 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuXi-Linear: Unleashing the Power of Linear Attention in Long-term Time-aware Sequential Recommendation
Feb 27, 2026Modern recommendation systems primarily rely on attention mechanisms with quadratic complexity, which limits their ability to handle long user sequences and slows down inference. While linear attention is a promising alternative, existing research faces three critical challenges: (1) temporal signals are often overlooked or integrated via naive coupling that causes mutual interference between temporal and semantic signals while neglecting behavioral periodicity; (2) insufficient positional information provided by existing linear frameworks; and (3) a primary focus on short sequences and shallow architectures. To address these issues, we propose FuXi-Linear, a linear-complexity model designed for efficient long-sequence recommendation. Our approach introduces two key components: (1) a Temporal Retention Channel that independently computes periodic attention weights using temporal data, preventing crosstalk between temporal and semantic signals; (2) a Linear Positional Channel that integrates positional information through learnable kernels within linear complexity. Moreover, we demonstrate that FuXi-Linear exhibits a robust power-law scaling property at a thousand-length scale, a characteristic largely unexplored in prior linear recommendation studies. Extensive experiments on sequences of several thousand tokens demonstrate that FuXi-Linear outperforms state-of-the-art models in recommendation quality, while achieving up to 10$\times$ speedup in the prefill stage and up to 21$\times$ speedup in the decode stage compared to competitive baselines. Our code has been released in a public repository https://github.com/USTC-StarTeam/fuxi-linear.
Robustness of Object Detection of Autonomous Vehicles in Adverse Weather Conditions
Feb 13, 2026As self-driving technology advances toward widespread adoption, determining safe operational thresholds across varying environmental conditions becomes critical for public safety. This paper proposes a method for evaluating the robustness of object detection ML models in autonomous vehicles under adverse weather conditions. It employs data augmentation operators to generate synthetic data that simulates different severance degrees of the adverse operation conditions at progressive intensity levels to find the lowest intensity of the adverse conditions at which the object detection model fails. The robustness of the object detection model is measured by the average first failure coefficients (AFFC) over the input images in the benchmark. The paper reports an experiment with four object detection models: YOLOv5s, YOLOv11s, Faster R-CNN, and Detectron2, utilising seven data augmentation operators that simulate weather conditions fog, rain, and snow, and lighting conditions of dark, bright, flaring, and shadow. The experiment data show that the method is feasible, effective, and efficient to evaluate and compare the robustness of object detection models in various adverse operation conditions. In particular, the Faster R-CNN model achieved the highest robustness with an overall average AFFC of 71.9% over all seven adverse conditions, while YOLO variants showed the AFFC values of 43%. The method is also applied to assess the impact of model training that targets adverse operation conditions using synthetic data on model robustness. It is observed that such training can improve robustness in adverse conditions but may suffer from diminishing returns and forgetting phenomena (i.e., decline in robustness) if overtrained.
RelayGR: Scaling Long-Sequence Generative Recommendation via Cross-Stage Relay-Race Inference
Jan 05, 2026Real-time recommender systems execute multi-stage cascades (retrieval, pre-processing, fine-grained ranking) under strict tail-latency SLOs, leaving only tens of milliseconds for ranking. Generative recommendation (GR) models can improve quality by consuming long user-behavior sequences, but in production their online sequence length is tightly capped by the ranking-stage P99 budget. We observe that the majority of GR tokens encode user behaviors that are independent of the item candidates, suggesting an opportunity to pre-infer a user-behavior prefix once and reuse it during ranking rather than recomputing it on the critical path. Realizing this idea at industrial scale is non-trivial: the prefix cache must survive across multiple pipeline stages before the final ranking instance is determined, the user population implies cache footprints far beyond a single device, and indiscriminate pre-inference would overload shared resources under high QPS. We present RelayGR, a production system that enables in-HBM relay-race inference for GR. RelayGR selectively pre-infers long-term user prefixes, keeps their KV caches resident in HBM over the request lifecycle, and ensures the subsequent ranking can consume them without remote fetches. RelayGR combines three techniques: 1) a sequence-aware trigger that admits only at-risk requests under a bounded cache footprint and pre-inference load, 2) an affinity-aware router that co-locates cache production and consumption by routing both the auxiliary pre-infer signal and the ranking request to the same instance, and 3) a memory-aware expander that uses server-local DRAM to capture short-term cross-request reuse while avoiding redundant reloads. We implement RelayGR on Huawei Ascend NPUs and evaluate it with real queries. Under a fixed P99 SLO, RelayGR supports up to 1.5$\times$ longer sequences and improves SLO-compliant throughput by up to 3.6$\times$.
Multi-Sensor Fusion for Extended Object Tracking Exploiting Active and Passive Radio Signals
Sep 03, 2025Reliable and robust positioning of radio devices remains a challenging task due to multipath propagation, hardware impairments, and interference from other radio transmitters. A frequently overlooked but critical factor is the agent itself, e.g., the user carrying the device, which potentially obstructs line-of-sight (LOS) links to the base stations (anchors). This paper addresses the problem of accurate positioning in scenarios where LOS links are partially blocked by the agent. The agent is modeled as an extended object (EO) that scatters, attenuates, and blocks radio signals. We propose a Bayesian method that fuses ``active'' measurements (between device and anchors) with ``passive'' multistatic radar-type measurements (between anchors, reflected by the EO). To handle measurement origin uncertainty, we introduce an multi-sensor and multiple-measurement probabilistic data association (PDA) algorithm that jointly fuses all EO-related measurements. Furthermore, we develop an EO model tailored to agents such as human users, accounting for multiple reflections scattered off the body surface, and propose a simplified variant for low-complexity implementation. Evaluation on both synthetic and real radio measurements demonstrates that the proposed algorithm outperforms conventional PDA methods based on point target assumptions, particularly during and after obstructed line-of-sight (OLOS) conditions.
Multi-Sensor Fusion of Active and Passive Measurements for Extended Object Tracking
Apr 25, 2025



This paper addresses the challenge of achieving robust and reliable positioning of a radio device carried by an agent, in scenarios where direct line-of-sight (LOS) radio links are obstructed by the agent. We propose a Bayesian estimation algorithm that integrates active measurements between the radio device and anchors with passive measurements in-between anchors reflecting off the agent. A geometry-based scattering measurement model is introduced for multi-sensor structures, and multiple object-related measurements are incorporated to formulate an extended object probabilistic data association (PDA) algorithm, where the agent that blocks, scatters and attenuates radio signals is modeled as an extended object (EO). The proposed approach significantly improves the accuracy during and after obstructed LOS conditions, outperforming the conventional PDA (which is based on the point-target-assumption) and methods relying solely on active measurements.
Separated Contrastive Learning for Matching in Cross-domain Recommendation with Curriculum Scheduling
Feb 22, 2025



Cross-domain recommendation (CDR) is a task that aims to improve the recommendation performance in a target domain by leveraging the information from source domains. Contrastive learning methods have been widely adopted among intra-domain (intra-CL) and inter-domain (inter-CL) users/items for their representation learning and knowledge transfer during the matching stage of CDR. However, we observe that directly employing contrastive learning on mixed-up intra-CL and inter-CL tasks ignores the difficulty of learning from inter-domain over learning from intra-domain, and thus could cause severe training instability. Therefore, this instability deteriorates the representation learning process and hurts the quality of generated embeddings. To this end, we propose a novel framework named SCCDR built up on a separated intra-CL and inter-CL paradigm and a stop-gradient operation to handle the drawback. Specifically, SCCDR comprises two specialized curriculum stages: intra-inter separation and inter-domain curriculum scheduling. The former stage explicitly uses two distinct contrastive views for the intra-CL task in the source and target domains, respectively. Meanwhile, the latter stage deliberately tackles the inter-CL tasks with a curriculum scheduling strategy that derives effective curricula by accounting for the difficulty of negative samples anchored by overlapping users. Empirical experiments on various open-source datasets and an offline proprietary industrial dataset extracted from a real-world recommender system, and an online A/B test verify that SCCDR achieves state-of-the-art performance over multiple baselines.
FuXi-$α$: Scaling Recommendation Model with Feature Interaction Enhanced Transformer
Feb 05, 2025



Inspired by scaling laws and large language models, research on large-scale recommendation models has gained significant attention. Recent advancements have shown that expanding sequential recommendation models to large-scale recommendation models can be an effective strategy. Current state-of-the-art sequential recommendation models primarily use self-attention mechanisms for explicit feature interactions among items, while implicit interactions are managed through Feed-Forward Networks (FFNs). However, these models often inadequately integrate temporal and positional information, either by adding them to attention weights or by blending them with latent representations, which limits their expressive power. A recent model, HSTU, further reduces the focus on implicit feature interactions, constraining its performance. We propose a new model called FuXi-$\alpha$ to address these issues. This model introduces an Adaptive Multi-channel Self-attention mechanism that distinctly models temporal, positional, and semantic features, along with a Multi-stage FFN to enhance implicit feature interactions. Our offline experiments demonstrate that our model outperforms existing models, with its performance continuously improving as the model size increases. Additionally, we conducted an online A/B test within the Huawei Music app, which showed a $4.76\%$ increase in the average number of songs played per user and a $5.10\%$ increase in the average listening duration per user. Our code has been released at https://github.com/USTC-StarTeam/FuXi-alpha.
LIBER: Lifelong User Behavior Modeling Based on Large Language Models
Nov 22, 2024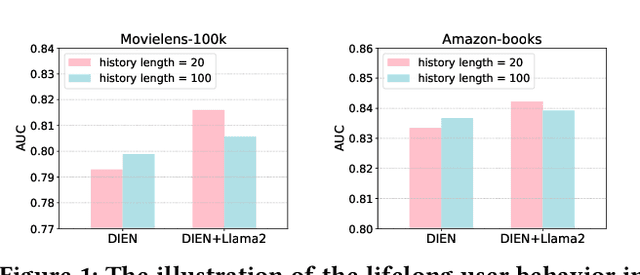
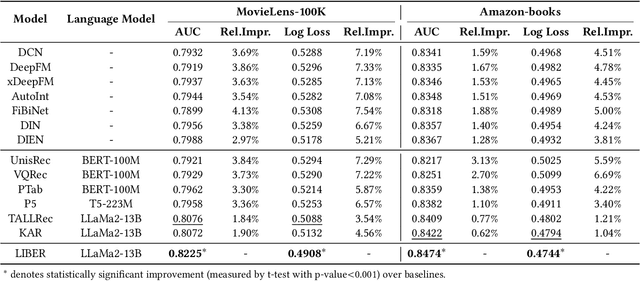
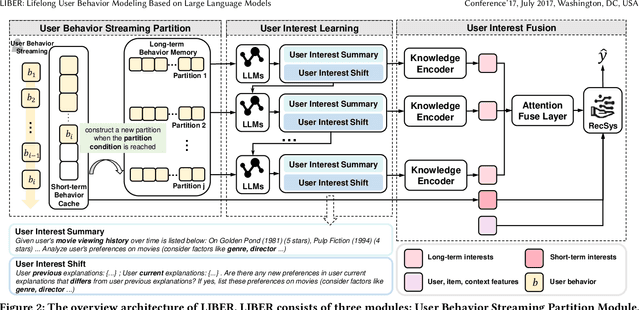
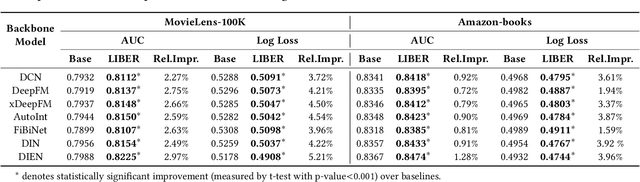
CTR prediction plays a vital role in recommender systems. Recently, large language models (LLMs) have been applied in recommender systems due to their emergence abilities. While leveraging semantic information from LLMs has shown some improvements in the performance of recommender systems, two notable limitations persist in these studies. First, LLM-enhanced recommender systems encounter challenges in extracting valuable information from lifelong user behavior sequences within textual contexts for recommendation tasks. Second, the inherent variability in human behaviors leads to a constant stream of new behaviors and irregularly fluctuating user interests. This characteristic imposes two significant challenges on existing models. On the one hand, it presents difficulties for LLMs in effectively capturing the dynamic shifts in user interests within these sequences, and on the other hand, there exists the issue of substantial computational overhead if the LLMs necessitate recurrent calls upon each update to the user sequences. In this work, we propose Lifelong User Behavior Modeling (LIBER) based on large language models, which includes three modules: (1) User Behavior Streaming Partition (UBSP), (2) User Interest Learning (UIL), and (3) User Interest Fusion (UIF). Initially, UBSP is employed to condense lengthy user behavior sequences into shorter partitions in an incremental paradigm, facilitating more efficient processing. Subsequently, UIL leverages LLMs in a cascading way to infer insights from these partitions. Finally, UIF integrates the textual outputs generated by the aforementioned processes to construct a comprehensive representation, which can be incorporated by any recommendation model to enhance performance. LIBER has been deployed on Huawei's music recommendation service and achieved substantial improvements in users' play count and play time by 3.01% and 7.69%.
SimpleBEV: Improved LiDAR-Camera Fusion Architecture for 3D Object Detection
Nov 08, 2024



More and more research works fuse the LiDAR and camera information to improve the 3D object detection of the autonomous driving system. Recently, a simple yet effective fusion framework has achieved an excellent detection performance, fusing the LiDAR and camera features in a unified bird's-eye-view (BEV) space. In this paper, we propose a LiDAR-camera fusion framework, named SimpleBEV, for accurate 3D object detection, which follows the BEV-based fusion framework and improves the camera and LiDAR encoders, respectively. Specifically, we perform the camera-based depth estimation using a cascade network and rectify the depth results with the depth information derived from the LiDAR points. Meanwhile, an auxiliary branch that implements the 3D object detection using only the camera-BEV features is introduced to exploit the camera information during the training phase. Besides, we improve the LiDAR feature extractor by fusing the multi-scaled sparse convolutional features. Experimental results demonstrate the effectiveness of our proposed method. Our method achieves 77.6\% NDS accuracy on the nuScenes dataset, showcasing superior performance in the 3D object detection track.
Efficient and Deployable Knowledge Infusion for Open-World Recommendations via Large Language Models
Aug 20, 2024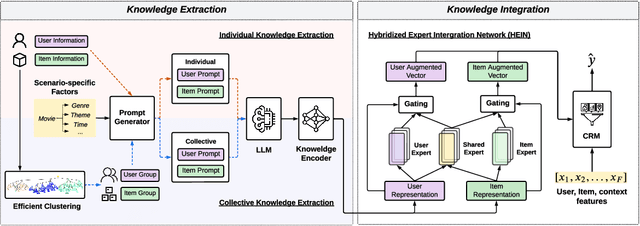
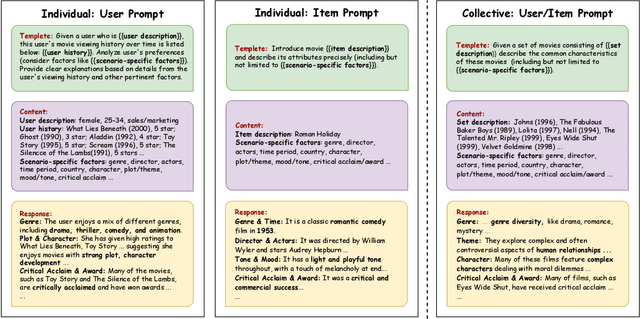
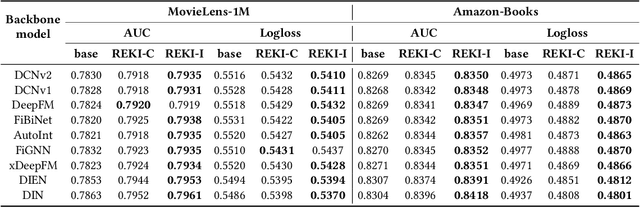
Recommender systems (RSs) play a pervasive role in today's online services, yet their closed-loop nature constrains their access to open-world knowledge. Recently, large language models (LLMs) have shown promise in bridging this gap. However, previous attempts to directly implement LLMs as recommenders fall short in meeting the requirements of industrial RSs, particularly in terms of online inference latency and offline resource efficiency. Thus, we propose REKI to acquire two types of external knowledge about users and items from LLMs. Specifically, we introduce factorization prompting to elicit accurate knowledge reasoning on user preferences and items. We develop individual knowledge extraction and collective knowledge extraction tailored for different scales of scenarios, effectively reducing offline resource consumption. Subsequently, generated knowledge undergoes efficient transformation and condensation into augmented vectors through a hybridized expert-integrated network, ensuring compatibility. The obtained vectors can then be used to enhance any conventional recommendation model. We also ensure efficient inference by preprocessing and prestoring the knowledge from LLMs. Experiments demonstrate that REKI outperforms state-of-the-art baselines and is compatible with lots of recommendation algorithms and tasks. Now, REKI has been deployed to Huawei's news and music recommendation platforms and gained a 7% and 1.99% improvement during the online A/B test.