 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuyi2.5 Technical Report
Mar 18, 2026We present Ruyi2.5, a multimodal familial model built on the AI Flow framework. Extending Ruyi2's "Train Once, Deploy Many" paradigm to the multimodal domain, Ruyi2.5 constructs a shared-backbone architecture that co-trains models of varying scales within a single unified pipeline, ensuring semantic consistency across all deployment tiers. Built upon Ruyi2.5, Ruyi2.5-Camera model is developed as a privacy-preserving camera service system, which instantiates Ruyi2.5-Camera into a two-stage recognition pipeline: an edge model applies information-bottleneck-guided irreversible feature mapping to de-identify raw frames at the source, while a cloud model performs deep behavior reasoning. To accelerate reinforcement learning fine-tuning, we further propose Binary Prefix Policy Optimization (BPPO), which reduces sample redundancy via binary response selection and focuses gradient updates on response prefixes, achieving a 2 to 3 times training speedup over GRPO. Experiments show Ruyi2.5 matches Qwen3-VL on the general multimodal benchmarks, while Ruyi2.5-Camera substantially outperforms Qwen3-VL on privacy-constrained surveillance tasks.
Privacy-Aware Camera 2.0 Technical Report
Mar 05, 2026With the increasing deployment of intelligent sensing technologies in highly sensitive environments such as restrooms and locker rooms, visual surveillance systems face a profound privacy-security paradox. Existing privacy-preserving approaches, including physical desensitization, encryption, and obfuscation, often compromise semantic understanding or fail to ensure mathematically provable irreversibility. Although Privacy Camera 1.0 eliminated visual data at the source to prevent leakage, it provided only textual judgments, leading to evidentiary blind spots in disputes. To address these limitations, this paper proposes a novel privacy-preserving perception framework based on the AI Flow paradigm and a collaborative edge-cloud architecture. By deploying a visual desensitizer at the edge, raw images are transformed in real time into abstract feature vectors through nonlinear mapping and stochastic noise injection under the Information Bottleneck principle, ensuring identity-sensitive information is stripped and original images are mathematically unreconstructable. The abstract representations are transmitted to the cloud for behavior recognition and semantic reconstruction via a "dynamic contour" visual language, achieving a critical balance between perception and privacy while enabling illustrative visual reference without exposing raw images.
Theoretical Foundations of Scaling Law in Familial Models
Dec 29, 2025Neural scaling laws have become foundational for optimizing large language model (LLM) training, yet they typically assume a single dense model output. This limitation effectively overlooks "Familial models, a transformative paradigm essential for realizing ubiquitous intelligence across heterogeneous device-edge-cloud hierarchies. Transcending static architectures, familial models integrate early exits with relay-style inference to spawn G deployable sub-models from a single shared backbone. In this work, we theoretically and empirically extend the scaling law to capture this "one-run, many-models" paradigm by introducing Granularity (G) as a fundamental scaling variable alongside model size (N) and training tokens (D). To rigorously quantify this relationship, we propose a unified functional form L(N, D, G) and parameterize it using large-scale empirical runs. Specifically, we employ a rigorous IsoFLOP experimental design to strictly isolate architectural impact from computational scale. Across fixed budgets, we systematically sweep model sizes (N) and granularities (G) while dynamically adjusting tokens (D). This approach effectively decouples the marginal cost of granularity from the benefits of scale, ensuring high-fidelity parameterization of our unified scaling law. Our results reveal that the granularity penalty follows a multiplicative power law with an extremely small exponent. Theoretically, this bridges fixed-compute training with dynamic architectures. Practically, it validates the "train once, deploy many" paradigm, demonstrating that deployment flexibility is achievable without compromising the compute-optimality of dense baselines.
Constructing a Question-Answering Simulator through the Distillation of LLMs
Sep 11, 2025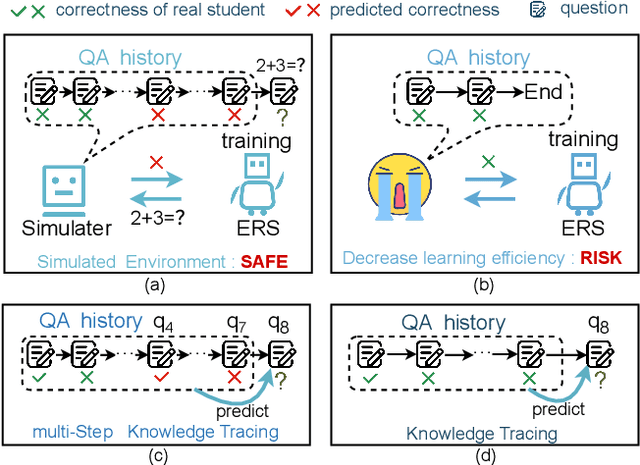
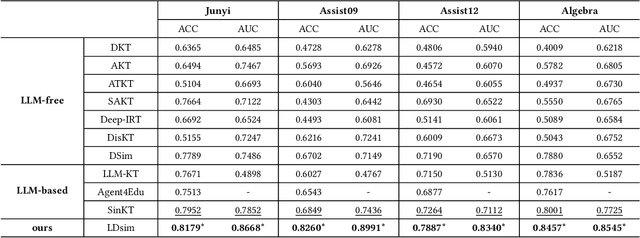
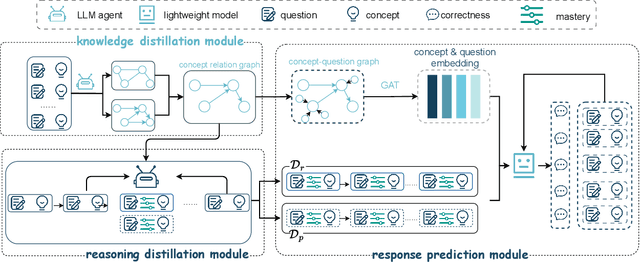
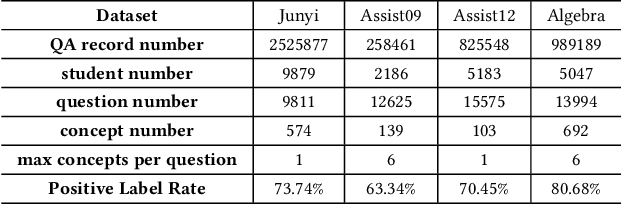
The question-answering (QA) simulator is a model that mimics real student learning behaviors and predicts their correctness of their responses to questions. QA simulators enable educational recommender systems (ERS) to collect large amounts of training data without interacting with real students, thereby preventing harmful recommendations made by an undertrained ERS from undermining actual student learning. Given the QA history, there are two categories of solutions to predict the correctness, conducting the simulation: (1) LLM-free methods, which apply a traditional sequential model to transfer the QA history into a vector representation first, and make predictions based on the representation; (2) LLM-based methods, which leverage the domain knowledge and reasoning capability of LLM to enhence the prediction. LLM-free methods offer fast inference but generally yield suboptimal performance. In contrast, most LLM-based methods achieve better results, but at the cost of slower inference speed and higher GPU memory consumption. In this paper, we propose a method named LLM Distillation based Simulator (LDSim), which distills domain knowledge and reasoning capability from an LLM to better assist prediction, thereby improving simulation performance. Extensive experiments demonstrate that our LDSim achieves strong results on both the simulation task and the knowledge tracing (KT) task. Our code is publicly available at https://anonymous.4open.science/r/LDSim-05A9.
Personalized Education with Ranking Alignment Recommendation
Jul 31, 2025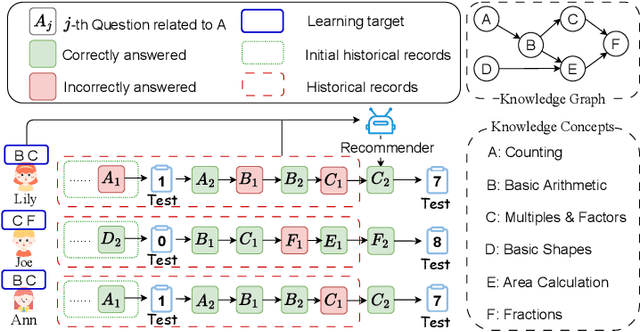
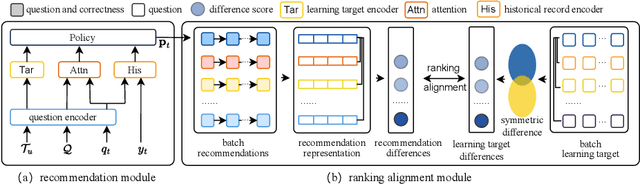
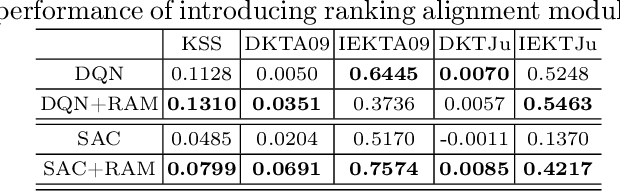
Personalized question recommendation aims to guide individual students through questions to enhance their mastery of learning targets. Most previous methods model this task as a Markov Decision Process and use reinforcement learning to solve, but they struggle with efficient exploration, failing to identify the best questions for each student during training. To address this, we propose Ranking Alignment Recommendation (RAR), which incorporates collaborative ideas into the exploration mechanism, enabling more efficient exploration within limited training episodes. Experiments show that RAR effectively improves recommendation performance, and our framework can be applied to any RL-based question recommender. Our code is available in https://github.com/wuming29/RAR.git.
AdvKT: An Adversarial Multi-Step Training Framework for Knowledge Tracing
Apr 07, 2025Knowledge Tracing (KT) monitors students' knowledge states and simulates their responses to question sequences. Existing KT models typically follow a single-step training paradigm, which leads to discrepancies with the multi-step inference process required in real-world simulations, resulting in significant error accumulation. This accumulation of error, coupled with the issue of data sparsity, can substantially degrade the performance of recommendation models in the intelligent tutoring systems. To address these challenges, we propose a novel Adversarial Multi-Step Training Framework for Knowledge Tracing (AdvKT), which, for the first time, focuses on the multi-step KT task. More specifically, AdvKT leverages adversarial learning paradigm involving a generator and a discriminator. The generator mimics high-reward responses, effectively reducing error accumulation across multiple steps, while the discriminator provides feedback to generate synthetic data. Additionally, we design specialized data augmentation techniques to enrich the training data with realistic variations, ensuring that the model generalizes well even in scenarios with sparse data. Experiments conducted on four real-world datasets demonstrate the superiority of AdvKT over existing KT models, showcasing its ability to address both error accumulation and data sparsity issues effectively.
HierLLM: Hierarchical Large Language Model for Question Recommendation
Sep 10, 2024



Question recommendation is a task that sequentially recommends questions for students to enhance their learning efficiency. That is, given the learning history and learning target of a student, a question recommender is supposed to select the question that will bring the most improvement for students. Previous methods typically model the question recommendation as a sequential decision-making problem, estimating students' learning state with the learning history, and feeding the learning state with the learning target to a neural network to select the recommended question from a question set. However, previous methods are faced with two challenges: (1) learning history is unavailable in the cold start scenario, which makes the recommender generate inappropriate recommendations; (2) the size of the question set is much large, which makes it difficult for the recommender to select the best question precisely. To address the challenges, we propose a method called hierarchical large language model for question recommendation (HierLLM), which is a LLM-based hierarchical structure. The LLM-based structure enables HierLLM to tackle the cold start issue with the strong reasoning abilities of LLM. The hierarchical structure takes advantage of the fact that the number of concepts is significantly smaller than the number of questions, narrowing the range of selectable questions by first identifying the relevant concept for the to-recommend question, and then selecting the recommended question based on that concept. This hierarchical structure reduces the difficulty of the recommendation.To investigate the performance of HierLLM, we conduct extensive experiments, and the results demonstrate the outstanding performance of HierLLM.
Contrastive Diffuser: Planning Towards High Return States via Contrastive Learning
Feb 06, 2024



Applying diffusion models in reinforcement learning for long-term planning has gained much attention recently. Several diffusion-based methods have successfully leveraged the modeling capabilities of diffusion for arbitrary distributions. These methods generate subsequent trajectories for planning and have demonstrated significant improvement. However, these methods are limited by their plain base distributions and their overlooking of the diversity of samples, in which different states have different returns. They simply leverage diffusion to learn the distribution of offline dataset, generate the trajectories whose states share the same distribution with the offline dataset. As a result, the probability of these models reaching the high-return states is largely dependent on the dataset distribution. Even equipped with the guidance model, the performance is still suppressed. To address these limitations, in this paper, we propose a novel method called CDiffuser, which devises a return contrast mechanism to pull the states in generated trajectories towards high-return states while pushing them away from low-return states to improve the base distribution. Experiments on 14 commonly used D4RL benchmarks demonstrate the effectiveness of our proposed method.
DiffStitch: Boosting Offline Reinforcement Learning with Diffusion-based Trajectory Stitching
Feb 04, 2024



In offline reinforcement learning (RL), the performance of the learned policy highly depends on the quality of offline datasets. However, in many cases, the offline dataset contains very limited optimal trajectories, which poses a challenge for offline RL algorithms as agents must acquire the ability to transit to high-reward regions. To address this issue, we introduce Diffusion-based Trajectory Stitching (DiffStitch), a novel diffusion-based data augmentation pipeline that systematically generates stitching transitions between trajectories. DiffStitch effectively connects low-reward trajectories with high-reward trajectories, forming globally optimal trajectories to address the challenges faced by offline RL algorithms. Empirical experiments conducted on D4RL datasets demonstrate the effectiveness of DiffStitch across RL methodologies. Notably, DiffStitch demonstrates substantial enhancements in the performance of one-step methods (IQL), imitation learning methods (TD3+BC), and trajectory optimization methods (DT).
GMOCAT: A Graph-Enhanced Multi-Objective Method for Computerized Adaptive Testing
Oct 11, 2023



Computerized Adaptive Testing(CAT) refers to an online system that adaptively selects the best-suited question for students with various abilities based on their historical response records. Most CAT methods only focus on the quality objective of predicting the student ability accurately, but neglect concept diversity or question exposure control, which are important considerations in ensuring the performance and validity of CAT. Besides, the students' response records contain valuable relational information between questions and knowledge concepts. The previous methods ignore this relational information, resulting in the selection of sub-optimal test questions. To address these challenges, we propose a Graph-Enhanced Multi-Objective method for CAT (GMOCAT). Firstly, three objectives, namely quality, diversity and novelty, are introduced into the Scalarized Multi-Objective Reinforcement Learning framework of CAT, which respectively correspond to improving the prediction accuracy, increasing the concept diversity and reducing the question exposure. We use an Actor-Critic Recommender to select questions and optimize three objectives simultaneously by the scalarization function. Secondly, we utilize the graph neural network to learn relation-aware embeddings of questions and concepts. These embeddings are able to aggregate neighborhood information in the relation graphs between questions and concepts. We conduct experiments on three real-world educational datasets, and show that GMOCAT not only outperforms the state-of-the-art methods in the ability prediction, but also achieve superior performance in improving the concept diversity and alleviating the question exposure. Our code is available at https://github.com/justarter/GMOCAT.