 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROAD-Waymo: Action Awareness at Scale for Autonomous Driving
Nov 03, 2024

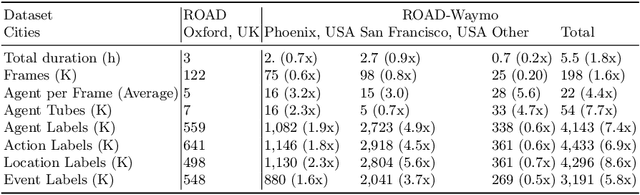
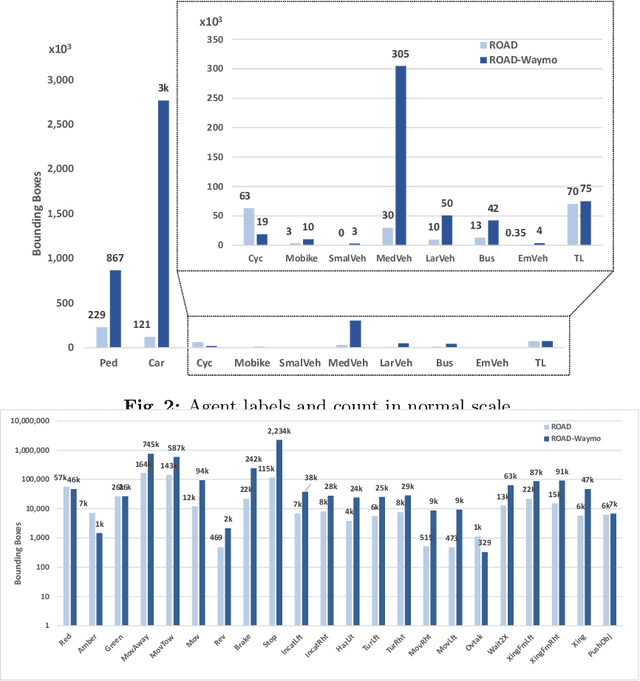
Autonomous Vehicle (AV) perception systems require more than simply seeing, via e.g., object detection or scene segmentation. They need a holistic understanding of what is happening within the scene for safe interaction with other road users. Few datasets exist for the purpose of developing and training algorithms to comprehend the actions of other road users. This paper presents ROAD-Waymo, an extensive dataset for the development and benchmarking of techniques for agent, action, location and event detection in road scenes, provided as a layer upon the (US) Waymo Open dataset. Considerably larger and more challenging than any existing dataset (and encompassing multiple cities), it comes with 198k annotated video frames, 54k agent tubes, 3.9M bounding boxes and a total of 12.4M labels. The integrity of the dataset has been confirmed and enhanced via a novel annotation pipeline designed for automatically identifying violations of requirements specifically designed for this dataset. As ROAD-Waymo is compatible with the original (UK) ROAD dataset, it provides the opportunity to tackle domain adaptation between real-world road scenarios in different countries within a novel benchmark: ROAD++.
A Hybrid Graph Network for Complex Activity Detection in Video
Oct 30, 2023Interpretation and understanding of video presents a challenging computer vision task in numerous fields - e.g. autonomous driving and sports analytics. Existing approaches to interpreting the actions taking place within a video clip are based upon Temporal Action Localisation (TAL), which typically identifies short-term actions. The emerging field of Complex Activity Detection (CompAD) extends this analysis to long-term activities, with a deeper understanding obtained by modelling the internal structure of a complex activity taking place within the video. We address the CompAD problem using a hybrid graph neural network which combines attention applied to a graph encoding the local (short-term) dynamic scene with a temporal graph modelling the overall long-duration activity. Our approach is as follows: i) Firstly, we propose a novel feature extraction technique which, for each video snippet, generates spatiotemporal `tubes' for the active elements (`agents') in the (local) scene by detecting individual objects, tracking them and then extracting 3D features from all the agent tubes as well as the overall scene. ii) Next, we construct a local scene graph where each node (representing either an agent tube or the scene) is connected to all other nodes. Attention is then applied to this graph to obtain an overall representation of the local dynamic scene. iii) Finally, all local scene graph representations are interconnected via a temporal graph, to estimate the complex activity class together with its start and end time. The proposed framework outperforms all previous state-of-the-art methods on all three datasets including ActivityNet-1.3, Thumos-14, and ROAD.
Temporal DINO: A Self-supervised Video Strategy to Enhance Action Prediction
Aug 20, 2023The emerging field of action prediction plays a vital role in various computer vision applications such as autonomous driving, activity analysis and human-computer interaction. Despite significant advancements, accurately predicting future actions remains a challenging problem due to high dimensionality, complex dynamics and uncertainties inherent in video data. Traditional supervised approaches require large amounts of labelled data, which is expensive and time-consuming to obtain. This paper introduces a novel self-supervised video strategy for enhancing action prediction inspired by DINO (self-distillation with no labels). The Temporal-DINO approach employs two models; a 'student' processing past frames; and a 'teacher' processing both past and future frames, enabling a broader temporal context. During training, the teacher guides the student to learn future context by only observing past frames. The strategy is evaluated on ROAD dataset for the action prediction downstream task using 3D-ResNet, Transformer, and LSTM architectures. The experimental results showcase significant improvements in prediction performance across these architectures, with our method achieving an average enhancement of 9.9% Precision Points (PP), highlighting its effectiveness in enhancing the backbones' capabilities of capturing long-term dependencies. Furthermore, our approach demonstrates efficiency regarding the pretraining dataset size and the number of epochs required. This method overcomes limitations present in other approaches, including considering various backbone architectures, addressing multiple prediction horizons, reducing reliance on hand-crafted augmentations, and streamlining the pretraining process into a single stage. These findings highlight the potential of our approach in diverse video-based tasks such as activity recognition, motion planning, and scene understanding.
Identification of Cognitive Workload during Surgical Tasks with Multimodal Deep Learning
Sep 12, 2022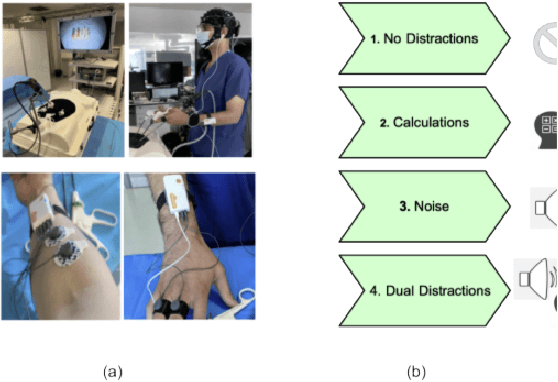
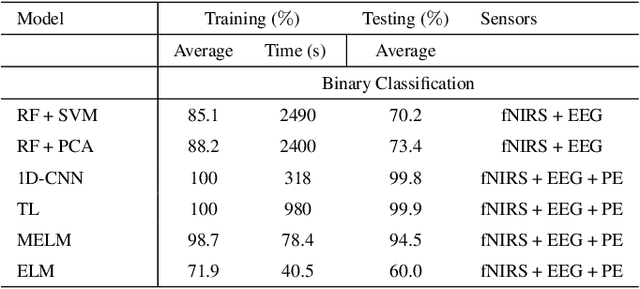
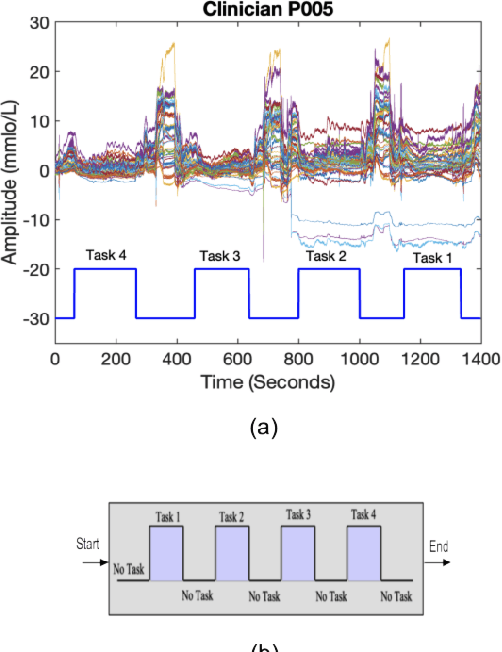
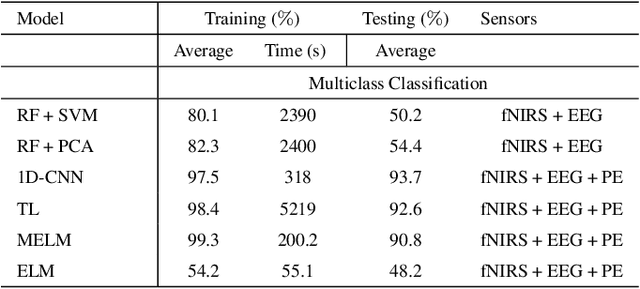
In operating Rooms (ORs), activities are usually different from other typical working environments. In particular, surgeons are frequently exposed to multiple psycho-organizational constraints that may cause negative repercussions on their health and performance. This is commonly attributed to an increase in the associated Cognitive Workload (CWL) that results from dealing with unexpected and repetitive tasks, as well as large amounts of information and potentially risky cognitive overload. In this paper, a cascade of two machine learning approaches is suggested for the multimodal recognition of CWL in a number of four different surgical tasks. First, a model based on the concept of transfer learning is used to identify if a surgeon is experiencing any CWL. Secondly, a Convolutional Neural Network (CNN) uses this information to identify different types of CWL associated to each surgical task. The suggested multimodal approach consider adjacent signals from electroencephalogram (EEG), functional near-infrared spectroscopy (fNIRS) and pupil eye diameter. The concatenation of signals allows complex correlations in terms of time (temporal) and channel location (spatial). Data collection is performed by a Multi-sensing AI Environment for Surgical Task $\&$ Role Optimisation platform (MAESTRO) developed at HARMS Lab. To compare the performance of the proposed methodology, a number of state-of-art machine learning techniques have been implemented. The tests show that the proposed model has a precision of 93%.
Situation Awareness for Automated Surgical Check-listing in AI-Assisted Operating Room
Sep 12, 2022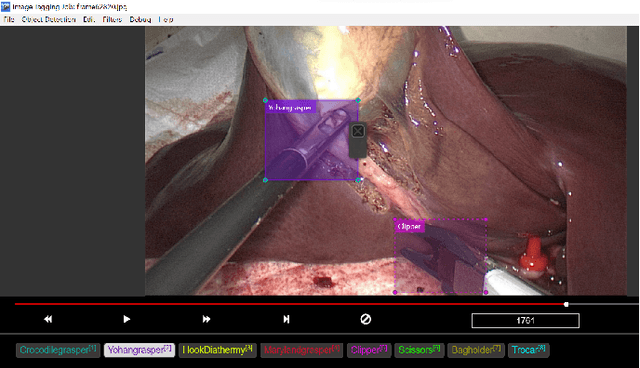
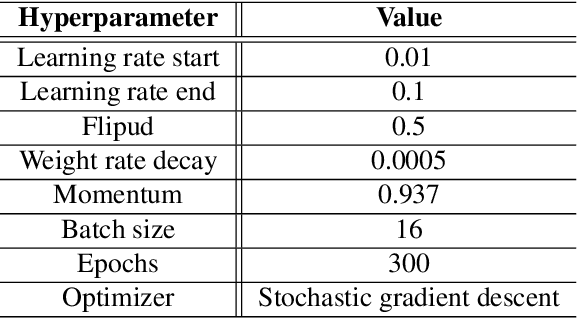

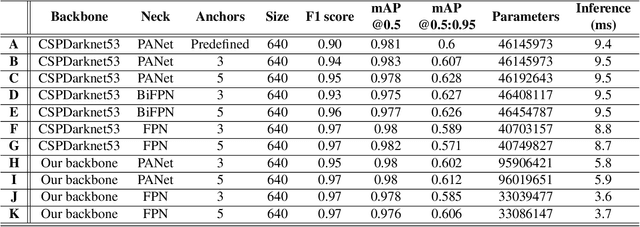
Nowadays, there are more surgical procedures that are being performed using minimally invasive surgery (MIS). This is due to its many benefits, such as minimal post-operative problems, less bleeding, minor scarring, and a speedy recovery. However, the MIS's constrained field of view, small operating room, and indirect viewing of the operating scene could lead to surgical tools colliding and potentially harming human organs or tissues. Therefore, MIS problems can be considerably reduced, and surgical procedure accuracy and success rates can be increased by using an endoscopic video feed to detect and monitor surgical instruments in real-time. In this paper, a set of improvements made to the YOLOV5 object detector to enhance the detection of surgical instruments was investigated, analyzed, and evaluated. In doing this, we performed performance-based ablation studies, explored the impact of altering the YOLOv5 model's backbone, neck, and anchor structural elements, and annotated a unique endoscope dataset. Additionally, we compared the effectiveness of our ablation investigations with that of four additional SOTA object detectors (YOLOv7, YOLOR, Scaled-YOLOv4 and YOLOv3-SPP). Except for YOLOv3-SPP, which had the same model performance of 98.3% in mAP and a similar inference speed, all of our benchmark models, including the original YOLOv5, were surpassed by our top refined model in experiments using our fresh endoscope dataset.
Vision in adverse weather: Augmentation using CycleGANs with various object detectors for robust perception in autonomous racing
Jan 11, 2022
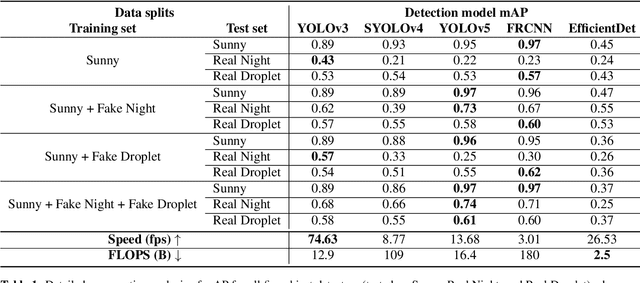
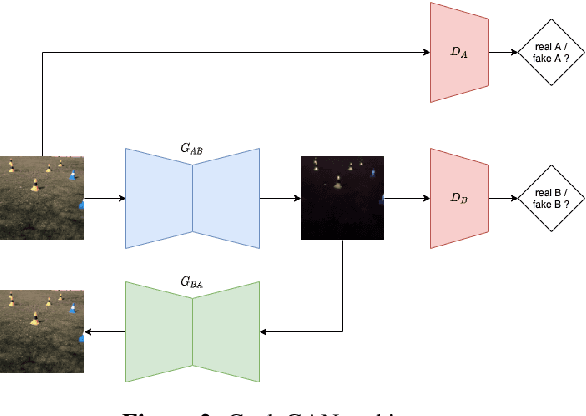

In an autonomous driving system, perception - identification of features and objects from the environment - is crucial. In autonomous racing, high speeds and small margins demand rapid and accurate detection systems. During the race, the weather can change abruptly, causing significant degradation in perception, resulting in ineffective manoeuvres. In order to improve detection in adverse weather, deep-learning-based models typically require extensive datasets captured in such conditions - the collection of which is a tedious, laborious, and costly process. However, recent developments in CycleGAN architectures allow the synthesis of highly realistic scenes in multiple weather conditions. To this end, we introduce an approach of using synthesised adverse condition datasets in autonomous racing (generated using CycleGAN) to improve the performance of four out of five state-of-the-art detectors by an average of 42.7 and 4.4 mAP percentage points in the presence of night-time conditions and droplets, respectively. Furthermore, we present a comparative analysis of five object detectors - identifying the optimal pairing of detector and training data for use during autonomous racing in challenging conditions.
YOLO-Z: Improving small object detection in YOLOv5 for autonomous vehicles
Dec 23, 2021


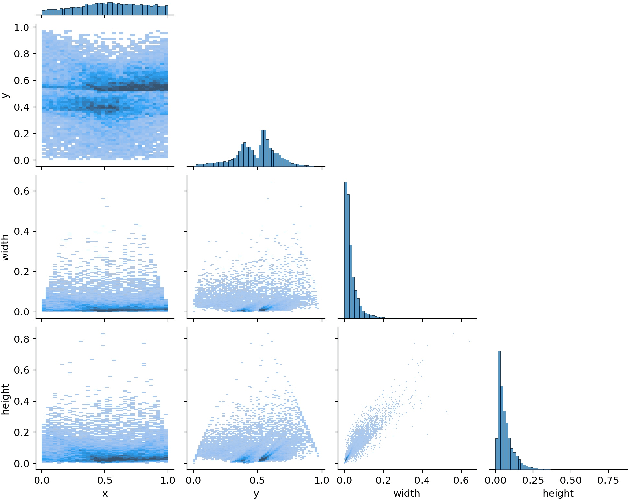
As autonomous vehicles and autonomous racing rise in popularity, so does the need for faster and more accurate detectors. While our naked eyes are able to extract contextual information almost instantly, even from far away, image resolution and computational resources limitations make detecting smaller objects (that is, objects that occupy a small pixel area in the input image) a genuinely challenging task for machines and a wide-open research field. This study explores how the popular YOLOv5 object detector can be modified to improve its performance in detecting smaller objects, with a particular application in autonomous racing. To achieve this, we investigate how replacing certain structural elements of the model (as well as their connections and other parameters) can affect performance and inference time. In doing so, we propose a series of models at different scales, which we name `YOLO-Z', and which display an improvement of up to 6.9% in mAP when detecting smaller objects at 50% IOU, at the cost of just a 3ms increase in inference time compared to the original YOLOv5. Our objective is to inform future research on the potential of adjusting a popular detector such as YOLOv5 to address specific tasks and provide insights on how specific changes can impact small object detection. Such findings, applied to the broader context of autonomous vehicles, could increase the amount of contextual information available to such systems.