 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSG-CADVLM: A Context-Aware Decoding Powered Vision Language Model for Safety-Critical Scenario Generation
Jan 26, 2026Autonomous vehicle safety validation requires testing on safety-critical scenarios, but these events are rare in real-world driving and costly to test due to collision risks. Crash reports provide authentic specifications of safety-critical events, offering a vital alternative to scarce real-world collision trajectory data. This makes them valuable sources for generating realistic high-risk scenarios through simulation. Existing approaches face significant limitations because data-driven methods lack diversity due to their reliance on existing latent distributions, whereas adversarial methods often produce unrealistic scenarios lacking physical fidelity. Large Language Model (LLM) and Vision Language Model (VLM)-based methods show significant promise. However, they suffer from context suppression issues where internal parametric knowledge overrides crash specifications, producing scenarios that deviate from actual accident characteristics. This paper presents SG-CADVLM (A Context-Aware Decoding Powered Vision Language Model for Safety-Critical Scenario Generation), a framework that integrates Context-Aware Decoding with multi-modal input processing to generate safety-critical scenarios from crash reports and road network diagrams. The framework mitigates VLM hallucination issues while enabling the simultaneous generation of road geometry and vehicle trajectories. The experimental results demonstrate that SG-CADVLM generates critical risk scenarios at a rate of 84.4% compared to 12.5% for the baseline methods, representing an improvement of 469%, while producing executable simulations for autonomous vehicle testing.
Software-Hardware Co-optimization for Modular E2E AV Paradigm: A Unified Framework of Optimization Approaches, Simulation Environment and Evaluation Metrics
Jan 12, 2026Modular end-to-end (ME2E) autonomous driving paradigms combine modular interpretability with global optimization capability and have demonstrated strong performance. However, existing studies mainly focus on accuracy improvement, while critical system-level factors such as inference latency and energy consumption are often overlooked, resulting in increasingly complex model designs that hinder practical deployment. Prior efforts on model compression and acceleration typically optimize either the software or hardware side in isolation. Software-only optimization cannot fundamentally remove intermediate tensor access and operator scheduling overheads, whereas hardware-only optimization is constrained by model structure and precision. As a result, the real-world benefits of such optimizations are often limited. To address these challenges, this paper proposes a reusable software and hardware co-optimization and closed-loop evaluation framework for ME2E autonomous driving inference. The framework jointly integrates software-level model optimization with hardware-level computation optimization under a unified system-level objective. In addition, a multidimensional evaluation metric is introduced to assess system performance by jointly considering safety, comfort, efficiency, latency, and energy, enabling quantitative comparison of different optimization strategies. Experiments across multiple ME2E autonomous driving stacks show that the proposed framework preserves baseline-level driving performance while significantly reducing inference latency and energy consumption, achieving substantial overall system-level improvements. These results demonstrate that the proposed framework provides practical and actionable guidance for efficient deployment of ME2E autonomous driving systems.
Spatiotemporal Prediction of Secondary Crashes by Rebalancing Dynamic and Static Data with Generative Adversarial Networks
Jan 17, 2025



Data imbalance is a common issue in analyzing and predicting sudden traffic events. Secondary crashes constitute only a small proportion of all crashes. These secondary crashes, triggered by primary crashes, significantly exacerbate traffic congestion and increase the severity of incidents. However, the severe imbalance of secondary crash data poses significant challenges for prediction models, affecting their generalization ability and prediction accuracy. Existing methods fail to fully address the complexity of traffic crash data, particularly the coexistence of dynamic and static features, and often struggle to effectively handle data samples of varying lengths. Furthermore, most current studies predict the occurrence probability and spatiotemporal distribution of secondary crashes separately, lacking an integrated solution. To address these challenges, this study proposes a hybrid model named VarFusiGAN-Transformer, aimed at improving the fidelity of secondary crash data generation and jointly predicting the occurrence and spatiotemporal distribution of secondary crashes. The VarFusiGAN-Transformer model employs Long Short-Term Memory (LSTM) networks to enhance the generation of multivariate long-time series data, incorporating a static data generator and an auxiliary discriminator to model the joint distribution of dynamic and static features. In addition, the model's prediction module achieves simultaneous prediction of both the occurrence and spatiotemporal distribution of secondary crashes. Compared to existing methods, the proposed model demonstrates superior performance in generating high-fidelity data and improving prediction accuracy.
Enhancing Crash Frequency Modeling Based on Augmented Multi-Type Data by Hybrid VAE-Diffusion-Based Generative Neural Networks
Jan 17, 2025Crash frequency modelling analyzes the impact of factors like traffic volume, road geometry, and environmental conditions on crash occurrences. Inaccurate predictions can distort our understanding of these factors, leading to misguided policies and wasted resources, which jeopardize traffic safety. A key challenge in crash frequency modelling is the prevalence of excessive zero observations, caused by underreporting, the low probability of crashes, and high data collection costs. These zero observations often reduce model accuracy and introduce bias, complicating safety decision making. While existing approaches, such as statistical methods, data aggregation, and resampling, attempt to address this issue, they either rely on restrictive assumptions or result in significant information loss, distorting crash data. To overcome these limitations, we propose a hybrid VAE-Diffusion neural network, designed to reduce zero observations and handle the complexities of multi-type tabular crash data (count, ordinal, nominal, and real-valued variables). We assess the synthetic data quality generated by this model through metrics like similarity, accuracy, diversity, and structural consistency, and compare its predictive performance against traditional statistical models. Our findings demonstrate that the hybrid VAE-Diffusion model outperforms baseline models across all metrics, offering a more effective approach to augmenting crash data and improving the accuracy of crash frequency predictions. This study highlights the potential of synthetic data to enhance traffic safety by improving crash frequency modelling and informing better policy decisions.
NEST: A Neuromodulated Small-world Hypergraph Trajectory Prediction Model for Autonomous Driving
Dec 16, 2024Accurate trajectory prediction is essential for the safety and efficiency of autonomous driving. Traditional models often struggle with real-time processing, capturing non-linearity and uncertainty in traffic environments, efficiency in dense traffic, and modeling temporal dynamics of interactions. We introduce NEST (Neuromodulated Small-world Hypergraph Trajectory Prediction), a novel framework that integrates Small-world Networks and hypergraphs for superior interaction modeling and prediction accuracy. This integration enables the capture of both local and extended vehicle interactions, while the Neuromodulator component adapts dynamically to changing traffic conditions. We validate the NEST model on several real-world datasets, including nuScenes, MoCAD, and HighD. The results consistently demonstrate that NEST outperforms existing methods in various traffic scenarios, showcasing its exceptional generalization capability, efficiency, and temporal foresight. Our comprehensive evaluation illustrates that NEST significantly improves the reliability and operational efficiency of autonomous driving systems, making it a robust solution for trajectory prediction in complex traffic environments.
Traj-Explainer: An Explainable and Robust Multi-modal Trajectory Prediction Approach
Oct 22, 2024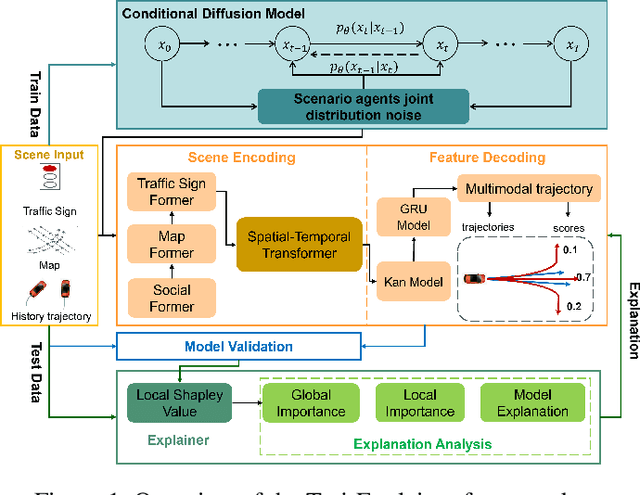
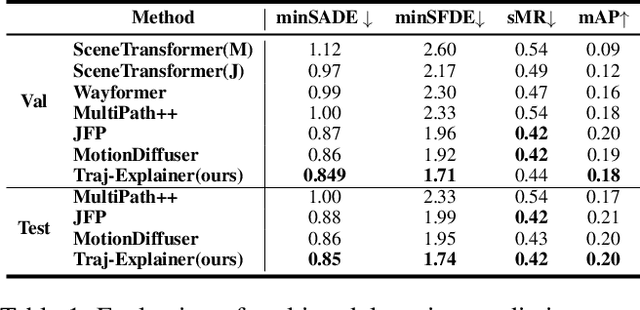

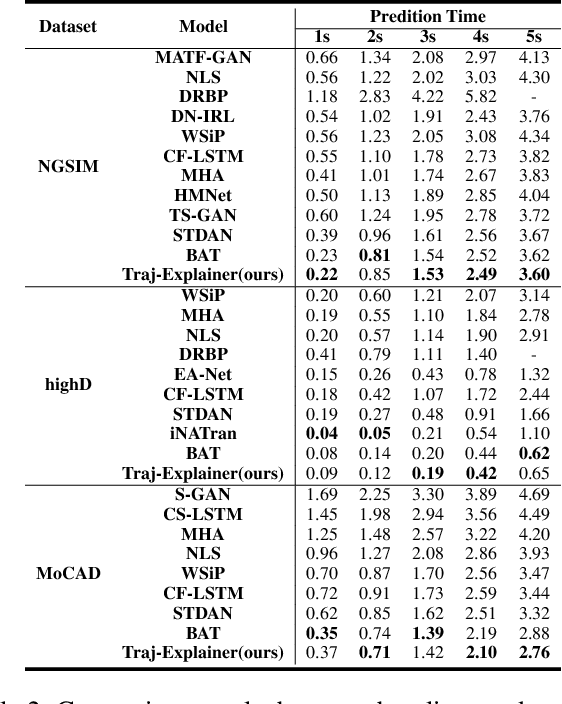
Navigating complex traffic environments has been significantly enhanced by advancements in intelligent technologies, enabling accurate environment perception and trajectory prediction for automated vehicles. However, existing research often neglects the consideration of the joint reasoning of scenario agents and lacks interpretability in trajectory prediction models, thereby limiting their practical application in real-world scenarios. To this purpose, an explainability-oriented trajectory prediction model is designed in this work, named Explainable Conditional Diffusion based Multimodal Trajectory Prediction Traj-Explainer, to retrieve the influencing factors of prediction and help understand the intrinsic mechanism of prediction. In Traj-Explainer, a modified conditional diffusion is well designed to capture the scenario multimodal trajectory pattern, and meanwhile, a modified Shapley Value model is assembled to rationally learn the importance of the global and scenario features. Numerical experiments are carried out by several trajectory prediction datasets, including Waymo, NGSIM, HighD, and MoCAD datasets. Furthermore, we evaluate the identified input factors which indicates that they are in agreement with the human driving experience, indicating the capability of the proposed model in appropriately learning the prediction. Code available in our open-source repository: \url{https://anonymous.4open.science/r/Interpretable-Prediction}.
Kaninfradet3D:A Road-side Camera-LiDAR Fusion 3D Perception Model based on Nonlinear Feature Extraction and Intrinsic Correlation
Oct 21, 2024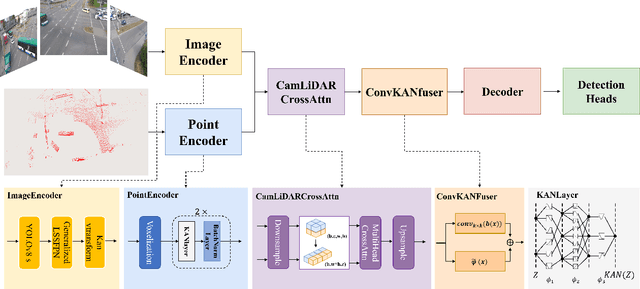


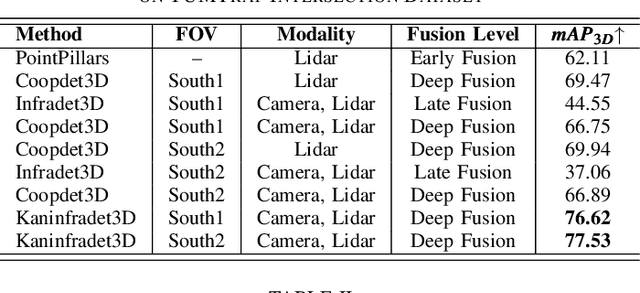
With the development of AI-assisted driving, numerous methods have emerged for ego-vehicle 3D perception tasks, but there has been limited research on roadside perception. With its ability to provide a global view and a broader sensing range, the roadside perspective is worth developing. LiDAR provides precise three-dimensional spatial information, while cameras offer semantic information. These two modalities are complementary in 3D detection. However, adding camera data does not increase accuracy in some studies since the information extraction and fusion procedure is not sufficiently reliable. Recently, Kolmogorov-Arnold Networks (KANs) have been proposed as replacements for MLPs, which are better suited for high-dimensional, complex data. Both the camera and the LiDAR provide high-dimensional information, and employing KANs should enhance the extraction of valuable features to produce better fusion outcomes. This paper proposes Kaninfradet3D, which optimizes the feature extraction and fusion modules. To extract features from complex high-dimensional data, the model's encoder and fuser modules were improved using KAN Layers. Cross-attention was applied to enhance feature fusion, and visual comparisons verified that camera features were more evenly integrated. This addressed the issue of camera features being abnormally concentrated, negatively impacting fusion. Compared to the benchmark, our approach shows improvements of +9.87 mAP and +10.64 mAP in the two viewpoints of the TUMTraf Intersection Dataset and an improvement of +1.40 mAP in the roadside end of the TUMTraf V2X Cooperative Perception Dataset. The results indicate that Kaninfradet3D can effectively fuse features, demonstrating the potential of applying KANs in roadside perception tasks.
HeightFormer: A Semantic Alignment Monocular 3D Object Detection Method from Roadside Perspective
Oct 10, 2024
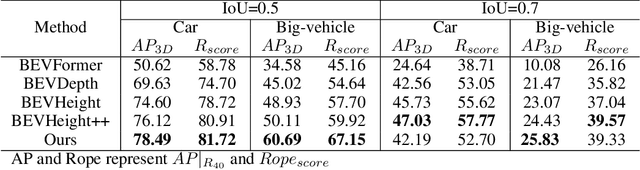
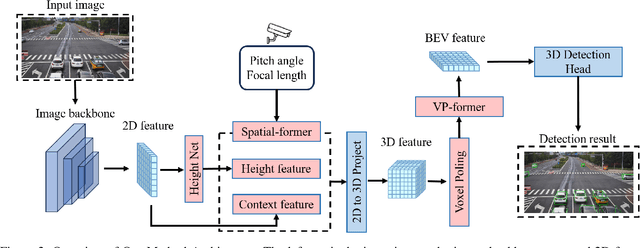
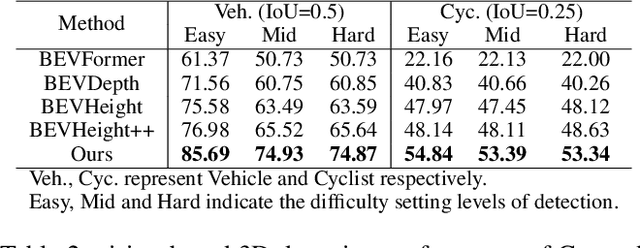
The on-board 3D object detection technology has received extensive attention as a critical technology for autonomous driving, while few studies have focused on applying roadside sensors in 3D traffic object detection. Existing studies achieve the projection of 2D image features to 3D features through height estimation based on the frustum. However, they did not consider the height alignment and the extraction efficiency of bird's-eye-view features. We propose a novel 3D object detection framework integrating Spatial Former and Voxel Pooling Former to enhance 2D-to-3D projection based on height estimation. Extensive experiments were conducted using the Rope3D and DAIR-V2X-I dataset, and the results demonstrated the outperformance of the proposed algorithm in the detection of both vehicles and cyclists. These results indicate that the algorithm is robust and generalized under various detection scenarios. Improving the accuracy of 3D object detection on the roadside is conducive to building a safe and trustworthy intelligent transportation system of vehicle-road coordination and promoting the large-scale application of autonomous driving. The code and pre-trained models will be released on https://anonymous.4open.science/r/HeightFormer.
MSCT: Addressing Time-Varying Confounding with Marginal Structural Causal Transformer for Counterfactual Post-Crash Traffic Prediction
Jul 19, 2024



Traffic crashes profoundly impede traffic efficiency and pose economic challenges. Accurate prediction of post-crash traffic status provides essential information for evaluating traffic perturbations and developing effective solutions. Previous studies have established a series of deep learning models to predict post-crash traffic conditions, however, these correlation-based methods cannot accommodate the biases caused by time-varying confounders and the heterogeneous effects of crashes. The post-crash traffic prediction model needs to estimate the counterfactual traffic speed response to hypothetical crashes under various conditions, which demonstrates the necessity of understanding the causal relationship between traffic factors. Therefore, this paper presents the Marginal Structural Causal Transformer (MSCT), a novel deep learning model designed for counterfactual post-crash traffic prediction. To address the issue of time-varying confounding bias, MSCT incorporates a structure inspired by Marginal Structural Models and introduces a balanced loss function to facilitate learning of invariant causal features. The proposed model is treatment-aware, with a specific focus on comprehending and predicting traffic speed under hypothetical crash intervention strategies. In the absence of ground-truth data, a synthetic data generation procedure is proposed to emulate the causal mechanism between traffic speed, crashes, and covariates. The model is validated using both synthetic and real-world data, demonstrating that MSCT outperforms state-of-the-art models in multi-step-ahead prediction performance. This study also systematically analyzes the impact of time-varying confounding bias and dataset distribution on model performance, contributing valuable insights into counterfactual prediction for intelligent transportation systems.
Less is More: Efficient Brain-Inspired Learning for Autonomous Driving Trajectory Prediction
Jul 09, 2024Accurately and safely predicting the trajectories of surrounding vehicles is essential for fully realizing autonomous driving (AD). This paper presents the Human-Like Trajectory Prediction model (HLTP++), which emulates human cognitive processes to improve trajectory prediction in AD. HLTP++ incorporates a novel teacher-student knowledge distillation framework. The "teacher" model equipped with an adaptive visual sector, mimics the dynamic allocation of attention human drivers exhibit based on factors like spatial orientation, proximity, and driving speed. On the other hand, the "student" model focuses on real-time interaction and human decision-making, drawing parallels to the human memory storage mechanism. Furthermore, we improve the model's efficiency by introducing a new Fourier Adaptive Spike Neural Network (FA-SNN), allowing for faster and more precise predictions with fewer parameters. Evaluated using the NGSIM, HighD, and MoCAD benchmarks, HLTP++ demonstrates superior performance compared to existing models, which reduces the predicted trajectory error with over 11% on the NGSIM dataset and 25% on the HighD datasets. Moreover, HLTP++ demonstrates strong adaptability in challenging environments with incomplete input data. This marks a significant stride in the journey towards fully AD systems.