 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMostly Text, Smart Visuals: Asymmetric Text-Visual Pruning for Large Vision-Language Models
Mar 16, 2026Network pruning is an effective technique for enabling lightweight Large Vision-Language Models (LVLMs), which primarily incorporates both weights and activations into the importance metric. However, existing efforts typically process calibration data from different modalities in a unified manner, overlooking modality-specific behaviors. This raises a critical challenge: how to address the divergent behaviors of textual and visual tokens for accurate pruning of LVLMs. To this end, we systematically investigate the sensitivity of visual and textual tokens to the pruning operation by decoupling their corresponding weights, revealing that: (i) the textual pathway should be calibrated via text tokens, since it exhibits higher sensitivity than the visual pathway; (ii) the visual pathway exhibits high redundancy, permitting even 50% sparsity. Motivated by these insights, we propose a simple yet effective Asymmetric Text-Visual Weight Pruning method for LVLMs, dubbed ATV-Pruning, which establishes the importance metric for accurate weight pruning by selecting the informative tokens from both textual and visual pathways. Specifically, ATV-Pruning integrates two primary innovations: first, a calibration pool is adaptively constructed by drawing on all textual tokens and a subset of visual tokens; second, we devise a layer-adaptive selection strategy to yield important visual tokens. Finally, extensive experiments across standard multimodal benchmarks verify the superiority of our ATV-Pruning over state-of-the-art methods.
Thinking inside the Convolution for Image Inpainting: Reconstructing Texture via Structure under Global and Local Side
Feb 03, 2026Image inpainting has earned substantial progress, owing to the encoder-and-decoder pipeline, which is benefited from the Convolutional Neural Networks (CNNs) with convolutional downsampling to inpaint the masked regions semantically from the known regions within the encoder, coupled with an upsampling process from the decoder for final inpainting output. Recent studies intuitively identify the high-frequency structure and low-frequency texture to be extracted by CNNs from the encoder, and subsequently for a desirable upsampling recovery. However, the existing arts inevitably overlook the information loss for both structure and texture feature maps during the convolutional downsampling process, hence suffer from a non-ideal upsampling output. In this paper, we systematically answer whether and how the structure and texture feature map can mutually help to alleviate the information loss during the convolutional downsampling. Given the structure and texture feature maps, we adopt the statistical normalization and denormalization strategy for the reconstruction guidance during the convolutional downsampling process. The extensive experimental results validate its advantages to the state-of-the-arts over the images from low-to-high resolutions including 256*256 and 512*512, especially holds by substituting all the encoders by ours. Our code is available at https://github.com/htyjers/ConvInpaint-TSGL
Coarse-to-Fine Lightweight Meta-Embedding for ID-Based Recommendation
Jan 21, 2025



The state-of-the-art recommendation systems have shifted the attention to efficient recommendation, e.g., on-device recommendation, under memory constraints. To this end, the existing methods either focused on the lightweight embeddings for both users and items, or involved on-device systems enjoying the compact embeddings to enhance reusability and reduces space complexity. However, they focus solely on the coarse granularity of embedding, while overlook the fine-grained semantic nuances, to adversarially downgrade the efficacy of meta-embeddings in capturing the intricate relationship over both user and item, consequently resulting into the suboptimal recommendations. In this paper, we aim to study how the meta-embedding can efficiently learn varied grained semantics, together with how the fine-grained meta-embedding can strengthen the representation of coarse-grained meta-embedding. To answer these questions, we develop a novel graph neural networks (GNNs) based recommender where each user and item serves as the node, linked directly to coarse-grained virtual nodes and indirectly to fine-grained virtual nodes, ensuring different grained semantic learning, while disclosing: 1) In contrast to coarse-grained semantics, fine-grained semantics are well captured through sparse meta-embeddings, which adaptively 2) balance the embedding uniqueness and memory constraint. Additionally, the initialization method come up upon SparsePCA, along with a soft thresholding activation function to render the sparseness of the meta-embeddings. We propose a weight bridging update strategy that focuses on matching each coarse-grained meta-embedding with several fine-grained meta-embeddings based on the users/items' semantics. Extensive experiments substantiate our method's superiority over existing baselines. Our code is available at https://github.com/htyjers/C2F-MetaEmbed.
Structure Matters: Tackling the Semantic Discrepancy in Diffusion Models for Image Inpainting
Apr 01, 2024Denoising diffusion probabilistic models for image inpainting aim to add the noise to the texture of image during the forward process and recover masked regions with unmasked ones of the texture via the reverse denoising process.Despite the meaningful semantics generation,the existing arts suffer from the semantic discrepancy between masked and unmasked regions, since the semantically dense unmasked texture fails to be completely degraded while the masked regions turn to the pure noise in diffusion process,leading to the large discrepancy between them. In this paper,we aim to answer how unmasked semantics guide texture denoising process;together with how to tackle the semantic discrepancy,to facilitate the consistent and meaningful semantics generation. To this end,we propose a novel structure-guided diffusion model named StrDiffusion,to reformulate the conventional texture denoising process under structure guidance to derive a simplified denoising objective for image inpainting,while revealing:1)the semantically sparse structure is beneficial to tackle semantic discrepancy in early stage, while dense texture generates reasonable semantics in late stage;2)the semantics from unmasked regions essentially offer the time-dependent structure guidance for the texture denoising process,benefiting from the time-dependent sparsity of the structure semantics.For the denoising process,a structure-guided neural network is trained to estimate the simplified denoising objective by exploiting the consistency of the denoised structure between masked and unmasked regions.Besides,we devise an adaptive resampling strategy as a formal criterion as whether structure is competent to guide the texture denoising process,while regulate their semantic correlations.Extensive experiments validate the merits of StrDiffusion over the state-of-the-arts.Our code is available at https://github.com/htyjers/StrDiffusion.
Adaptive Data-Free Quantization
Mar 20, 2023



Data-free quantization (DFQ) recovers the performance of quantized network (Q) without the original data, but generates the fake sample via a generator (G) by learning from full-precision network (P), which, however, is totally independent of Q, overlooking the adaptability of the knowledge from generated samples, i.e., informative or not to the learning process of Q, resulting into the overflow of generalization error. Building on this, several critical questions -- how to measure the sample adaptability to Q under varied bit-width scenarios? whether the largest adaptability is the best? how to generate the samples with adaptive adaptability to improve Q's generalization? To answer the above questions, in this paper, we propose an Adaptive Data-Free Quantization (AdaDFQ) method, which revisits DFQ from a zero-sum game perspective upon the sample adaptability between two players -- a generator and a quantized network. Following this viewpoint, we further define the disagreement and agreement samples to form two boundaries, where the margin is optimized to adaptively regulate the adaptability of generated samples to Q, so as to address the over-and-under fitting issues. Our AdaDFQ reveals: 1) the largest adaptability is NOT the best for sample generation to benefit Q's generalization; 2) the knowledge of the generated sample should not be informative to Q only, but also related to the category and distribution information of the training data for P. The theoretical and empirical analysis validate the advantages of AdaDFQ over the state-of-the-arts. Our code is available at https://github.com/hfutqian/AdaDFQ.
Fine-grained Cross-modal Fusion based Refinement for Text-to-Image Synthesis
Feb 20, 2023



Text-to-image synthesis refers to generating visual-realistic and semantically consistent images from given textual descriptions. Previous approaches generate an initial low-resolution image and then refine it to be high-resolution. Despite the remarkable progress, these methods are limited in fully utilizing the given texts and could generate text-mismatched images, especially when the text description is complex. We propose a novel Fine-grained text-image Fusion based Generative Adversarial Networks, dubbed FF-GAN, which consists of two modules: Fine-grained text-image Fusion Block (FF-Block) and Global Semantic Refinement (GSR). The proposed FF-Block integrates an attention block and several convolution layers to effectively fuse the fine-grained word-context features into the corresponding visual features, in which the text information is fully used to refine the initial image with more details. And the GSR is proposed to improve the global semantic consistency between linguistic and visual features during the refinement process. Extensive experiments on CUB-200 and COCO datasets demonstrate the superiority of FF-GAN over other state-of-the-art approaches in generating images with semantic consistency to the given texts.Code is available at https://github.com/haoranhfut/FF-GAN.
Rethinking Data-Free Quantization as a Zero-Sum Game
Feb 19, 2023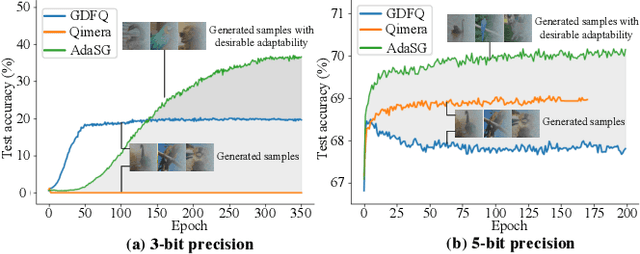
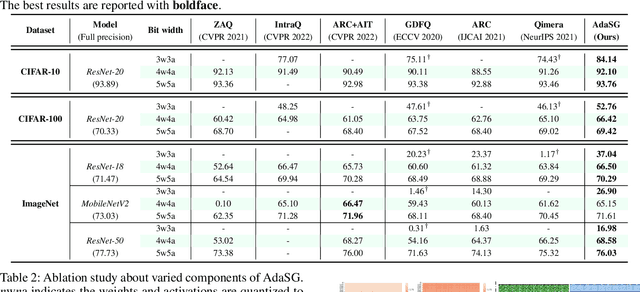
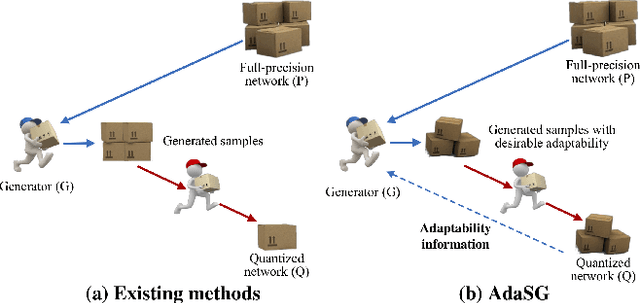
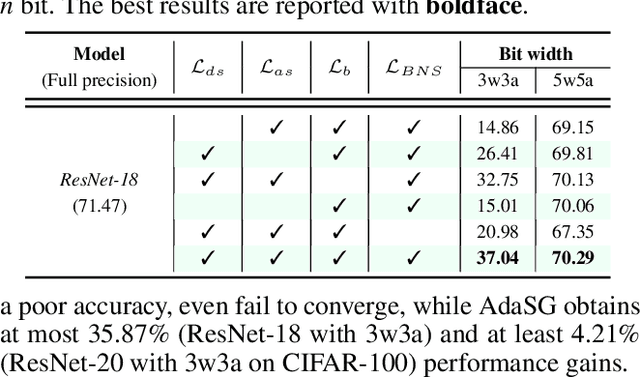
Data-free quantization (DFQ) recovers the performance of quantized network (Q) without accessing the real data, but generates the fake sample via a generator (G) by learning from full-precision network (P) instead. However, such sample generation process is totally independent of Q, specialized as failing to consider the adaptability of the generated samples, i.e., beneficial or adversarial, over the learning process of Q, resulting into non-ignorable performance loss. Building on this, several crucial questions -- how to measure and exploit the sample adaptability to Q under varied bit-width scenarios? how to generate the samples with desirable adaptability to benefit the quantized network? -- impel us to revisit DFQ. In this paper, we answer the above questions from a game-theory perspective to specialize DFQ as a zero-sum game between two players -- a generator and a quantized network, and further propose an Adaptability-aware Sample Generation (AdaSG) method. Technically, AdaSG reformulates DFQ as a dynamic maximization-vs-minimization game process anchored on the sample adaptability. The maximization process aims to generate the sample with desirable adaptability, such sample adaptability is further reduced by the minimization process after calibrating Q for performance recovery. The Balance Gap is defined to guide the stationarity of the game process to maximally benefit Q. The theoretical analysis and empirical studies verify the superiority of AdaSG over the state-of-the-arts. Our code is available at https://github.com/hfutqian/AdaSG.
Switchable Online Knowledge Distillation
Sep 12, 2022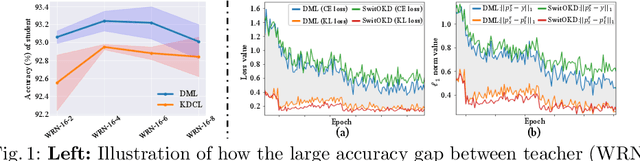

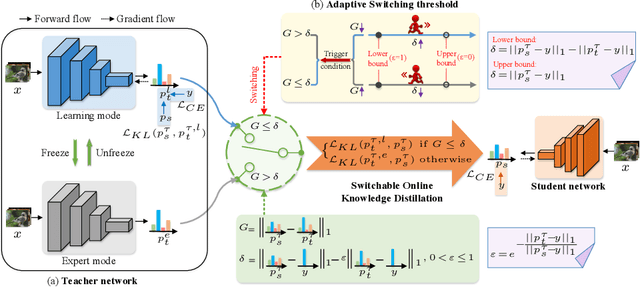
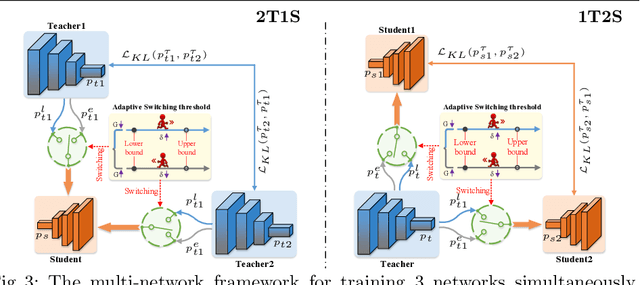
Online Knowledge Distillation (OKD) improves the involved models by reciprocally exploiting the difference between teacher and student. Several crucial bottlenecks over the gap between them -- e.g., Why and when does a large gap harm the performance, especially for student? How to quantify the gap between teacher and student? -- have received limited formal study. In this paper, we propose Switchable Online Knowledge Distillation (SwitOKD), to answer these questions. Instead of focusing on the accuracy gap at test phase by the existing arts, the core idea of SwitOKD is to adaptively calibrate the gap at training phase, namely distillation gap, via a switching strategy between two modes -- expert mode (pause the teacher while keep the student learning) and learning mode (restart the teacher). To possess an appropriate distillation gap, we further devise an adaptive switching threshold, which provides a formal criterion as to when to switch to learning mode or expert mode, and thus improves the student's performance. Meanwhile, the teacher benefits from our adaptive switching threshold and keeps basically on a par with other online arts. We further extend SwitOKD to multiple networks with two basis topologies. Finally, extensive experiments and analysis validate the merits of SwitOKD for classification over the state-of-the-arts. Our code is available at https://github.com/hfutqian/SwitOKD.
Diversifying Inference Path Selection: Moving-Mobile-Network for Landmark Recognition
Dec 01, 2019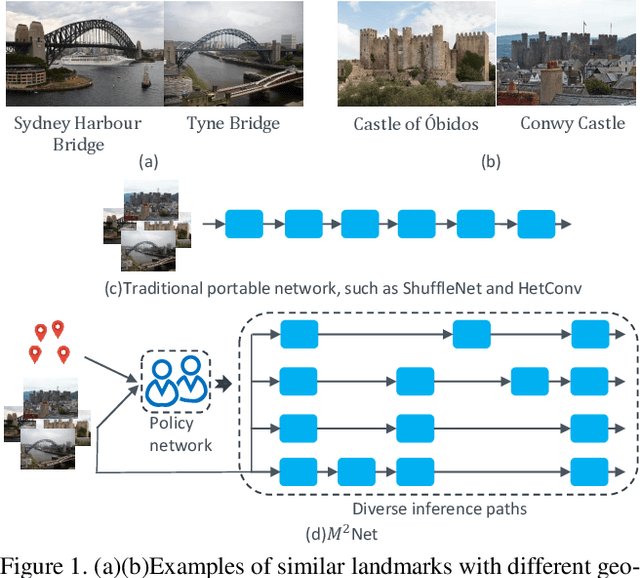
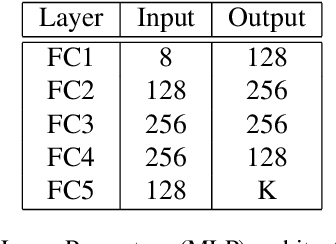
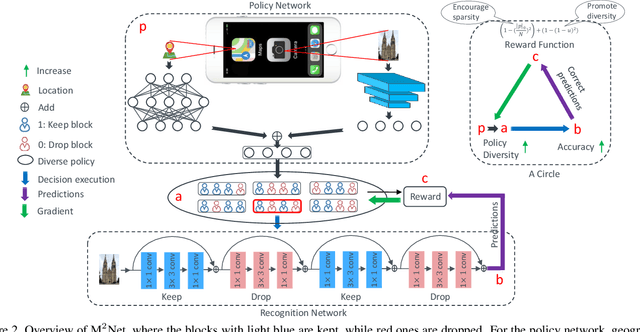
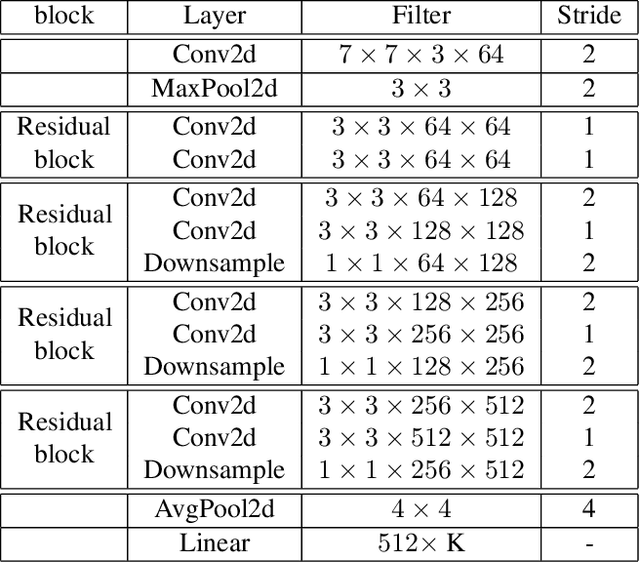
Deep convolutional neural networks have largely benefited computer vision tasks. However, the high computational complexity limits their real-world applications. To this end, many methods have been proposed for efficient network learning, and applications in portable mobile devices. In this paper, we propose a novel \underline{M}oving-\underline{M}obile-\underline{Net}work, named M$^2$Net, for landmark recognition, equipped each landmark image with located geographic information. We intuitively find that M$^2$Net can essentially promote the diversity of the inference path (selected blocks subset) selection, so as to enhance the recognition accuracy. The above intuition is achieved by our proposed reward function with the input of geo-location and landmarks. We also find that the performance of other portable networks can be improved via our architecture. We construct two landmark image datasets, with each landmark associated with geographic information, over which we conduct extensive experiments to demonstrate that M$^2$Net achieves improved recognition accuracy with comparable complexity.
A Targeted Acceleration and Compression Framework for Low bit Neural Networks
Jul 09, 2019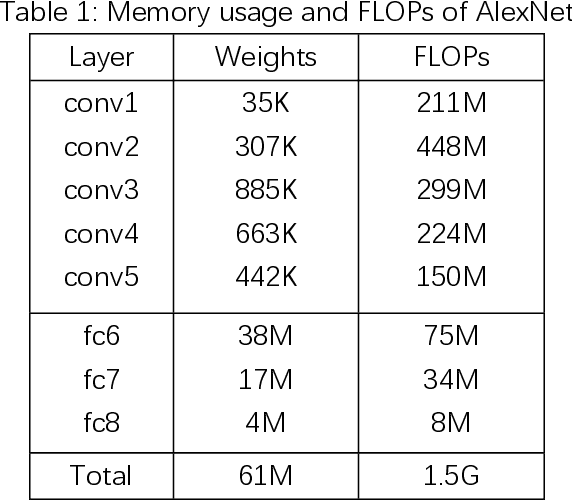
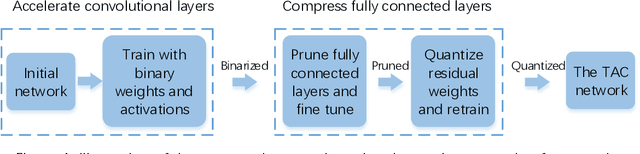
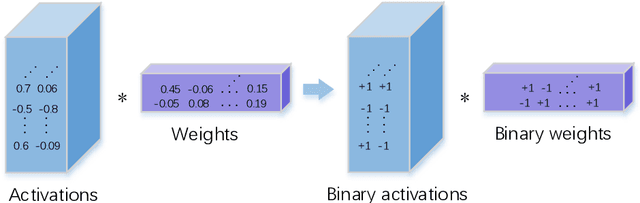
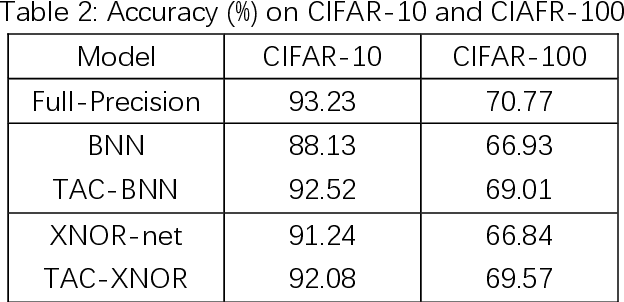
1 bit deep neural networks (DNNs), of which both the activations and weights are binarized , are attracting more and more attention due to their high computational efficiency and low memory requirement . However, the drawback of large accuracy dropping also restrict s its application. In this paper, we propose a novel Targeted Acceleration and Compression (TAC) framework to improve the performance of 1 bit deep neural networks W e consider that the acceleration and compression effects of binarizing fully connected layer s are not sufficient to compensate for the accuracy loss caused by it In the proposed framework, t he convolutional and fully connected layer are separated and optimized i ndividually . F or the convolutional layer s , both the activations and weights are binarized. For the fully connected layer s, the binarization operation is re placed by network pruning and low bit quantization. The proposed framework is implemented on the CIFAR 10, CIFAR 100 and ImageNet ( ILSVRC 12 ) datasets , and experimental results show that the proposed TAC can significantly improve the accuracy of 1 bit deep neural networks and outperforms the state of the art by more than 6 percentage points .