 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan I Have Your Order? Monte-Carlo Tree Search for Slot Filling Ordering in Diffusion Language Models
Feb 13, 2026While plan-and-infill decoding in Masked Diffusion Models (MDMs) shows promise for mathematical and code reasoning, performance remains highly sensitive to slot infilling order, often yielding substantial output variance. We introduce McDiffuSE, a framework that formulates slot selection as decision making and optimises infilling orders through Monte Carlo Tree Search (MCTS). McDiffuSE uses look-ahead simulations to evaluate partial completions before commitment, systematically exploring the combinatorial space of generation orders. Experiments show an average improvement of 3.2% over autoregressive baselines and 8.0% over baseline plan-and-infill, with notable gains of 19.5% on MBPP and 4.9% on MATH500. Our analysis reveals that while McDiffuSE predominantly follows sequential ordering, incorporating non-sequential generation is essential for maximising performance. We observe that larger exploration constants, rather than increased simulations, are necessary to overcome model confidence biases and discover effective orderings. These findings establish MCTS-based planning as an effective approach for enhancing generation quality in MDMs.
PiCSAR: Probabilistic Confidence Selection And Ranking
Aug 29, 2025Best-of-n sampling improves the accuracy of large language models (LLMs) and large reasoning models (LRMs) by generating multiple candidate solutions and selecting the one with the highest reward. The key challenge for reasoning tasks is designing a scoring function that can identify correct reasoning chains without access to ground-truth answers. We propose Probabilistic Confidence Selection And Ranking (PiCSAR): a simple, training-free method that scores each candidate generation using the joint log-likelihood of the reasoning and final answer. The joint log-likelihood of the reasoning and final answer naturally decomposes into reasoning confidence and answer confidence. PiCSAR achieves substantial gains across diverse benchmarks (+10.18 on MATH500, +9.81 on AIME2025), outperforming baselines with at least 2x fewer samples in 16 out of 20 comparisons. Our analysis reveals that correct reasoning chains exhibit significantly higher reasoning and answer confidence, justifying the effectiveness of PiCSAR.
TRIDENT: Temporally Restricted Inference via DFA-Enhanced Neural Traversal
Jun 11, 2025Large Language Models (LLMs) and other neural architectures have achieved impressive results across a variety of generative and classification tasks. However, they remain fundamentally ill-equipped to ensure that their outputs satisfy temporal constraints, such as those expressible in Linear Temporal Logic over finite traces (LTLf). In this paper, we introduce TRIDENT: a general and model-agnostic inference-time algorithm that guarantees compliance with such constraints without requiring any retraining. TRIDENT compiles LTLf formulas into a Deterministic Finite Automaton (DFA), which is used to guide a constrained variant of beam search. At each decoding step, transitions that would lead to constraint violations are masked, while remaining paths are dynamically re-ranked based on both the model's probabilities and the DFA's acceptance structure. We formally prove that the resulting sequences are guaranteed to satisfy the given LTLf constraints, and we empirically demonstrate that TRIDENT also improves output quality. We validate our approach on two distinct tasks: temporally constrained image-stream classification and controlled text generation. In both settings, TRIDENT achieves perfect constraint satisfaction, while comparison with the state of the art shows improved efficiency and high standard quality metrics.
A Survey on Tabular Data Generation: Utility, Alignment, Fidelity, Privacy, and Beyond
Mar 07, 2025Generative modelling has become the standard approach for synthesising tabular data. However, different use cases demand synthetic data to comply with different requirements to be useful in practice. In this survey, we review deep generative modelling approaches for tabular data from the perspective of four types of requirements: utility of the synthetic data, alignment of the synthetic data with domain-specific knowledge, statistical fidelity of the synthetic data distribution compared to the real data distribution, and privacy-preserving capabilities. We group the approaches along two levels of granularity: (i) based on the primary type of requirements they address and (ii) according to the underlying model they utilise. Additionally, we summarise the appropriate evaluation methods for each requirement and the specific characteristics of each model type. Finally, we discuss future directions for the field, along with opportunities to improve the current evaluation methods. Overall, this survey can be seen as a user guide to tabular data generation: helping readers navigate available models and evaluation methods to find those best suited to their needs.
Beyond the convexity assumption: Realistic tabular data generation under quantifier-free real linear constraints
Feb 25, 2025Synthetic tabular data generation has traditionally been a challenging problem due to the high complexity of the underlying distributions that characterise this type of data. Despite recent advances in deep generative models (DGMs), existing methods often fail to produce realistic datapoints that are well-aligned with available background knowledge. In this paper, we address this limitation by introducing Disjunctive Refinement Layer (DRL), a novel layer designed to enforce the alignment of generated data with the background knowledge specified in user-defined constraints. DRL is the first method able to automatically make deep learning models inherently compliant with constraints as expressive as quantifier-free linear formulas, which can define non-convex and even disconnected spaces. Our experimental analysis shows that DRL not only guarantees constraint satisfaction but also improves efficacy in downstream tasks. Notably, when applied to DGMs that frequently violate constraints, DRL eliminates violations entirely. Further, it improves performance metrics by up to 21.4% in F1-score and 20.9% in Area Under the ROC Curve, thus demonstrating its practical impact on data generation.
ROAD-Waymo: Action Awareness at Scale for Autonomous Driving
Nov 03, 2024

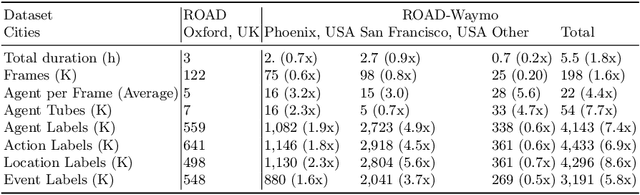
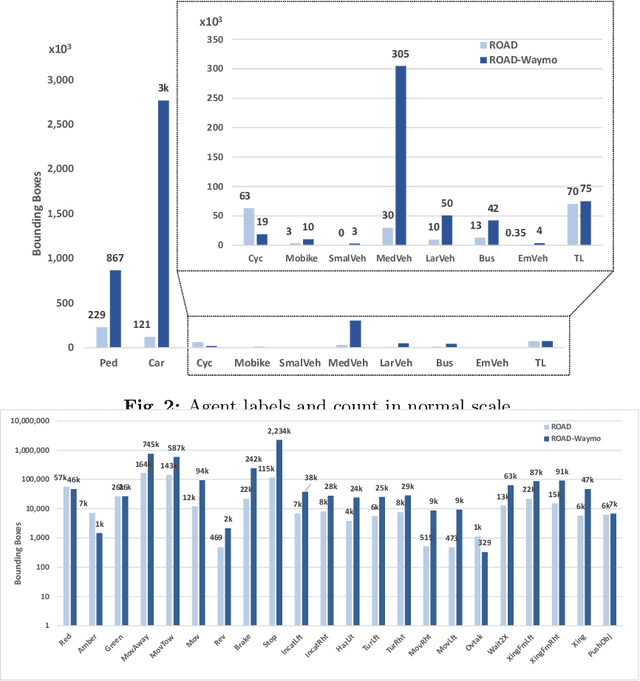
Autonomous Vehicle (AV) perception systems require more than simply seeing, via e.g., object detection or scene segmentation. They need a holistic understanding of what is happening within the scene for safe interaction with other road users. Few datasets exist for the purpose of developing and training algorithms to comprehend the actions of other road users. This paper presents ROAD-Waymo, an extensive dataset for the development and benchmarking of techniques for agent, action, location and event detection in road scenes, provided as a layer upon the (US) Waymo Open dataset. Considerably larger and more challenging than any existing dataset (and encompassing multiple cities), it comes with 198k annotated video frames, 54k agent tubes, 3.9M bounding boxes and a total of 12.4M labels. The integrity of the dataset has been confirmed and enhanced via a novel annotation pipeline designed for automatically identifying violations of requirements specifically designed for this dataset. As ROAD-Waymo is compatible with the original (UK) ROAD dataset, it provides the opportunity to tackle domain adaptation between real-world road scenarios in different countries within a novel benchmark: ROAD++.
ULLER: A Unified Language for Learning and Reasoning
May 01, 2024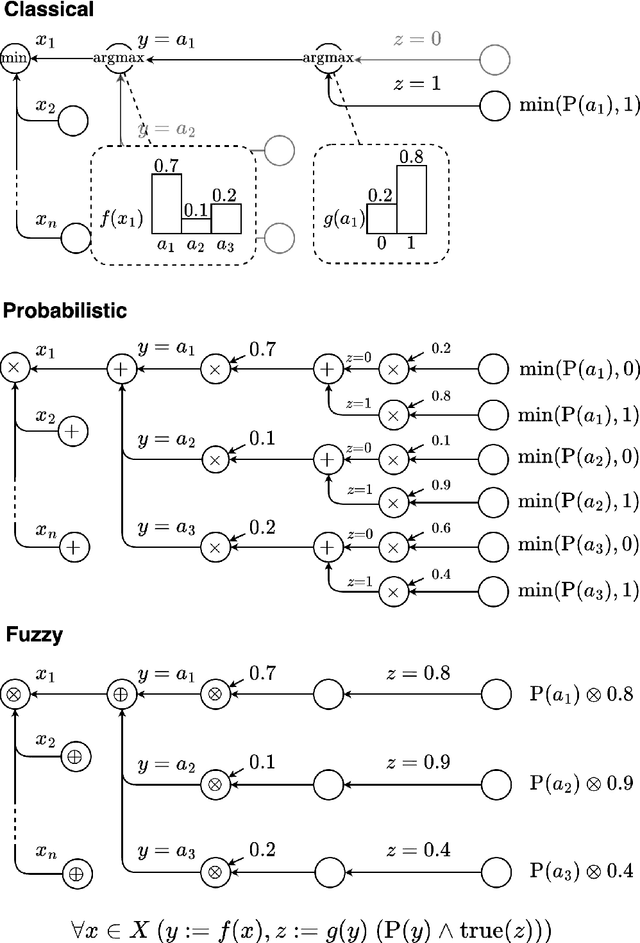
The field of neuro-symbolic artificial intelligence (NeSy), which combines learning and reasoning, has recently experienced significant growth. There now are a wide variety of NeSy frameworks, each with its own specific language for expressing background knowledge and how to relate it to neural networks. This heterogeneity hinders accessibility for newcomers and makes comparing different NeSy frameworks challenging. We propose a unified language for NeSy, which we call ULLER, a Unified Language for LEarning and Reasoning. ULLER encompasses a wide variety of settings, while ensuring that knowledge described in it can be used in existing NeSy systems. ULLER has a neuro-symbolic first-order syntax for which we provide example semantics including classical, fuzzy, and probabilistic logics. We believe ULLER is a first step towards making NeSy research more accessible and comparable, paving the way for libraries that streamline training and evaluation across a multitude of semantics, knowledge bases, and NeSy systems.
PiShield: A NeSy Framework for Learning with Requirements
Feb 28, 2024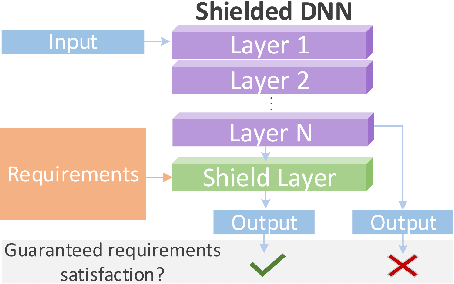
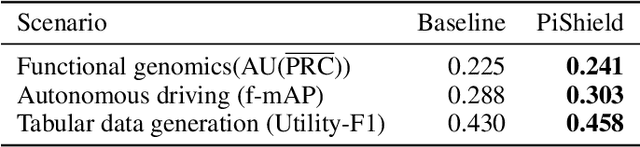

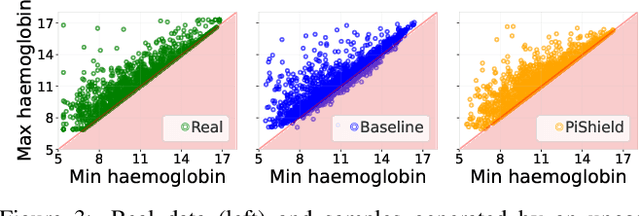
Deep learning models have shown their strengths in various application domains, however, they often struggle to meet safety requirements for their outputs. In this paper, we introduce PiShield, the first framework ever allowing for the integration of the requirements into the neural networks' topology. PiShield guarantees compliance with these requirements, regardless of input. Additionally, it allows for integrating requirements both at inference and/or training time, depending on the practitioners' needs. Given the widespread application of deep learning, there is a growing need for frameworks allowing for the integration of the requirements across various domains. Here, we explore three application scenarios: functional genomics, autonomous driving, and tabular data generation.
Exploiting T-norms for Deep Learning in Autonomous Driving
Feb 17, 2024



Deep learning has been at the core of the autonomous driving field development, due to the neural networks' success in finding patterns in raw data and turning them into accurate predictions. Moreover, recent neuro-symbolic works have shown that incorporating the available background knowledge about the problem at hand in the loss function via t-norms can further improve the deep learning models' performance. However, t-norm-based losses may have very high memory requirements and, thus, they may be impossible to apply in complex application domains like autonomous driving. In this paper, we show how it is possible to define memory-efficient t-norm-based losses, allowing for exploiting t-norms for the task of event detection in autonomous driving. We conduct an extensive experimental analysis on the ROAD-R dataset and show (i) that our proposal can be implemented and run on GPUs with less than 25 GiB of available memory, while standard t-norm-based losses are estimated to require more than 100 GiB, far exceeding the amount of memory normally available, (ii) that t-norm-based losses improve performance, especially when limited labelled data are available, and (iii) that t-norm-based losses can further improve performance when exploited on both labelled and unlabelled data.
How Realistic Is Your Synthetic Data? Constraining Deep Generative Models for Tabular Data
Feb 07, 2024



Deep Generative Models (DGMs) have been shown to be powerful tools for generating tabular data, as they have been increasingly able to capture the complex distributions that characterize them. However, to generate realistic synthetic data, it is often not enough to have a good approximation of their distribution, as it also requires compliance with constraints that encode essential background knowledge on the problem at hand. In this paper, we address this limitation and show how DGMs for tabular data can be transformed into Constrained Deep Generative Models (C-DGMs), whose generated samples are guaranteed to be compliant with the given constraints. This is achieved by automatically parsing the constraints and transforming them into a Constraint Layer (CL) seamlessly integrated with the DGM. Our extensive experimental analysis with various DGMs and tasks reveals that standard DGMs often violate constraints, some exceeding $95\%$ non-compliance, while their corresponding C-DGMs are never non-compliant. Then, we quantitatively demonstrate that, at training time, C-DGMs are able to exploit the background knowledge expressed by the constraints to outperform their standard counterparts with up to $6.5\%$ improvement in utility and detection. Further, we show how our CL does not necessarily need to be integrated at training time, as it can be also used as a guardrail at inference time, still producing some improvements in the overall performance of the models. Finally, we show that our CL does not hinder the sample generation time of the models.