 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake It Long, Keep It Fast: End-to-End 10k-Sequence Modeling at Billion Scale on Douyin
Nov 08, 2025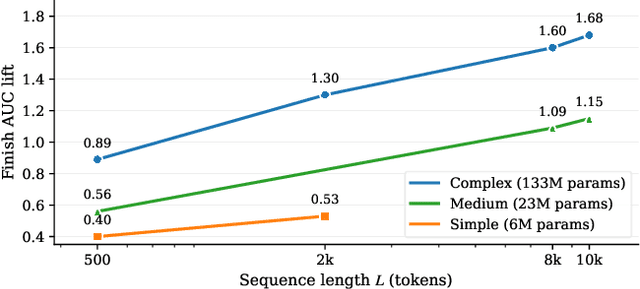
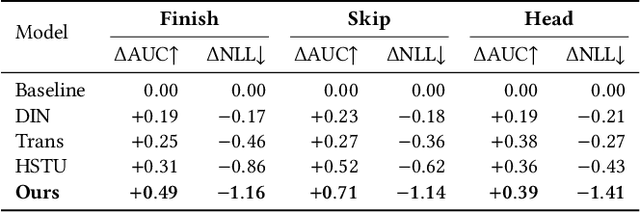
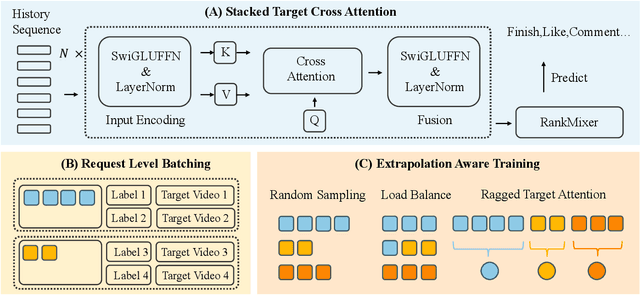

Short-video recommenders such as Douyin must exploit extremely long user histories without breaking latency or cost budgets. We present an end-to-end system that scales long-sequence modeling to 10k-length histories in production. First, we introduce Stacked Target-to-History Cross Attention (STCA), which replaces history self-attention with stacked cross-attention from the target to the history, reducing complexity from quadratic to linear in sequence length and enabling efficient end-to-end training. Second, we propose Request Level Batching (RLB), a user-centric batching scheme that aggregates multiple targets for the same user/request to share the user-side encoding, substantially lowering sequence-related storage, communication, and compute without changing the learning objective. Third, we design a length-extrapolative training strategy -- train on shorter windows, infer on much longer ones -- so the model generalizes to 10k histories without additional training cost. Across offline and online experiments, we observe predictable, monotonic gains as we scale history length and model capacity, mirroring the scaling law behavior observed in large language models. Deployed at full traffic on Douyin, our system delivers significant improvements on key engagement metrics while meeting production latency, demonstrating a practical path to scaling end-to-end long-sequence recommendation to the 10k regime.
A Decoding Acceleration Framework for Industrial Deployable LLM-based Recommender Systems
Aug 11, 2024Recently, increasing attention has been paid to LLM-based recommender systems, but their deployment is still under exploration in the industry. Most deployments utilize LLMs as feature enhancers, generating augmentation knowledge in the offline stage. However, in recommendation scenarios, involving numerous users and items, even offline generation with LLMs consumes considerable time and resources. This generation inefficiency stems from the autoregressive nature of LLMs, and a promising direction for acceleration is speculative decoding, a Draft-then-Verify paradigm that increases the number of generated tokens per decoding step. In this paper, we first identify that recommendation knowledge generation is suitable for retrieval-based speculative decoding. Then, we discern two characteristics: (1) extensive items and users in RSs bring retrieval inefficiency, and (2) RSs exhibit high diversity tolerance for text generated by LLMs. Based on the above insights, we propose a Decoding Acceleration Framework for LLM-based Recommendation (dubbed DARE), with Customized Retrieval Pool to improve retrieval efficiency and Relaxed Verification to increase the acceptance rate of draft tokens, respectively. Extensive experiments demonstrate that DARE achieves a 3-5x speedup and is compatible with various frameworks and backbone LLMs. DARE has also been deployed to online advertising scenarios within a large-scale commercial environment, achieving a 3.45x speedup while maintaining the downstream performance.
Towards Efficient and Effective Unlearning of Large Language Models for Recommendation
Mar 06, 2024The significant advancements in large language models (LLMs) give rise to a promising research direction, i.e., leveraging LLMs as recommenders (LLMRec). The efficacy of LLMRec arises from the open-world knowledge and reasoning capabilities inherent in LLMs. LLMRec acquires the recommendation capabilities through instruction tuning based on user interaction data. However, in order to protect user privacy and optimize utility, it is also crucial for LLMRec to intentionally forget specific user data, which is generally referred to as recommendation unlearning. In the era of LLMs, recommendation unlearning poses new challenges for LLMRec in terms of \textit{inefficiency} and \textit{ineffectiveness}. Existing unlearning methods require updating billions of parameters in LLMRec, which is costly and time-consuming. Besides, they always impact the model utility during the unlearning process. To this end, we propose \textbf{E2URec}, the first \underline{E}fficient and \underline{E}ffective \underline{U}nlearning method for LLM\underline{Rec}. Our proposed E2URec enhances the unlearning efficiency by updating only a few additional LoRA parameters, and improves the unlearning effectiveness by employing a teacher-student framework, where we maintain multiple teacher networks to guide the unlearning process. Extensive experiments show that E2URec outperforms state-of-the-art baselines on two real-world datasets. Specifically, E2URec can efficiently forget specific data without affecting recommendation performance. The source code is at \url{https://github.com/justarter/E2URec}.
ALT: Towards Fine-grained Alignment between Language and CTR Models for Click-Through Rate Prediction
Oct 30, 2023



Click-through rate (CTR) prediction plays as a core function module in various personalized online services. According to the data modality and input format, the models for CTR prediction can be mainly classified into two categories. The first one is the traditional CTR models that take as inputs the one-hot encoded ID features of tabular modality, which aims to capture the collaborative signals via feature interaction modeling. The second category takes as inputs the sentences of textual modality obtained by hard prompt templates, where pretrained language models (PLMs) are adopted to extract the semantic knowledge. These two lines of research generally focus on different characteristics of the same input data (i.e., textual and tabular modalities), forming a distinct complementary relationship with each other. Therefore, in this paper, we propose to conduct fine-grained feature-level Alignment between Language and CTR models (ALT) for CTR prediction. Apart from the common CLIP-like instance-level contrastive learning, we further design a novel joint reconstruction pretraining task for both masked language and tabular modeling. Specifically, the masked data of one modality (i.e., tokens or features) has to be recovered with the help of the other modality, which establishes the feature-level interaction and alignment via sufficient mutual information extraction between dual modalities. Moreover, we propose three different finetuning strategies with the option to train the aligned language and CTR models separately or jointly for downstream CTR prediction tasks, thus accommodating the varying efficacy and efficiency requirements for industrial applications. Extensive experiments on three real-world datasets demonstrate that ALT outperforms SOTA baselines, and is highly compatible for various language and CTR models.
ClickPrompt: CTR Models are Strong Prompt Generators for Adapting Language Models to CTR Prediction
Oct 17, 2023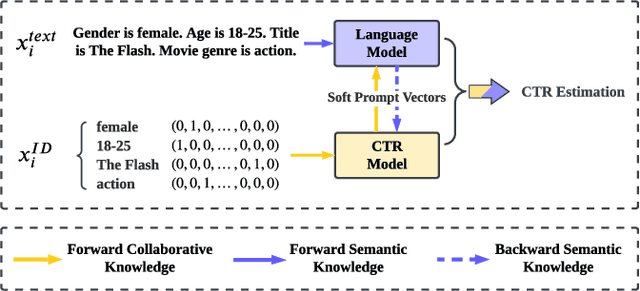
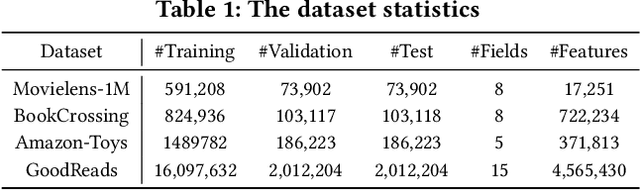
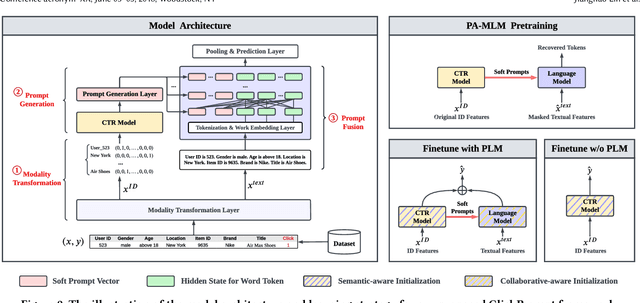
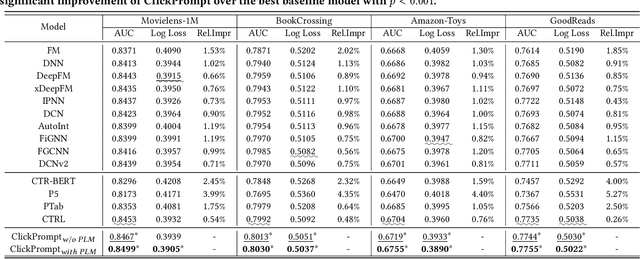
Click-through rate (CTR) prediction has become increasingly indispensable for various Internet applications. Traditional CTR models convert the multi-field categorical data into ID features via one-hot encoding, and extract the collaborative signals among features. Such a paradigm suffers from the problem of semantic information loss. Another line of research explores the potential of pretrained language models (PLMs) for CTR prediction by converting input data into textual sentences through hard prompt templates. Although semantic signals are preserved, they generally fail to capture the collaborative information (e.g., feature interactions, pure ID features), not to mention the unacceptable inference overhead brought by the huge model size. In this paper, we aim to model both the semantic knowledge and collaborative knowledge for accurate CTR estimation, and meanwhile address the inference inefficiency issue. To benefit from both worlds and close their gaps, we propose a novel model-agnostic framework (i.e., ClickPrompt), where we incorporate CTR models to generate interaction-aware soft prompts for PLMs. We design a prompt-augmented masked language modeling (PA-MLM) pretraining task, where PLM has to recover the masked tokens based on the language context, as well as the soft prompts generated by CTR model. The collaborative and semantic knowledge from ID and textual features would be explicitly aligned and interacted via the prompt interface. Then, we can either tune the CTR model with PLM for superior performance, or solely tune the CTR model without PLM for inference efficiency. Experiments on four real-world datasets validate the effectiveness of ClickPrompt compared with existing baselines.
GMOCAT: A Graph-Enhanced Multi-Objective Method for Computerized Adaptive Testing
Oct 11, 2023



Computerized Adaptive Testing(CAT) refers to an online system that adaptively selects the best-suited question for students with various abilities based on their historical response records. Most CAT methods only focus on the quality objective of predicting the student ability accurately, but neglect concept diversity or question exposure control, which are important considerations in ensuring the performance and validity of CAT. Besides, the students' response records contain valuable relational information between questions and knowledge concepts. The previous methods ignore this relational information, resulting in the selection of sub-optimal test questions. To address these challenges, we propose a Graph-Enhanced Multi-Objective method for CAT (GMOCAT). Firstly, three objectives, namely quality, diversity and novelty, are introduced into the Scalarized Multi-Objective Reinforcement Learning framework of CAT, which respectively correspond to improving the prediction accuracy, increasing the concept diversity and reducing the question exposure. We use an Actor-Critic Recommender to select questions and optimize three objectives simultaneously by the scalarization function. Secondly, we utilize the graph neural network to learn relation-aware embeddings of questions and concepts. These embeddings are able to aggregate neighborhood information in the relation graphs between questions and concepts. We conduct experiments on three real-world educational datasets, and show that GMOCAT not only outperforms the state-of-the-art methods in the ability prediction, but also achieve superior performance in improving the concept diversity and alleviating the question exposure. Our code is available at https://github.com/justarter/GMOCAT.