 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROAD-Waymo: Action Awareness at Scale for Autonomous Driving
Nov 03, 2024

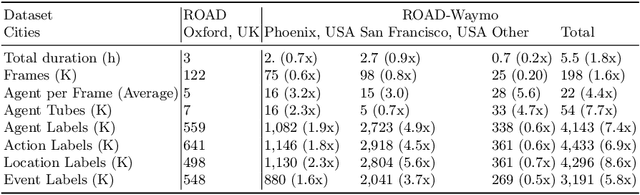
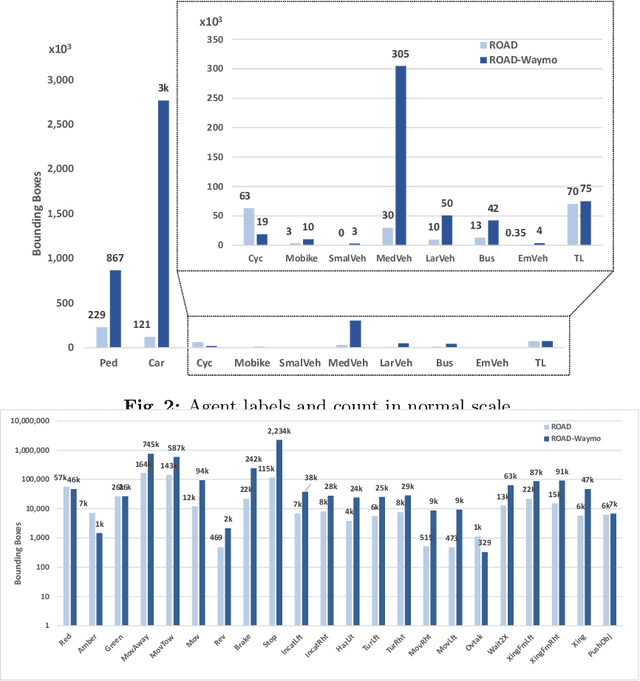
Autonomous Vehicle (AV) perception systems require more than simply seeing, via e.g., object detection or scene segmentation. They need a holistic understanding of what is happening within the scene for safe interaction with other road users. Few datasets exist for the purpose of developing and training algorithms to comprehend the actions of other road users. This paper presents ROAD-Waymo, an extensive dataset for the development and benchmarking of techniques for agent, action, location and event detection in road scenes, provided as a layer upon the (US) Waymo Open dataset. Considerably larger and more challenging than any existing dataset (and encompassing multiple cities), it comes with 198k annotated video frames, 54k agent tubes, 3.9M bounding boxes and a total of 12.4M labels. The integrity of the dataset has been confirmed and enhanced via a novel annotation pipeline designed for automatically identifying violations of requirements specifically designed for this dataset. As ROAD-Waymo is compatible with the original (UK) ROAD dataset, it provides the opportunity to tackle domain adaptation between real-world road scenarios in different countries within a novel benchmark: ROAD++.
Analyzing ASR pretraining for low-resource speech-to-text translation
Oct 23, 2019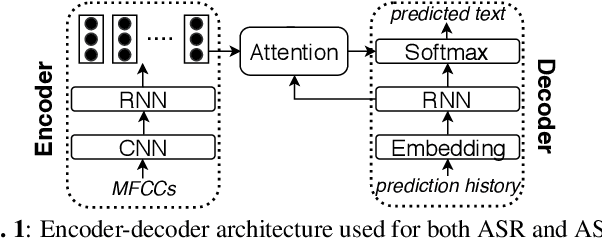
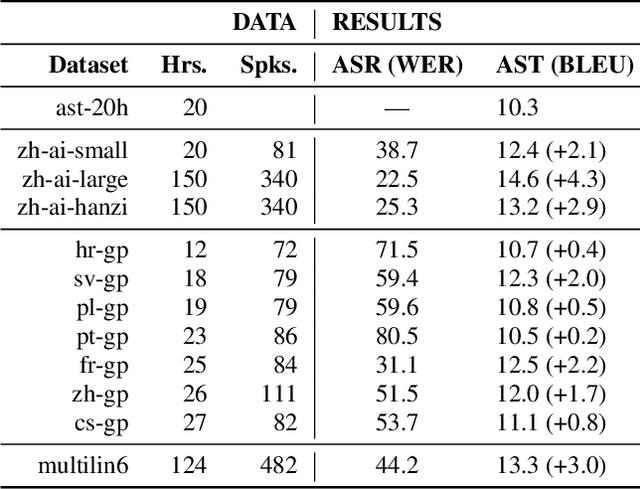
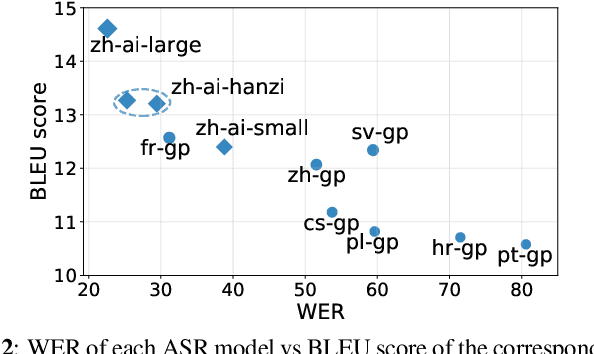
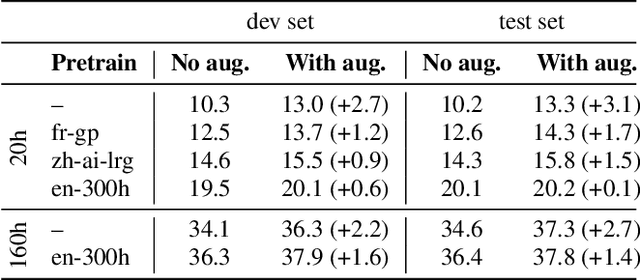
Previous work has shown that for low-resource source languages, automatic speech-to-text translation (AST) can be improved by pretraining an end-to-end model on automatic speech recognition (ASR) data from a high-resource language. However, it is not clear what factors --e.g., language relatedness or size of the pretraining data-- yield the biggest improvements, or whether pretraining can be effectively combined with other methods such as data augmentation. Here, we experiment with pretraining on datasets of varying sizes, including languages related and unrelated to the AST source language. We find that the best predictor of final AST performance is the word error rate of the pretrained ASR model, and that differences in ASR/AST performance correlate with how phonetic information is encoded in the later RNN layers of our model. We also show that pretraining and data augmentation yield complementary benefits for AST.