 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROAD-Waymo: Action Awareness at Scale for Autonomous Driving
Nov 03, 2024

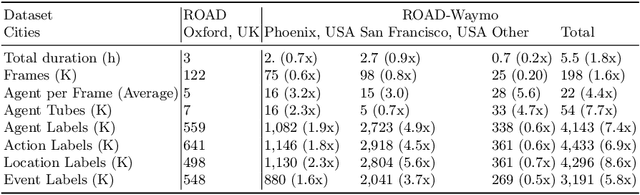
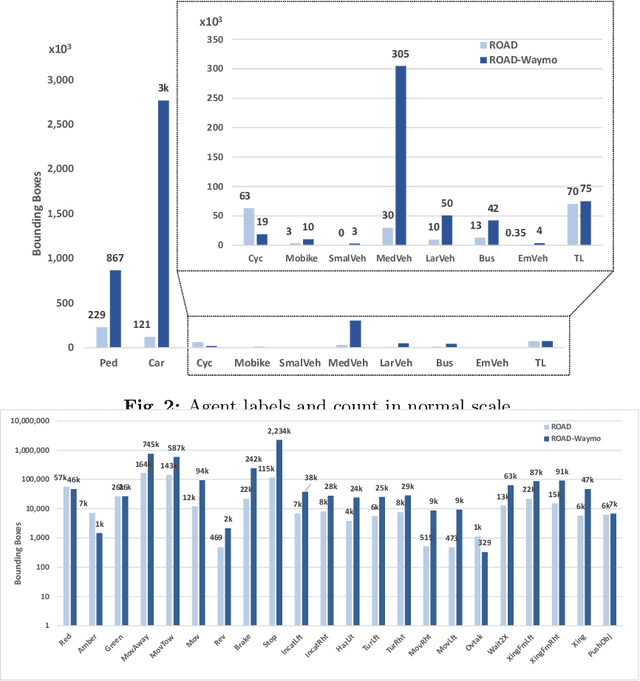
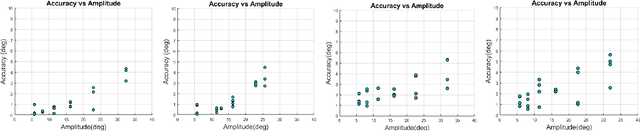
Autonomous Vehicle (AV) perception systems require more than simply seeing, via e.g., object detection or scene segmentation. They need a holistic understanding of what is happening within the scene for safe interaction with other road users. Few datasets exist for the purpose of developing and training algorithms to comprehend the actions of other road users. This paper presents ROAD-Waymo, an extensive dataset for the development and benchmarking of techniques for agent, action, location and event detection in road scenes, provided as a layer upon the (US) Waymo Open dataset. Considerably larger and more challenging than any existing dataset (and encompassing multiple cities), it comes with 198k annotated video frames, 54k agent tubes, 3.9M bounding boxes and a total of 12.4M labels. The integrity of the dataset has been confirmed and enhanced via a novel annotation pipeline designed for automatically identifying violations of requirements specifically designed for this dataset. As ROAD-Waymo is compatible with the original (UK) ROAD dataset, it provides the opportunity to tackle domain adaptation between real-world road scenarios in different countries within a novel benchmark: ROAD++.
Strategies for modelling open-loop saccade control of a cable-driven biomimetic robot eye
Mar 01, 2022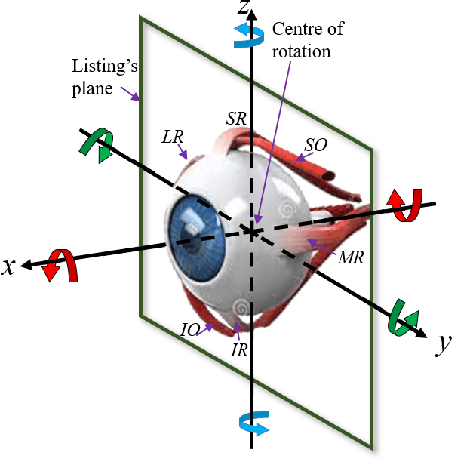
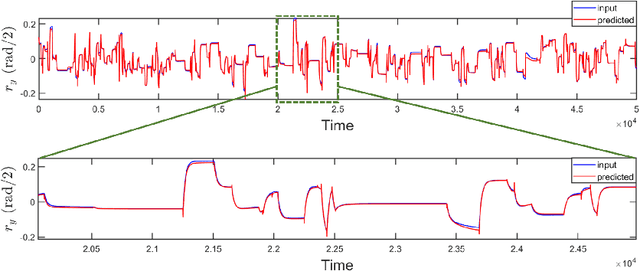

In human-robot interactions, eye movements play an important role in non-verbal communication. However, controlling the motions of a robotic eye that display similar performance as the human oculomotor system is still a major challenge. In this paper, we study how to control a realistic model of the human eye, with a cable-driven actuation system that mimicks the 6 extra-ocular muscles. We have built a robotic prototype and developed a non-linear simulation model, for which we compared different techniques to control its gaze behavior to match the main characteristics of saccade eye movements. In the first approach, we linearized the six degrees of freedom nonlinear model, using a local derivative technique, and designed linear-quadratic optimal controllers to optimize a cost function that accounts for accuracy, energy and duration. The second method learns a dynamic neural-network that matches the system dynamics, trained from sample trajectories of the system, and a non-linear trajectory optimization solver optimized a similar cost function. We focused on the generation of rapid saccadic eye movements with fully unconstrained kinematics, and the generation of control signals for the six cables that simultaneously satisfied several dynamic optimization criteria. The model faithfully mimicked the three-dimensional rotational kinematics and dynamics observed for human saccades. Our experimental results indicate that while the linear model provides a more accurate eye movement, the nonlinear model simulate eye dynamic properties in a better way faithful approximation to the properties of the human saccadic system than the linearized model, at the cost of larger training and optimization time.
ROAD: The ROad event Awareness Dataset for Autonomous Driving
Feb 25, 2021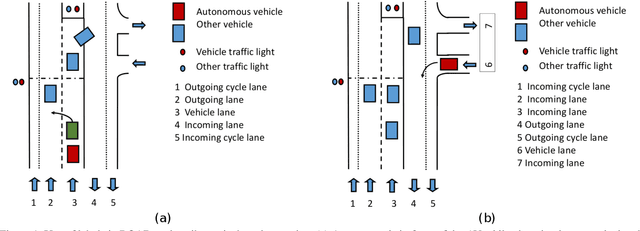

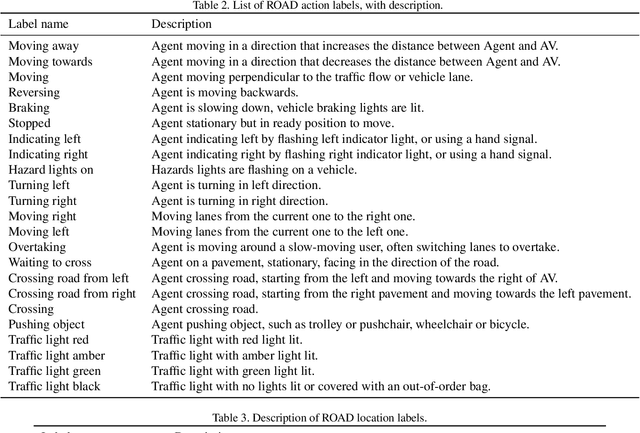

Humans approach driving in a holistic fashion which entails, in particular, understanding road events and their evolution. Injecting these capabilities in an autonomous vehicle has thus the potential to take situational awareness and decision making closer to human-level performance. To this purpose, we introduce the ROad event Awareness Dataset (ROAD) for Autonomous Driving, to our knowledge the first of its kind. ROAD is designed to test an autonomous vehicle's ability to detect road events, defined as triplets composed by a moving agent, the action(s) it performs and the corresponding scene locations. ROAD comprises 22 videos, originally from the Oxford RobotCar Dataset, annotated with bounding boxes showing the location in the image plane of each road event. We also provide as baseline a new incremental algorithm for online road event awareness, based on inflating RetinaNet along time, which achieves a mean average precision of 16.8% and 6.1% for frame-level and video-level event detection, respectively, at 50% overlap. Though promising, these figures highlight the challenges faced by situation awareness in autonomous driving. Finally, ROAD allows scholars to investigate exciting tasks such as complex (road) activity detection, future road event anticipation and the modelling of sentient road agents in terms of mental states. Dataset can be obtained from https://github.com/gurkirt/road-dataset and baseline code from https://github.com/gurkirt/3D-RetinaNet.