 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking inside the Convolution for Image Inpainting: Reconstructing Texture via Structure under Global and Local Side
Feb 03, 2026Image inpainting has earned substantial progress, owing to the encoder-and-decoder pipeline, which is benefited from the Convolutional Neural Networks (CNNs) with convolutional downsampling to inpaint the masked regions semantically from the known regions within the encoder, coupled with an upsampling process from the decoder for final inpainting output. Recent studies intuitively identify the high-frequency structure and low-frequency texture to be extracted by CNNs from the encoder, and subsequently for a desirable upsampling recovery. However, the existing arts inevitably overlook the information loss for both structure and texture feature maps during the convolutional downsampling process, hence suffer from a non-ideal upsampling output. In this paper, we systematically answer whether and how the structure and texture feature map can mutually help to alleviate the information loss during the convolutional downsampling. Given the structure and texture feature maps, we adopt the statistical normalization and denormalization strategy for the reconstruction guidance during the convolutional downsampling process. The extensive experimental results validate its advantages to the state-of-the-arts over the images from low-to-high resolutions including 256*256 and 512*512, especially holds by substituting all the encoders by ours. Our code is available at https://github.com/htyjers/ConvInpaint-TSGL
Constructing a Question-Answering Simulator through the Distillation of LLMs
Sep 11, 2025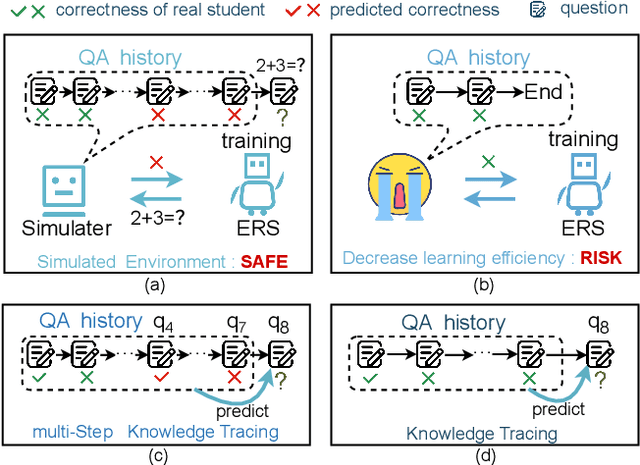
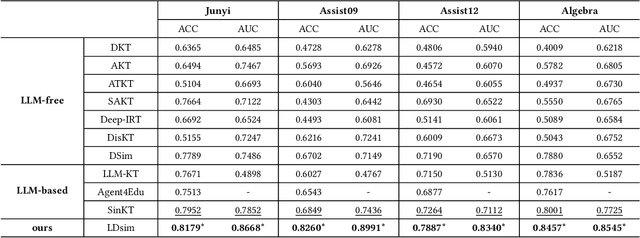
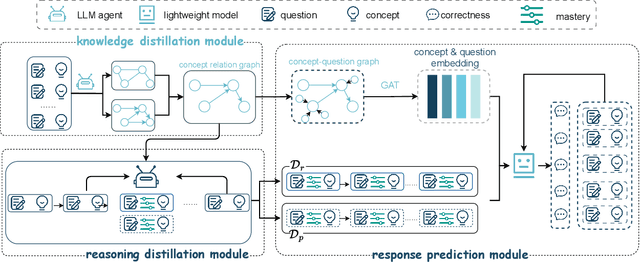
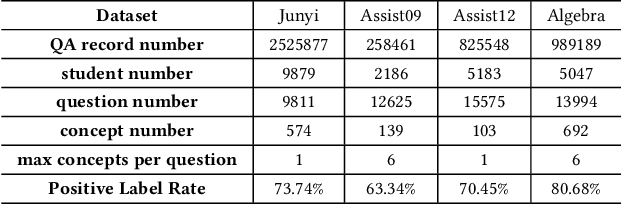
The question-answering (QA) simulator is a model that mimics real student learning behaviors and predicts their correctness of their responses to questions. QA simulators enable educational recommender systems (ERS) to collect large amounts of training data without interacting with real students, thereby preventing harmful recommendations made by an undertrained ERS from undermining actual student learning. Given the QA history, there are two categories of solutions to predict the correctness, conducting the simulation: (1) LLM-free methods, which apply a traditional sequential model to transfer the QA history into a vector representation first, and make predictions based on the representation; (2) LLM-based methods, which leverage the domain knowledge and reasoning capability of LLM to enhence the prediction. LLM-free methods offer fast inference but generally yield suboptimal performance. In contrast, most LLM-based methods achieve better results, but at the cost of slower inference speed and higher GPU memory consumption. In this paper, we propose a method named LLM Distillation based Simulator (LDSim), which distills domain knowledge and reasoning capability from an LLM to better assist prediction, thereby improving simulation performance. Extensive experiments demonstrate that our LDSim achieves strong results on both the simulation task and the knowledge tracing (KT) task. Our code is publicly available at https://anonymous.4open.science/r/LDSim-05A9.
Personalized Education with Ranking Alignment Recommendation
Jul 31, 2025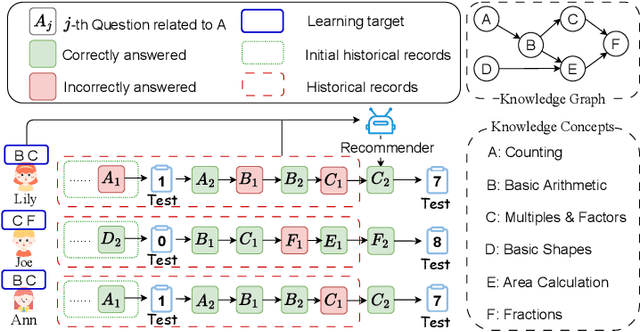
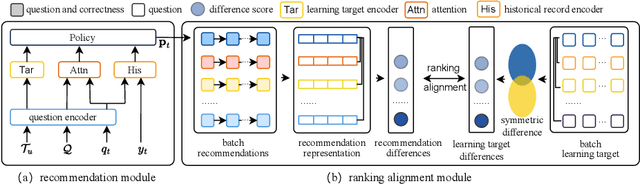
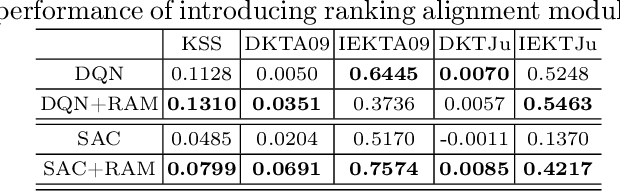
Personalized question recommendation aims to guide individual students through questions to enhance their mastery of learning targets. Most previous methods model this task as a Markov Decision Process and use reinforcement learning to solve, but they struggle with efficient exploration, failing to identify the best questions for each student during training. To address this, we propose Ranking Alignment Recommendation (RAR), which incorporates collaborative ideas into the exploration mechanism, enabling more efficient exploration within limited training episodes. Experiments show that RAR effectively improves recommendation performance, and our framework can be applied to any RL-based question recommender. Our code is available in https://github.com/wuming29/RAR.git.
MDE-Edit: Masked Dual-Editing for Multi-Object Image Editing via Diffusion Models
May 08, 2025Multi-object editing aims to modify multiple objects or regions in complex scenes while preserving structural coherence. This task faces significant challenges in scenarios involving overlapping or interacting objects: (1) Inaccurate localization of target objects due to attention misalignment, leading to incomplete or misplaced edits; (2) Attribute-object mismatch, where color or texture changes fail to align with intended regions due to cross-attention leakage, creating semantic conflicts (\textit{e.g.}, color bleeding into non-target areas). Existing methods struggle with these challenges: approaches relying on global cross-attention mechanisms suffer from attention dilution and spatial interference between objects, while mask-based methods fail to bind attributes to geometrically accurate regions due to feature entanglement in multi-object scenarios. To address these limitations, we propose a training-free, inference-stage optimization approach that enables precise localized image manipulation in complex multi-object scenes, named MDE-Edit. MDE-Edit optimizes the noise latent feature in diffusion models via two key losses: Object Alignment Loss (OAL) aligns multi-layer cross-attention with segmentation masks for precise object positioning, and Color Consistency Loss (CCL) amplifies target attribute attention within masks while suppressing leakage to adjacent regions. This dual-loss design ensures localized and coherent multi-object edits. Extensive experiments demonstrate that MDE-Edit outperforms state-of-the-art methods in editing accuracy and visual quality, offering a robust solution for complex multi-object image manipulation tasks.
PIDiff: Image Customization for Personalized Identities with Diffusion Models
May 08, 2025Text-to-image generation for personalized identities aims at incorporating the specific identity into images using a text prompt and an identity image. Based on the powerful generative capabilities of DDPMs, many previous works adopt additional prompts, such as text embeddings and CLIP image embeddings, to represent the identity information, while they fail to disentangle the identity information and background information. As a result, the generated images not only lose key identity characteristics but also suffer from significantly reduced diversity. To address this issue, previous works have combined the W+ space from StyleGAN with diffusion models, leveraging this space to provide a more accurate and comprehensive representation of identity features through multi-level feature extraction. However, the entanglement of identity and background information in in-the-wild images during training prevents accurate identity localization, resulting in severe semantic interference between identity and background. In this paper, we propose a novel fine-tuning-based diffusion model for personalized identities text-to-image generation, named PIDiff, which leverages the W+ space and an identity-tailored fine-tuning strategy to avoid semantic entanglement and achieves accurate feature extraction and localization. Style editing can also be achieved by PIDiff through preserving the characteristics of identity features in the W+ space, which vary from coarse to fine. Through the combination of the proposed cross-attention block and parameter optimization strategy, PIDiff preserves the identity information and maintains the generation capability for in-the-wild images of the pre-trained model during inference. Our experimental results validate the effectiveness of our method in this task.
VLM-E2E: Enhancing End-to-End Autonomous Driving with Multimodal Driver Attention Fusion
Feb 25, 2025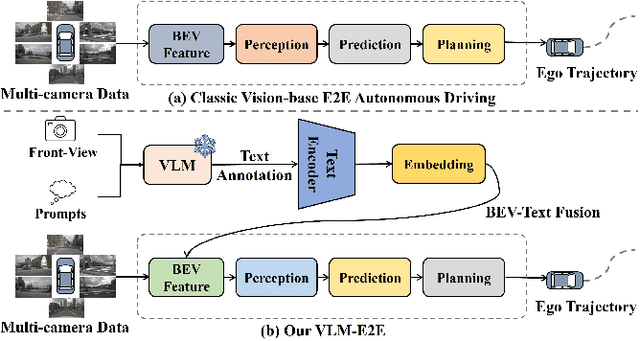
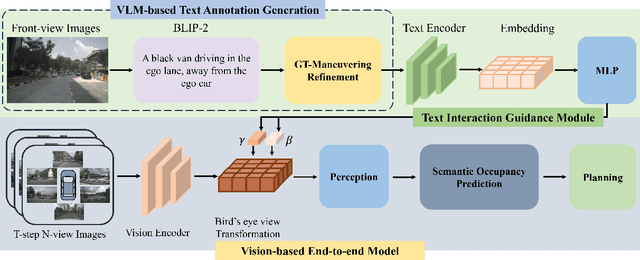
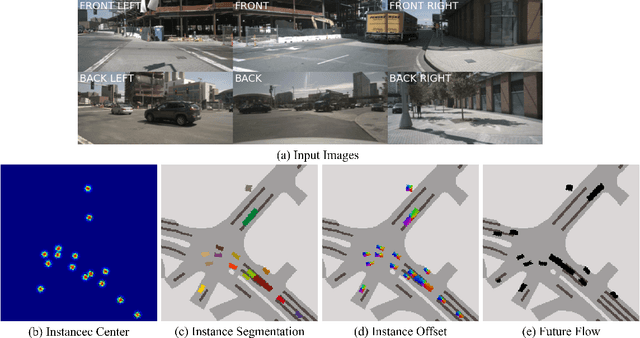
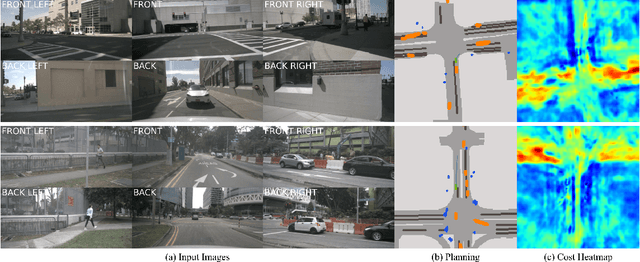
Human drivers adeptly navigate complex scenarios by utilizing rich attentional semantics, but the current autonomous systems struggle to replicate this ability, as they often lose critical semantic information when converting 2D observations into 3D space. In this sense, it hinders their effective deployment in dynamic and complex environments. Leveraging the superior scene understanding and reasoning abilities of Vision-Language Models (VLMs), we propose VLM-E2E, a novel framework that uses the VLMs to enhance training by providing attentional cues. Our method integrates textual representations into Bird's-Eye-View (BEV) features for semantic supervision, which enables the model to learn richer feature representations that explicitly capture the driver's attentional semantics. By focusing on attentional semantics, VLM-E2E better aligns with human-like driving behavior, which is critical for navigating dynamic and complex environments. Furthermore, we introduce a BEV-Text learnable weighted fusion strategy to address the issue of modality importance imbalance in fusing multimodal information. This approach dynamically balances the contributions of BEV and text features, ensuring that the complementary information from visual and textual modality is effectively utilized. By explicitly addressing the imbalance in multimodal fusion, our method facilitates a more holistic and robust representation of driving environments. We evaluate VLM-E2E on the nuScenes dataset and demonstrate its superiority over state-of-the-art approaches, showcasing significant improvements in performance.
Coarse-to-Fine Lightweight Meta-Embedding for ID-Based Recommendation
Jan 21, 2025



The state-of-the-art recommendation systems have shifted the attention to efficient recommendation, e.g., on-device recommendation, under memory constraints. To this end, the existing methods either focused on the lightweight embeddings for both users and items, or involved on-device systems enjoying the compact embeddings to enhance reusability and reduces space complexity. However, they focus solely on the coarse granularity of embedding, while overlook the fine-grained semantic nuances, to adversarially downgrade the efficacy of meta-embeddings in capturing the intricate relationship over both user and item, consequently resulting into the suboptimal recommendations. In this paper, we aim to study how the meta-embedding can efficiently learn varied grained semantics, together with how the fine-grained meta-embedding can strengthen the representation of coarse-grained meta-embedding. To answer these questions, we develop a novel graph neural networks (GNNs) based recommender where each user and item serves as the node, linked directly to coarse-grained virtual nodes and indirectly to fine-grained virtual nodes, ensuring different grained semantic learning, while disclosing: 1) In contrast to coarse-grained semantics, fine-grained semantics are well captured through sparse meta-embeddings, which adaptively 2) balance the embedding uniqueness and memory constraint. Additionally, the initialization method come up upon SparsePCA, along with a soft thresholding activation function to render the sparseness of the meta-embeddings. We propose a weight bridging update strategy that focuses on matching each coarse-grained meta-embedding with several fine-grained meta-embeddings based on the users/items' semantics. Extensive experiments substantiate our method's superiority over existing baselines. Our code is available at https://github.com/htyjers/C2F-MetaEmbed.
Traj-Explainer: An Explainable and Robust Multi-modal Trajectory Prediction Approach
Oct 22, 2024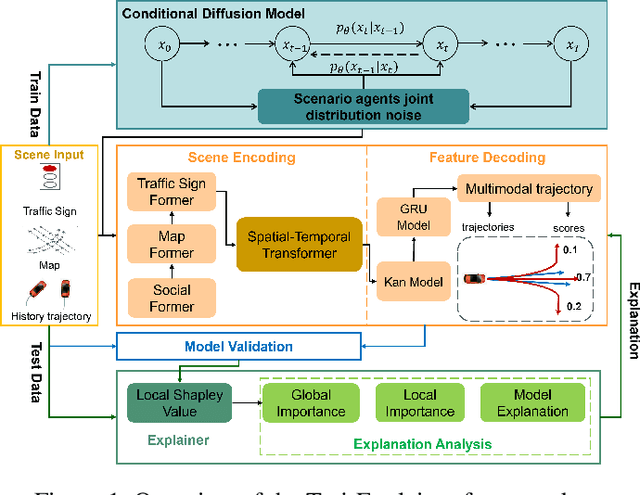
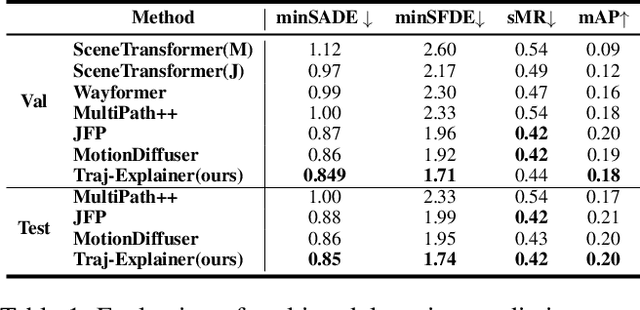

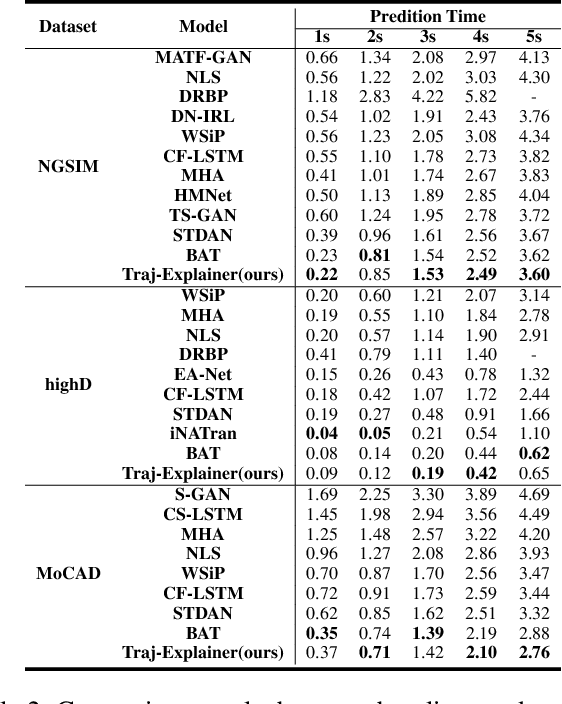
Navigating complex traffic environments has been significantly enhanced by advancements in intelligent technologies, enabling accurate environment perception and trajectory prediction for automated vehicles. However, existing research often neglects the consideration of the joint reasoning of scenario agents and lacks interpretability in trajectory prediction models, thereby limiting their practical application in real-world scenarios. To this purpose, an explainability-oriented trajectory prediction model is designed in this work, named Explainable Conditional Diffusion based Multimodal Trajectory Prediction Traj-Explainer, to retrieve the influencing factors of prediction and help understand the intrinsic mechanism of prediction. In Traj-Explainer, a modified conditional diffusion is well designed to capture the scenario multimodal trajectory pattern, and meanwhile, a modified Shapley Value model is assembled to rationally learn the importance of the global and scenario features. Numerical experiments are carried out by several trajectory prediction datasets, including Waymo, NGSIM, HighD, and MoCAD datasets. Furthermore, we evaluate the identified input factors which indicates that they are in agreement with the human driving experience, indicating the capability of the proposed model in appropriately learning the prediction. Code available in our open-source repository: \url{https://anonymous.4open.science/r/Interpretable-Prediction}.
HeightFormer: A Semantic Alignment Monocular 3D Object Detection Method from Roadside Perspective
Oct 10, 2024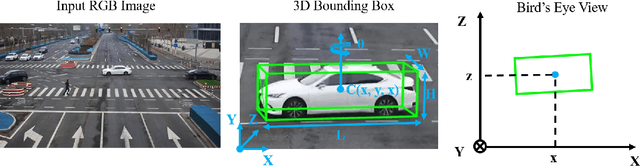
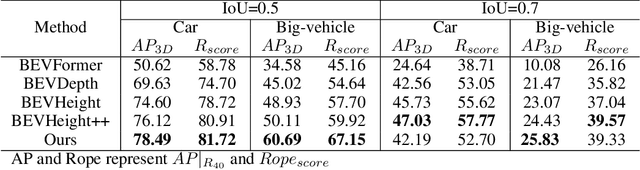
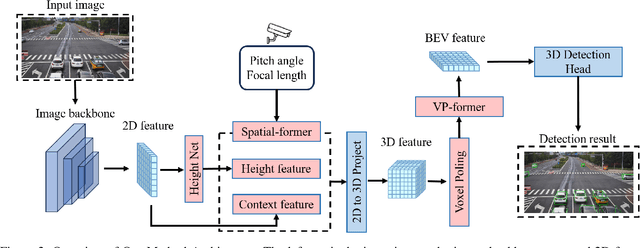
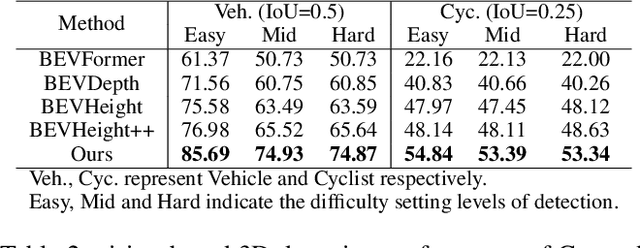
The on-board 3D object detection technology has received extensive attention as a critical technology for autonomous driving, while few studies have focused on applying roadside sensors in 3D traffic object detection. Existing studies achieve the projection of 2D image features to 3D features through height estimation based on the frustum. However, they did not consider the height alignment and the extraction efficiency of bird's-eye-view features. We propose a novel 3D object detection framework integrating Spatial Former and Voxel Pooling Former to enhance 2D-to-3D projection based on height estimation. Extensive experiments were conducted using the Rope3D and DAIR-V2X-I dataset, and the results demonstrated the outperformance of the proposed algorithm in the detection of both vehicles and cyclists. These results indicate that the algorithm is robust and generalized under various detection scenarios. Improving the accuracy of 3D object detection on the roadside is conducive to building a safe and trustworthy intelligent transportation system of vehicle-road coordination and promoting the large-scale application of autonomous driving. The code and pre-trained models will be released on https://anonymous.4open.science/r/HeightFormer.
HierLLM: Hierarchical Large Language Model for Question Recommendation
Sep 10, 2024



Question recommendation is a task that sequentially recommends questions for students to enhance their learning efficiency. That is, given the learning history and learning target of a student, a question recommender is supposed to select the question that will bring the most improvement for students. Previous methods typically model the question recommendation as a sequential decision-making problem, estimating students' learning state with the learning history, and feeding the learning state with the learning target to a neural network to select the recommended question from a question set. However, previous methods are faced with two challenges: (1) learning history is unavailable in the cold start scenario, which makes the recommender generate inappropriate recommendations; (2) the size of the question set is much large, which makes it difficult for the recommender to select the best question precisely. To address the challenges, we propose a method called hierarchical large language model for question recommendation (HierLLM), which is a LLM-based hierarchical structure. The LLM-based structure enables HierLLM to tackle the cold start issue with the strong reasoning abilities of LLM. The hierarchical structure takes advantage of the fact that the number of concepts is significantly smaller than the number of questions, narrowing the range of selectable questions by first identifying the relevant concept for the to-recommend question, and then selecting the recommended question based on that concept. This hierarchical structure reduces the difficulty of the recommendation.To investigate the performance of HierLLM, we conduct extensive experiments, and the results demonstrate the outstanding performance of HierLLM.