 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Academic Conferences are Potentially Facing Denominator Gaming Caused by Fully Automated Scientific Agents
May 11, 2026The implicit policy of maintaining relatively stable acceptance rates at top AI conferences, despite exponentially growing submissions, introduces a critical structural vulnerability. This position paper characterizes a new systemic threat we term Agentic Denominator Gaming, in which a malicious actor deploys AI agents to generate and submit a large volume of superficially plausible but low-quality papers. Crucially, their objective is not the acceptance of low-quality papers, but rather to inflate the submission denominator and overwhelm reviewing capacity. Under a relatively stable acceptance rate, this dilution can systematically increase the publication probability of a small, targeted set of legitimate papers. We analyze the practical feasibility of this threat and its broader consequences, including intensified reviewer burnout, degraded review quality, and the emergence of industrialized automated agent mills. Finally, we propose and evaluate a range of mitigation strategies, and argue that durable protection will require system-level policy and incentive reforms, rather than relying primarily on technical detection alone.
Modular Representation Compression: Adapting LLMs for Efficient and Effective Recommendations
Apr 21, 2026Recently, large language models (LLMs) have advanced recommendation systems (RSs), and recent works have begun to explore how to integrate LLMs into industrial RSs. While most approaches deploy LLMs offline to generate and pre-cache augmented representations for RSs, high-dimensional representations from LLMs introduce substantial storage and computational costs. Thus, it is crucial to compress LLM representations effectively. However, we identify a counterintuitive phenomenon during representation compression: Mid-layer Representation Advantage (MRA), where representations from middle layers of LLMs outperform those from final layers in recommendation tasks. This degraded final layer renders existing compression methods, which typically compress on the final layer, suboptimal. We interpret this based on modularity theory that LLMs develop spontaneous internal functional modularity and force the final layer to specialize in the proxy training task. Thus, we propose \underline{M}odul\underline{a}r \underline{R}epresentation \underline{C}ompression (MARC) to explicitly control the modularity of LLMs. First, Modular Adjustment explicitly introduces compression and task adaptation modules, enabling the LLM to operate strictly as a representation-learning module. Next, to ground each module to its specific task, Modular Task Decoupling uses information constraints and different network structures to decouple tasks. Extensive experiments validate that MARC addresses MRA and produces efficient representations. Notably, MARC achieved a 2.82% eCPM lift in an online A/B test within a large-scale commercial search advertising scenario.
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Dec 31, 2025We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
The Real Barrier to LLM Agent Usability is Agentic ROI
May 23, 2025Large Language Model (LLM) agents represent a promising shift in human-AI interaction, moving beyond passive prompt-response systems to autonomous agents capable of reasoning, planning, and goal-directed action. Despite the widespread application in specialized, high-effort tasks like coding and scientific research, we highlight a critical usability gap in high-demand, mass-market applications. This position paper argues that the limited real-world adoption of LLM agents stems not only from gaps in model capabilities, but also from a fundamental tradeoff between the value an agent can provide and the costs incurred during real-world use. Hence, we call for a shift from solely optimizing model performance to a broader, utility-driven perspective: evaluating agents through the lens of the overall agentic return on investment (Agent ROI). By identifying key factors that determine Agentic ROI--information quality, agent time, and cost--we posit a zigzag development trajectory in optimizing agentic ROI: first scaling up to improve the information quality, then scaling down to minimize the time and cost. We outline the roadmap across different development stages to bridge the current usability gaps, aiming to make LLM agents truly scalable, accessible, and effective in real-world contexts.
Superplatforms Have to Attack AI Agents
May 23, 2025Over the past decades, superplatforms, digital companies that integrate a vast range of third-party services and applications into a single, unified ecosystem, have built their fortunes on monopolizing user attention through targeted advertising and algorithmic content curation. Yet the emergence of AI agents driven by large language models (LLMs) threatens to upend this business model. Agents can not only free user attention with autonomy across diverse platforms and therefore bypass the user-attention-based monetization, but might also become the new entrance for digital traffic. Hence, we argue that superplatforms have to attack AI agents to defend their centralized control of digital traffic entrance. Specifically, we analyze the fundamental conflict between user-attention-based monetization and agent-driven autonomy through the lens of our gatekeeping theory. We show how AI agents can disintermediate superplatforms and potentially become the next dominant gatekeepers, thereby forming the urgent necessity for superplatforms to proactively constrain and attack AI agents. Moreover, we go through the potential technologies for superplatform-initiated attacks, covering a brand-new, unexplored technical area with unique challenges. We have to emphasize that, despite our position, this paper does not advocate for adversarial attacks by superplatforms on AI agents, but rather offers an envisioned trend to highlight the emerging tensions between superplatforms and AI agents. Our aim is to raise awareness and encourage critical discussion for collaborative solutions, prioritizing user interests and perserving the openness of digital ecosystems in the age of AI agents.
InfoDeepSeek: Benchmarking Agentic Information Seeking for Retrieval-Augmented Generation
May 21, 2025Retrieval-Augmented Generation (RAG) enhances large language models (LLMs) by grounding responses with retrieved information. As an emerging paradigm, Agentic RAG further enhances this process by introducing autonomous LLM agents into the information seeking process. However, existing benchmarks fall short in evaluating such systems, as they are confined to a static retrieval environment with a fixed, limited corpus} and simple queries that fail to elicit agentic behavior. Moreover, their evaluation protocols assess information seeking effectiveness by pre-defined gold sets of documents, making them unsuitable for the open-ended and dynamic nature of real-world web environments. To bridge this gap, we present InfoDeepSeek, a new benchmark with challenging questions designed for assessing agentic information seeking in real-world, dynamic web environments. We propose a systematic methodology for constructing challenging queries satisfying the criteria of determinacy, difficulty, and diversity. Based on this, we develop the first evaluation framework tailored to dynamic agentic information seeking, including fine-grained metrics about the accuracy, utility, and compactness of information seeking outcomes. Through extensive experiments across LLMs, search engines, and question types, InfoDeepSeek reveals nuanced agent behaviors and offers actionable insights for future research.
Bursting Filter Bubble: Enhancing Serendipity Recommendations with Aligned Large Language Models
Feb 19, 2025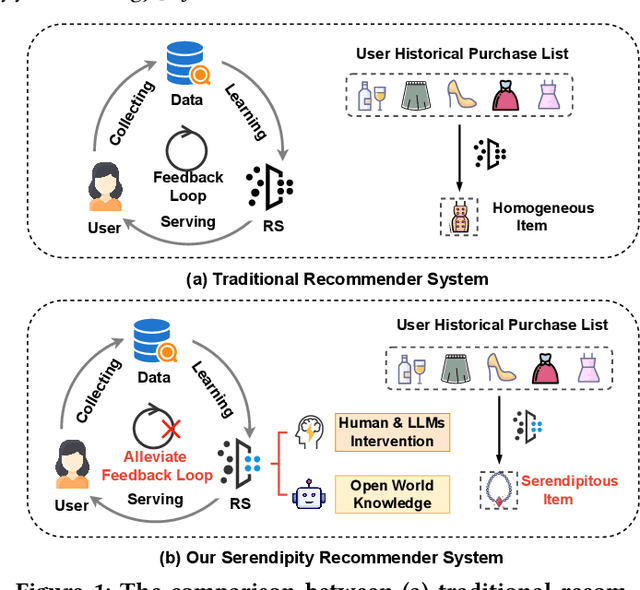
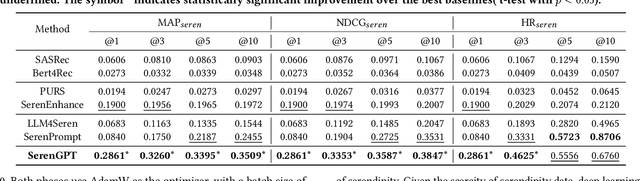
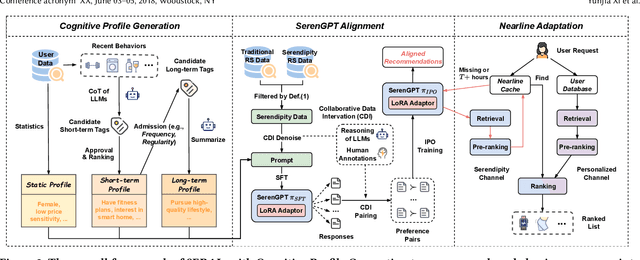
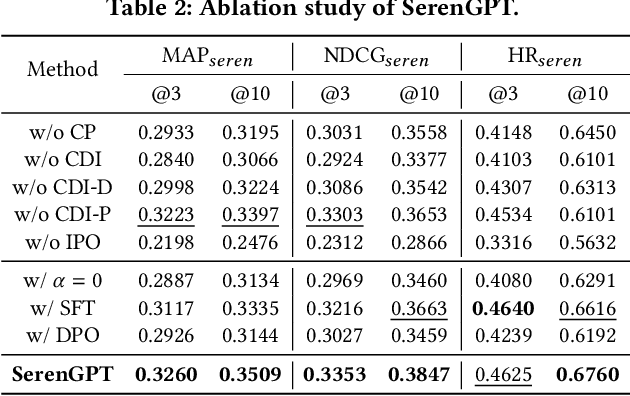
Recommender systems (RSs) often suffer from the feedback loop phenomenon, e.g., RSs are trained on data biased by their recommendations. This leads to the filter bubble effect that reinforces homogeneous content and reduces user satisfaction. To this end, serendipity recommendations, which offer unexpected yet relevant items, are proposed. Recently, large language models (LLMs) have shown potential in serendipity prediction due to their extensive world knowledge and reasoning capabilities. However, they still face challenges in aligning serendipity judgments with human assessments, handling long user behavior sequences, and meeting the latency requirements of industrial RSs. To address these issues, we propose SERAL (Serendipity Recommendations with Aligned Large Language Models), a framework comprising three stages: (1) Cognition Profile Generation to compress user behavior into multi-level profiles; (2) SerenGPT Alignment to align serendipity judgments with human preferences using enriched training data; and (3) Nearline Adaptation to integrate SerenGPT into industrial RSs pipelines efficiently. Online experiments demonstrate that SERAL improves exposure ratio (PVR), clicks, and transactions of serendipitous items by 5.7%, 29.56%, and 27.6%, enhancing user experience without much impact on overall revenue. Now, it has been fully deployed in the "Guess What You Like" of the Taobao App homepage.
LIBER: Lifelong User Behavior Modeling Based on Large Language Models
Nov 22, 2024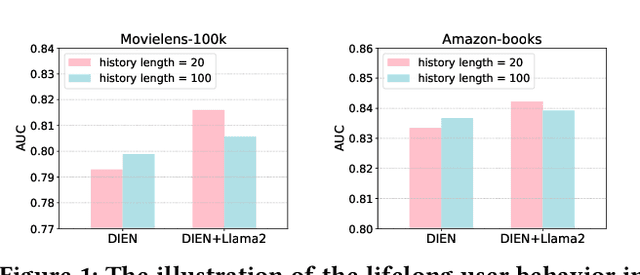
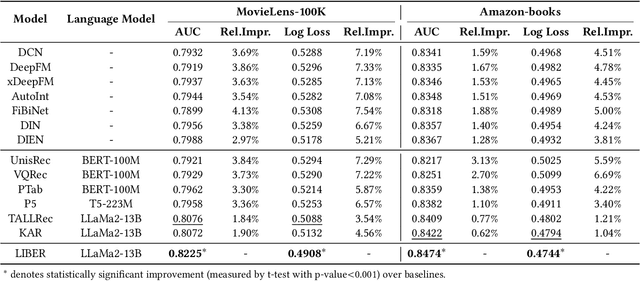
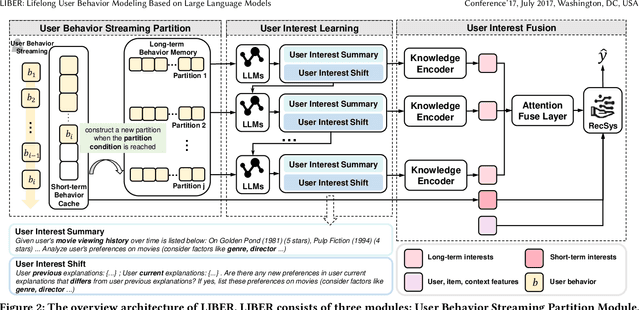
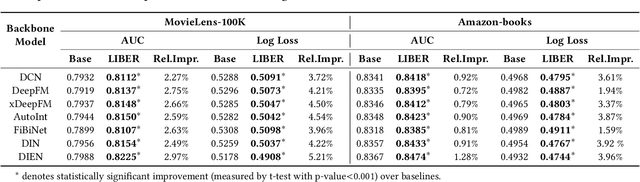
CTR prediction plays a vital role in recommender systems. Recently, large language models (LLMs) have been applied in recommender systems due to their emergence abilities. While leveraging semantic information from LLMs has shown some improvements in the performance of recommender systems, two notable limitations persist in these studies. First, LLM-enhanced recommender systems encounter challenges in extracting valuable information from lifelong user behavior sequences within textual contexts for recommendation tasks. Second, the inherent variability in human behaviors leads to a constant stream of new behaviors and irregularly fluctuating user interests. This characteristic imposes two significant challenges on existing models. On the one hand, it presents difficulties for LLMs in effectively capturing the dynamic shifts in user interests within these sequences, and on the other hand, there exists the issue of substantial computational overhead if the LLMs necessitate recurrent calls upon each update to the user sequences. In this work, we propose Lifelong User Behavior Modeling (LIBER) based on large language models, which includes three modules: (1) User Behavior Streaming Partition (UBSP), (2) User Interest Learning (UIL), and (3) User Interest Fusion (UIF). Initially, UBSP is employed to condense lengthy user behavior sequences into shorter partitions in an incremental paradigm, facilitating more efficient processing. Subsequently, UIL leverages LLMs in a cascading way to infer insights from these partitions. Finally, UIF integrates the textual outputs generated by the aforementioned processes to construct a comprehensive representation, which can be incorporated by any recommendation model to enhance performance. LIBER has been deployed on Huawei's music recommendation service and achieved substantial improvements in users' play count and play time by 3.01% and 7.69%.
Beyond Positive History: Re-ranking with List-level Hybrid Feedback
Oct 28, 2024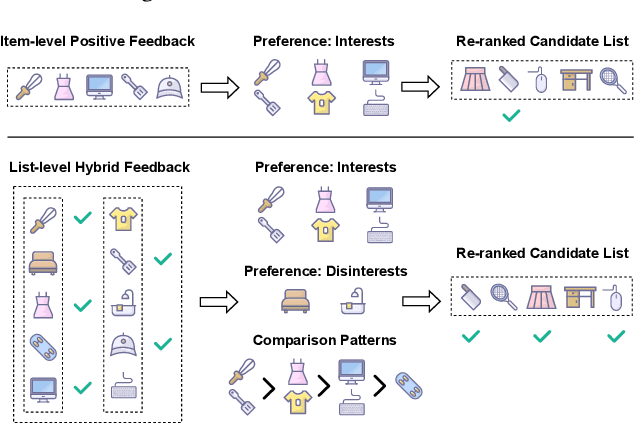
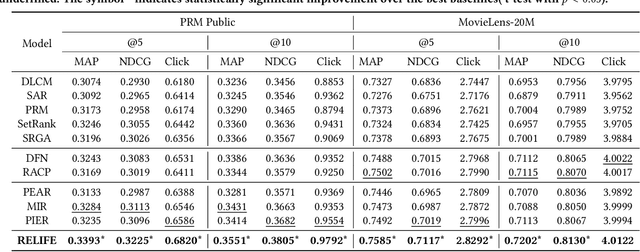
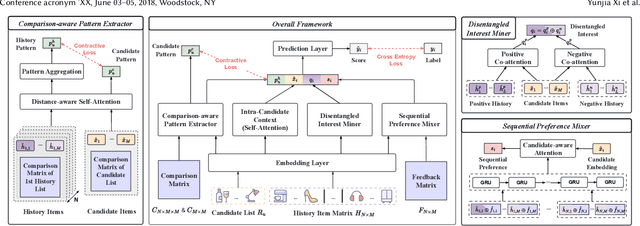
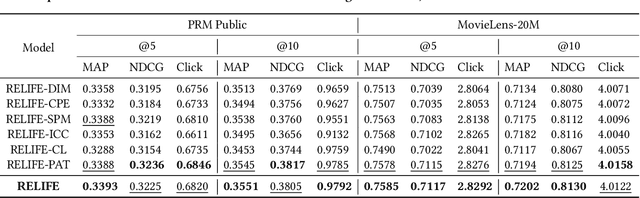
As the last stage of recommender systems, re-ranking generates a re-ordered list that aligns with the user's preference. However, previous works generally focus on item-level positive feedback as history (e.g., only clicked items) and ignore that users provide positive or negative feedback on items in the entire list. This list-level hybrid feedback can reveal users' holistic preferences and reflect users' comparison behavior patterns manifesting within a list. Such patterns could predict user behaviors on candidate lists, thus aiding better re-ranking. Despite appealing benefits, extracting and integrating preferences and behavior patterns from list-level hybrid feedback into re-ranking multiple items remains challenging. To this end, we propose Re-ranking with List-level Hybrid Feedback (dubbed RELIFE). It captures user's preferences and behavior patterns with three modules: a Disentangled Interest Miner to disentangle the user's preferences into interests and disinterests, a Sequential Preference Mixer to learn users' entangled preferences considering the context of feedback, and a Comparison-aware Pattern Extractor to capture user's behavior patterns within each list. Moreover, for better integration of patterns, contrastive learning is adopted to align the behavior patterns of candidate and historical lists. Extensive experiments show that RELIFE significantly outperforms SOTA re-ranking baselines.
A Survey on Diffusion Models for Recommender Systems
Sep 08, 2024



While traditional recommendation techniques have made significant strides in the past decades, they still suffer from limited generalization performance caused by factors like inadequate collaborative signals, weak latent representations, and noisy data. In response, diffusion models (DMs) have emerged as promising solutions for recommender systems due to their robust generative capabilities, solid theoretical foundations, and improved training stability. To this end, in this paper, we present the first comprehensive survey on diffusion models for recommendation, and draw a bird's-eye view from the perspective of the whole pipeline in real-world recommender systems. We systematically categorize existing research works into three primary domains: (1) diffusion for data engineering & encoding, focusing on data augmentation and representation enhancement; (2) diffusion as recommender models, employing diffusion models to directly estimate user preferences and rank items; and (3) diffusion for content presentation, utilizing diffusion models to generate personalized content such as fashion and advertisement creatives. Our taxonomy highlights the unique strengths of diffusion models in capturing complex data distributions and generating high-quality, diverse samples that closely align with user preferences. We also summarize the core characteristics of the adapting diffusion models for recommendation, and further identify key areas for future exploration, which helps establish a roadmap for researchers and practitioners seeking to advance recommender systems through the innovative application of diffusion models. To further facilitate the research community of recommender systems based on diffusion models, we actively maintain a GitHub repository for papers and other related resources in this rising direction https://github.com/CHIANGEL/Awesome-Diffusion-for-RecSys.