 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaninfradet3D:A Road-side Camera-LiDAR Fusion 3D Perception Model based on Nonlinear Feature Extraction and Intrinsic Correlation
Oct 21, 2024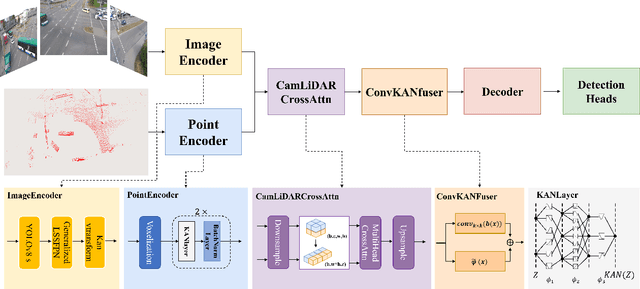


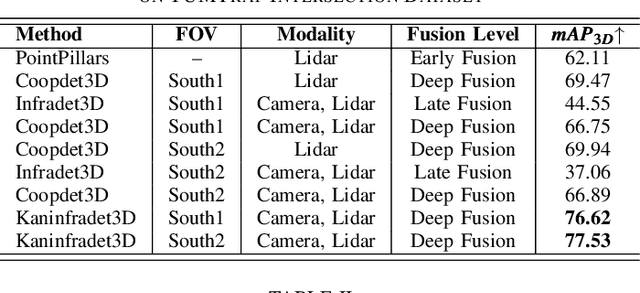
With the development of AI-assisted driving, numerous methods have emerged for ego-vehicle 3D perception tasks, but there has been limited research on roadside perception. With its ability to provide a global view and a broader sensing range, the roadside perspective is worth developing. LiDAR provides precise three-dimensional spatial information, while cameras offer semantic information. These two modalities are complementary in 3D detection. However, adding camera data does not increase accuracy in some studies since the information extraction and fusion procedure is not sufficiently reliable. Recently, Kolmogorov-Arnold Networks (KANs) have been proposed as replacements for MLPs, which are better suited for high-dimensional, complex data. Both the camera and the LiDAR provide high-dimensional information, and employing KANs should enhance the extraction of valuable features to produce better fusion outcomes. This paper proposes Kaninfradet3D, which optimizes the feature extraction and fusion modules. To extract features from complex high-dimensional data, the model's encoder and fuser modules were improved using KAN Layers. Cross-attention was applied to enhance feature fusion, and visual comparisons verified that camera features were more evenly integrated. This addressed the issue of camera features being abnormally concentrated, negatively impacting fusion. Compared to the benchmark, our approach shows improvements of +9.87 mAP and +10.64 mAP in the two viewpoints of the TUMTraf Intersection Dataset and an improvement of +1.40 mAP in the roadside end of the TUMTraf V2X Cooperative Perception Dataset. The results indicate that Kaninfradet3D can effectively fuse features, demonstrating the potential of applying KANs in roadside perception tasks.
HeightFormer: A Semantic Alignment Monocular 3D Object Detection Method from Roadside Perspective
Oct 10, 2024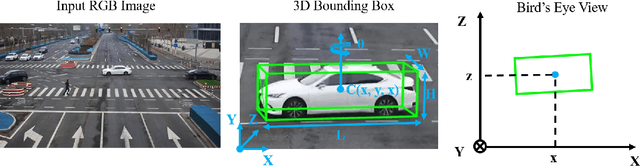
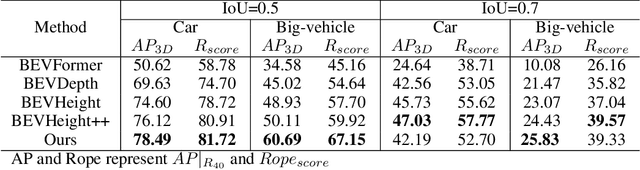
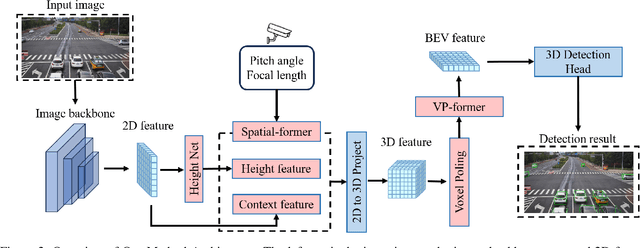
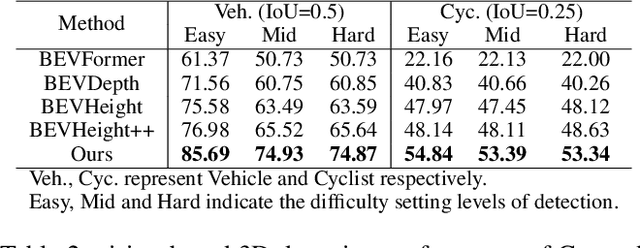
The on-board 3D object detection technology has received extensive attention as a critical technology for autonomous driving, while few studies have focused on applying roadside sensors in 3D traffic object detection. Existing studies achieve the projection of 2D image features to 3D features through height estimation based on the frustum. However, they did not consider the height alignment and the extraction efficiency of bird's-eye-view features. We propose a novel 3D object detection framework integrating Spatial Former and Voxel Pooling Former to enhance 2D-to-3D projection based on height estimation. Extensive experiments were conducted using the Rope3D and DAIR-V2X-I dataset, and the results demonstrated the outperformance of the proposed algorithm in the detection of both vehicles and cyclists. These results indicate that the algorithm is robust and generalized under various detection scenarios. Improving the accuracy of 3D object detection on the roadside is conducive to building a safe and trustworthy intelligent transportation system of vehicle-road coordination and promoting the large-scale application of autonomous driving. The code and pre-trained models will be released on https://anonymous.4open.science/r/HeightFormer.