 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathSpace: Rapid continuous map approximation for efficient SLAM using B-Splines in constrained environments
Mar 03, 2026Simultaneous Localization and Mapping (SLAM) plays a crucial role in enabling autonomous vehicles to navigate previously unknown environments. Semantic SLAM mostly extends visual SLAM, leveraging the higher density information available to reason about the environment in a more human-like manner. This allows for better decision making by exploiting prior structural knowledge of the environment, usually in the form of labels. Current semantic SLAM techniques still mostly rely on a dense geometric representation of the environment, limiting their ability to apply constraints based on context. We propose PathSpace, a novel semantic SLAM framework that uses continuous B-splines to represent the environment in a compact manner, while also maintaining and reasoning through the continuous probability density functions required for probabilistic reasoning. This system applies the multiple strengths of B-splines in the context of SLAM to interpolate and fit otherwise discrete sparse environments. We test this framework in the context of autonomous racing, where we exploit pre-specified track characteristics to produce significantly reduced representations at comparable levels of accuracy to traditional landmark based methods and demonstrate its potential in limiting the resources used by a system with minimal accuracy loss.
(hu)Man vs. Machine: In the Future of Motorsport, can Autonomous Vehicles Compete?
Mar 02, 2026Motorsport has historically driven technological innovation in the automotive industry. Autonomous racing provides a proving ground to push the limits of performance of autonomous vehicle (AV) systems. In principle, AVs could be at least as fast, if not faster, than humans. However, human driven racing provides broader audience appeal thus far, and is more strategically challenging. Both provide opportunities to push each other even further technologically, yet competitions remain separate. This paper evaluates whether the future of motorsport could encompass joint competition between humans and AVs. Analysis of the current state of the art, as well as recent competition outcomes, shows that while technical performance has reached comparable levels, there are substantial challenges in racecraft, strategy and safety that need to be overcome. Outstanding issues involved in mixed human-AI racing, ranging from an initial assessment of critical factors such as system-level latencies, to effective planning and risk guarantees are explored. The crucial non-technical aspect of audience engagement and appeal regarding the changing character of motorsport is addressed. In the wider context of motorsport and AVs, this work outlines a proposed agenda for future research to 'keep pushing the possible', in the true spirit of motorsport.
SEG-JPEG: Simple Visual Semantic Communications for Remote Operation of Automated Vehicles over Unreliable Wireless Networks
Feb 16, 2026Remote Operation is touted as being key to the rapid deployment of automated vehicles. Streaming imagery to control connected vehicles remotely currently requires a reliable, high throughput network connection, which can be limited in real-world remote operation deployments relying on public network infrastructure. This paper investigates how the application of computer vision assisted semantic communication can be used to circumvent data loss and corruption associated with traditional image compression techniques. By encoding the segmentations of detected road users into colour coded highlights within low resolution greyscale imagery, the required data rate can be reduced by 50 \% compared with conventional techniques, while maintaining visual clarity. This enables a median glass-to-glass latency of below 200ms even when the network data rate is below 500kbit/s, while clearly outlining salient road users to enhance situational awareness of the remote operator. The approach is demonstrated in an area of variable 4G mobile connectivity using an automated last-mile delivery vehicle. With this technique, the results indicate that large-scale deployment of remotely operated automated vehicles could be possible even on the often constrained public 4G/5G mobile network, providing the potential to expedite the nationwide roll-out of automated vehicles.
Uncertainty-Aware Autonomous Vehicles: Predicting the Road Ahead
Oct 26, 2025Autonomous Vehicle (AV) perception systems have advanced rapidly in recent years, providing vehicles with the ability to accurately interpret their environment. Perception systems remain susceptible to errors caused by overly-confident predictions in the case of rare events or out-of-sample data. This study equips an autonomous vehicle with the ability to 'know when it is uncertain', using an uncertainty-aware image classifier as part of the AV software stack. Specifically, the study exploits the ability of Random-Set Neural Networks (RS-NNs) to explicitly quantify prediction uncertainty. Unlike traditional CNNs or Bayesian methods, RS-NNs predict belief functions over sets of classes, allowing the system to identify and signal uncertainty clearly in novel or ambiguous scenarios. The system is tested in a real-world autonomous racing vehicle software stack, with the RS-NN classifying the layout of the road ahead and providing the associated uncertainty of the prediction. Performance of the RS-NN under a range of road conditions is compared against traditional CNN and Bayesian neural networks, with the RS-NN achieving significantly higher accuracy and superior uncertainty calibration. This integration of RS-NNs into Robot Operating System (ROS)-based vehicle control pipeline demonstrates that predictive uncertainty can dynamically modulate vehicle speed, maintaining high-speed performance under confident predictions while proactively improving safety through speed reductions in uncertain scenarios. These results demonstrate the potential of uncertainty-aware neural networks - in particular RS-NNs - as a practical solution for safer and more robust autonomous driving.
ROAD-Waymo: Action Awareness at Scale for Autonomous Driving
Nov 03, 2024

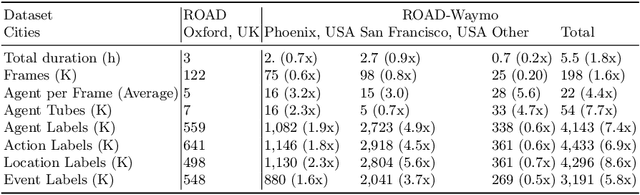
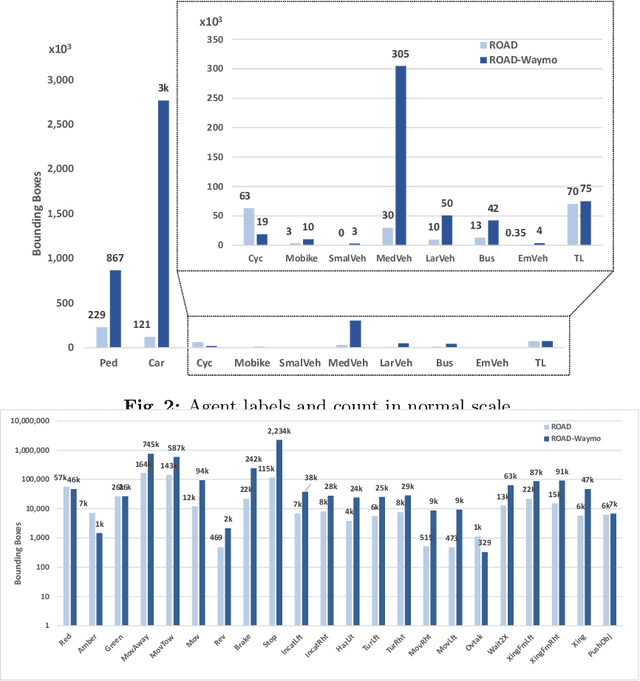
Autonomous Vehicle (AV) perception systems require more than simply seeing, via e.g., object detection or scene segmentation. They need a holistic understanding of what is happening within the scene for safe interaction with other road users. Few datasets exist for the purpose of developing and training algorithms to comprehend the actions of other road users. This paper presents ROAD-Waymo, an extensive dataset for the development and benchmarking of techniques for agent, action, location and event detection in road scenes, provided as a layer upon the (US) Waymo Open dataset. Considerably larger and more challenging than any existing dataset (and encompassing multiple cities), it comes with 198k annotated video frames, 54k agent tubes, 3.9M bounding boxes and a total of 12.4M labels. The integrity of the dataset has been confirmed and enhanced via a novel annotation pipeline designed for automatically identifying violations of requirements specifically designed for this dataset. As ROAD-Waymo is compatible with the original (UK) ROAD dataset, it provides the opportunity to tackle domain adaptation between real-world road scenarios in different countries within a novel benchmark: ROAD++.
A Hybrid Graph Network for Complex Activity Detection in Video
Oct 30, 2023Interpretation and understanding of video presents a challenging computer vision task in numerous fields - e.g. autonomous driving and sports analytics. Existing approaches to interpreting the actions taking place within a video clip are based upon Temporal Action Localisation (TAL), which typically identifies short-term actions. The emerging field of Complex Activity Detection (CompAD) extends this analysis to long-term activities, with a deeper understanding obtained by modelling the internal structure of a complex activity taking place within the video. We address the CompAD problem using a hybrid graph neural network which combines attention applied to a graph encoding the local (short-term) dynamic scene with a temporal graph modelling the overall long-duration activity. Our approach is as follows: i) Firstly, we propose a novel feature extraction technique which, for each video snippet, generates spatiotemporal `tubes' for the active elements (`agents') in the (local) scene by detecting individual objects, tracking them and then extracting 3D features from all the agent tubes as well as the overall scene. ii) Next, we construct a local scene graph where each node (representing either an agent tube or the scene) is connected to all other nodes. Attention is then applied to this graph to obtain an overall representation of the local dynamic scene. iii) Finally, all local scene graph representations are interconnected via a temporal graph, to estimate the complex activity class together with its start and end time. The proposed framework outperforms all previous state-of-the-art methods on all three datasets including ActivityNet-1.3, Thumos-14, and ROAD.
Temporal DINO: A Self-supervised Video Strategy to Enhance Action Prediction
Aug 20, 2023The emerging field of action prediction plays a vital role in various computer vision applications such as autonomous driving, activity analysis and human-computer interaction. Despite significant advancements, accurately predicting future actions remains a challenging problem due to high dimensionality, complex dynamics and uncertainties inherent in video data. Traditional supervised approaches require large amounts of labelled data, which is expensive and time-consuming to obtain. This paper introduces a novel self-supervised video strategy for enhancing action prediction inspired by DINO (self-distillation with no labels). The Temporal-DINO approach employs two models; a 'student' processing past frames; and a 'teacher' processing both past and future frames, enabling a broader temporal context. During training, the teacher guides the student to learn future context by only observing past frames. The strategy is evaluated on ROAD dataset for the action prediction downstream task using 3D-ResNet, Transformer, and LSTM architectures. The experimental results showcase significant improvements in prediction performance across these architectures, with our method achieving an average enhancement of 9.9% Precision Points (PP), highlighting its effectiveness in enhancing the backbones' capabilities of capturing long-term dependencies. Furthermore, our approach demonstrates efficiency regarding the pretraining dataset size and the number of epochs required. This method overcomes limitations present in other approaches, including considering various backbone architectures, addressing multiple prediction horizons, reducing reliance on hand-crafted augmentations, and streamlining the pretraining process into a single stage. These findings highlight the potential of our approach in diverse video-based tasks such as activity recognition, motion planning, and scene understanding.
A Scenario-Based Functional Testing Approach to Improving DNN Performance
Jul 13, 2023This paper proposes a scenario-based functional testing approach for enhancing the performance of machine learning (ML) applications. The proposed method is an iterative process that starts with testing the ML model on various scenarios to identify areas of weakness. It follows by a further testing on the suspected weak scenarios and statistically evaluate the model's performance on the scenarios to confirm the diagnosis. Once the diagnosis of weak scenarios is confirmed by test results, the treatment of the model is performed by retraining the model using a transfer learning technique with the original model as the base and applying a set of training data specifically targeting the treated scenarios plus a subset of training data selected at random from the original train dataset to prevent the so-call catastrophic forgetting effect. Finally, after the treatment, the model is assessed and evaluated again by testing on the treated scenarios as well as other scenarios to check if the treatment is effective and no side effect caused. The paper reports a case study with a real ML deep neural network (DNN) model, which is the perception system of an autonomous racing car. It is demonstrated that the method is effective in the sense that DNN model's performance can be improved. It provides an efficient method of enhancing ML model's performance with much less human and compute resource than retrain from scratch.
Never mind the metrics -- what about the uncertainty? Visualising confusion matrix metric distributions
Jun 05, 2022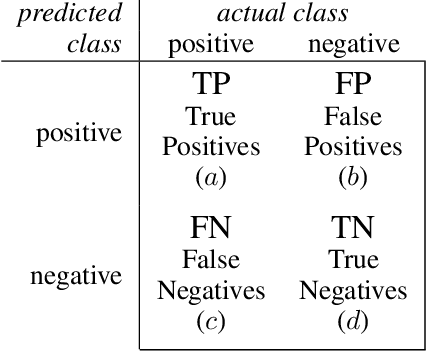
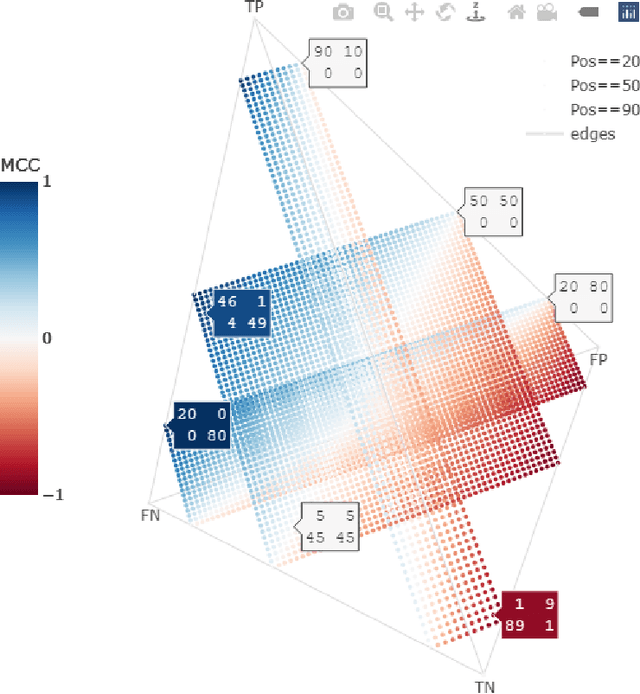
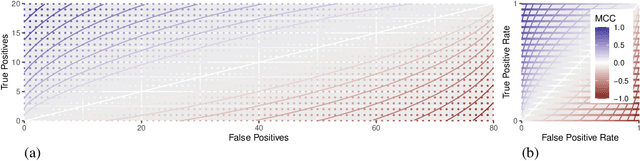
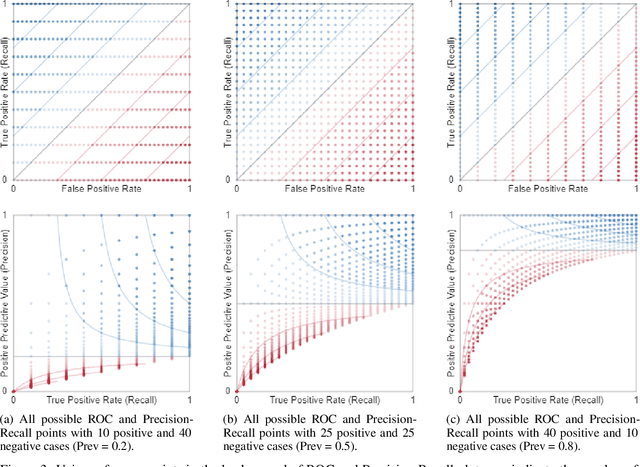
There are strong incentives to build models that demonstrate outstanding predictive performance on various datasets and benchmarks. We believe these incentives risk a narrow focus on models and on the performance metrics used to evaluate and compare them -- resulting in a growing body of literature to evaluate and compare metrics. This paper strives for a more balanced perspective on classifier performance metrics by highlighting their distributions under different models of uncertainty and showing how this uncertainty can easily eclipse differences in the empirical performance of classifiers. We begin by emphasising the fundamentally discrete nature of empirical confusion matrices and show how binary matrices can be meaningfully represented in a three dimensional compositional lattice, whose cross-sections form the basis of the space of receiver operating characteristic (ROC) curves. We develop equations, animations and interactive visualisations of the contours of performance metrics within (and beyond) this ROC space, showing how some are affected by class imbalance. We provide interactive visualisations that show the discrete posterior predictive probability mass functions of true and false positive rates in ROC space, and how these relate to uncertainty in performance metrics such as Balanced Accuracy (BA) and the Matthews Correlation Coefficient (MCC). Our hope is that these insights and visualisations will raise greater awareness of the substantial uncertainty in performance metric estimates that can arise when classifiers are evaluated on empirical datasets and benchmarks, and that classification model performance claims should be tempered by this understanding.
Simulating Malicious Attacks on VANETs for Connected and Autonomous Vehicle Cybersecurity: A Machine Learning Dataset
Feb 15, 2022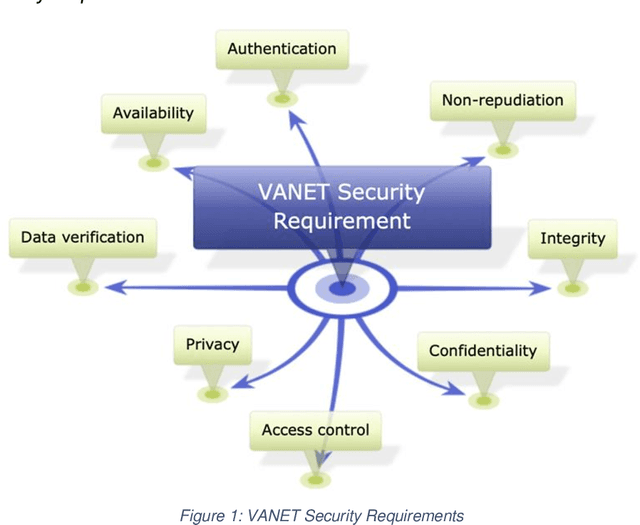

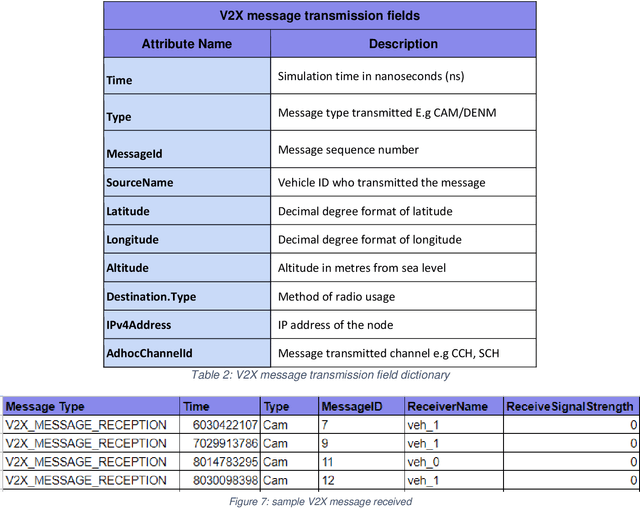
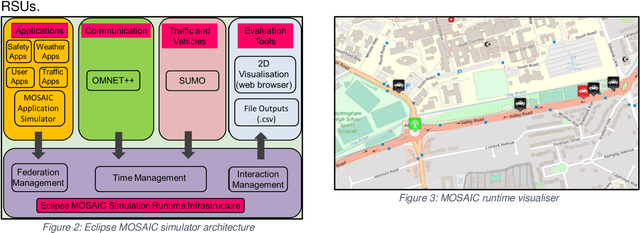
Connected and Autonomous Vehicles (CAVs) rely on Vehicular Adhoc Networks with wireless communication between vehicles and roadside infrastructure to support safe operation. However, cybersecurity attacks pose a threat to VANETs and the safe operation of CAVs. This study proposes the use of simulation for modelling typical communication scenarios which may be subject to malicious attacks. The Eclipse MOSAIC simulation framework is used to model two typical road scenarios, including messaging between the vehicles and infrastructure - and both replay and bogus information cybersecurity attacks are introduced. The model demonstrates the impact of these attacks, and provides an open dataset to inform the development of machine learning algorithms to provide anomaly detection and mitigation solutions for enhancing secure communications and safe deployment of CAVs on the road.