generative Models (DGMs) have been shown to be powerful tools for generating tabular data, as they have been increasingly able to capture the complex distributions that characterize them. However, to generate realistic synthetic data, it is often not enough to have a good approximation of their distribution, as it also requires compliance with constraints that encode essential background knowledge on the problem at hand. In this paper, we address this limitation and show how DGMs for tabular data can be transformed into Constrained Deep Generative Models (C-DGMs), whose generated samples are guaranteed to be compliant with the given constraints. This is achieved by automatically parsing the constraints and transforming them into a Constraint Layer (CL) seamlessly integrated with the DGM. Our extensive experimental analysis with various DGMs and tasks reveals that standard DGMs often violate constraints, some exceeding $95\%$ non-compliance, while their corresponding C-DGMs are never non-compliant. Then, we quantitatively demonstrate that, at training time, C-DGMs are able to exploit the background knowledge expressed by the constraints to outperform their standard counterparts with up to $6.5\%$ improvement in utility and detection. Further, we show how our CL does not necessarily need to be integrated at training time, as it can be also used as a guardrail at inference time, still producing some improvements in the overall performance of the models. Finally, we show that our CL does not hinder the sample generation time of the models.
How do humans perceive adversarial text? A reality check on the validity and naturalness of word-based adversarial attacks
May 24, 2023



Natural Language Processing (NLP) models based on Machine Learning (ML) are susceptible to adversarial attacks -- malicious algorithms that imperceptibly modify input text to force models into making incorrect predictions. However, evaluations of these attacks ignore the property of imperceptibility or study it under limited settings. This entails that adversarial perturbations would not pass any human quality gate and do not represent real threats to human-checked NLP systems. To bypass this limitation and enable proper assessment (and later, improvement) of NLP model robustness, we have surveyed 378 human participants about the perceptibility of text adversarial examples produced by state-of-the-art methods. Our results underline that existing text attacks are impractical in real-world scenarios where humans are involved. This contrasts with previous smaller-scale human studies, which reported overly optimistic conclusions regarding attack success. Through our work, we hope to position human perceptibility as a first-class success criterion for text attacks, and provide guidance for research to build effective attack algorithms and, in turn, design appropriate defence mechanisms.
On The Empirical Effectiveness of Unrealistic Adversarial Hardening Against Realistic Adversarial Attacks
Feb 07, 2022



While the literature on security attacks and defense of Machine Learning (ML) systems mostly focuses on unrealistic adversarial examples, recent research has raised concern about the under-explored field of realistic adversarial attacks and their implications on the robustness of real-world systems. Our paper paves the way for a better understanding of adversarial robustness against realistic attacks and makes two major contributions. First, we conduct a study on three real-world use cases (text classification, botnet detection, malware detection)) and five datasets in order to evaluate whether unrealistic adversarial examples can be used to protect models against realistic examples. Our results reveal discrepancies across the use cases, where unrealistic examples can either be as effective as the realistic ones or may offer only limited improvement. Second, to explain these results, we analyze the latent representation of the adversarial examples generated with realistic and unrealistic attacks. We shed light on the patterns that discriminate which unrealistic examples can be used for effective hardening. We release our code, datasets and models to support future research in exploring how to reduce the gap between unrealistic and realistic adversarial attacks.
A Unified Framework for Adversarial Attack and Defense in Constrained Feature Space
Dec 02, 2021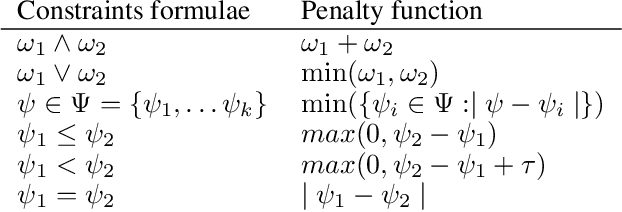
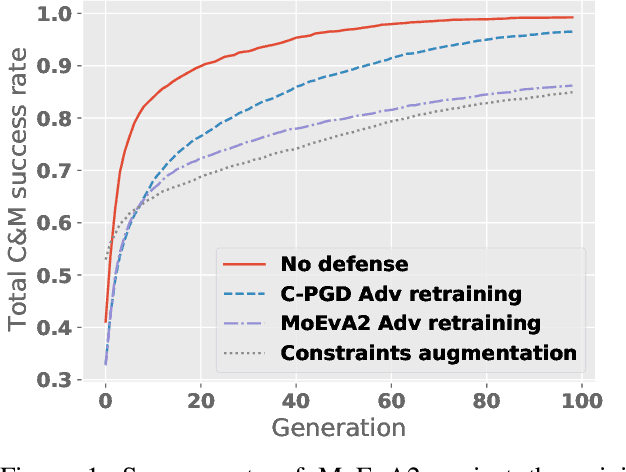
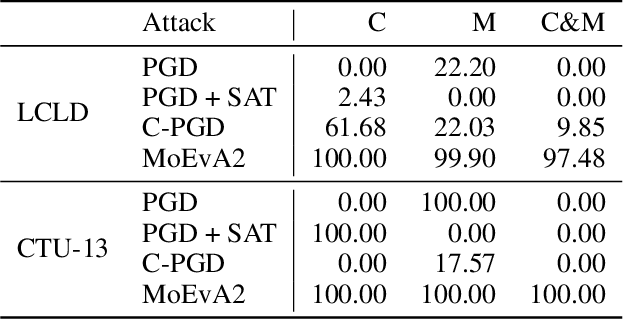
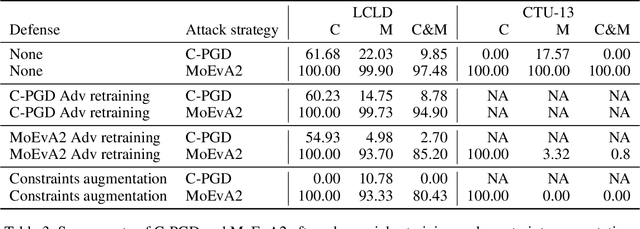
The generation of feasible adversarial examples is necessary for properly assessing models that work on constrained feature space. However, it remains a challenging task to enforce constraints into attacks that were designed for computer vision. We propose a unified framework to generate feasible adversarial examples that satisfy given domain constraints. Our framework supports the use cases reported in the literature and can handle both linear and non-linear constraints. We instantiate our framework into two algorithms: a gradient-based attack that introduces constraints in the loss function to maximize, and a multi-objective search algorithm that aims for misclassification, perturbation minimization, and constraint satisfaction. We show that our approach is effective on two datasets from different domains, with a success rate of up to 100%, where state-of-the-art attacks fail to generate a single feasible example. In addition to adversarial retraining, we propose to introduce engineered non-convex constraints to improve model adversarial robustness. We demonstrate that this new defense is as effective as adversarial retraining. Our framework forms the starting point for research on constrained adversarial attacks and provides relevant baselines and datasets that future research can exploit.