 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-way Evidence self-Alignment based Dual-Gated Reasoning Enhancement
May 22, 2025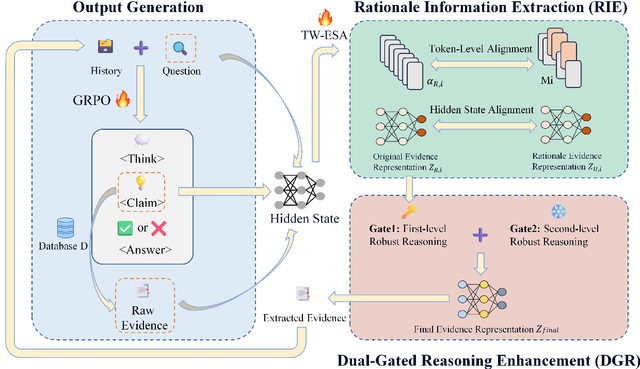
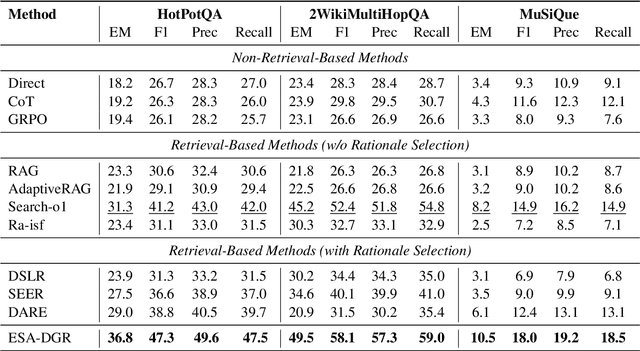
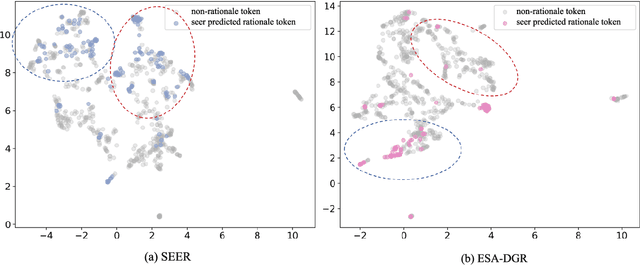
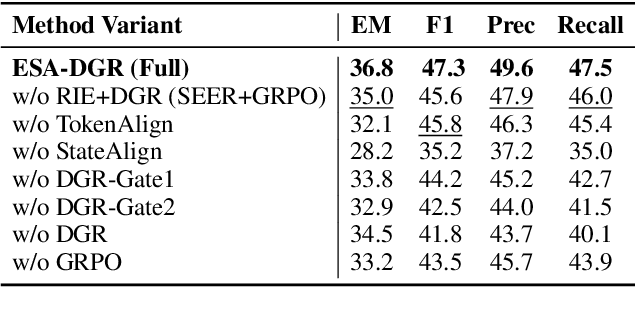
Large language models (LLMs) encounter difficulties in knowledge-intensive multi-step reasoning (KIMSR) tasks. One challenge is how to effectively extract and represent rationale evidence. The current methods often extract semantically relevant but logically irrelevant evidence, resulting in flawed reasoning and inaccurate responses. We propose a two-way evidence self-alignment (TW-ESA) module, which utilizes the mutual alignment between strict reasoning and LLM reasoning to enhance its understanding of the causal logic of evidence, thereby addressing the first challenge. Another challenge is how to utilize the rationale evidence and LLM's intrinsic knowledge for accurate reasoning when the evidence contains uncertainty. We propose a dual-gated reasoning enhancement (DGR) module to gradually fuse useful knowledge of LLM within strict reasoning, which can enable the model to perform accurate reasoning by focusing on causal elements in the evidence and exhibit greater robustness. The two modules are collaboratively trained in a unified framework ESA-DGR. Extensive experiments on three diverse and challenging KIMSR datasets reveal that ESA-DGR significantly surpasses state-of-the-art LLM-based fine-tuning methods, with remarkable average improvements of 4% in exact match (EM) and 5% in F1 score. The implementation code is available at https://anonymous.4open.science/r/ESA-DGR-2BF8.
Can Competition Enhance the Proficiency of Agents Powered by Large Language Models in the Realm of News-driven Time Series Forecasting?
Apr 14, 2025Multi-agents-based news-driven time series forecasting is considered as a potential paradigm shift in the era of large language models (LLMs). The challenge of this task lies in measuring the influences of different news events towards the fluctuations of time series. This requires agents to possess stronger abilities of innovative thinking and the identifying misleading logic. However, the existing multi-agent discussion framework has limited enhancement on time series prediction in terms of optimizing these two capabilities. Inspired by the role of competition in fostering innovation, this study embeds a competition mechanism within the multi-agent discussion to enhance agents' capability of generating innovative thoughts. Furthermore, to bolster the model's proficiency in identifying misleading information, we incorporate a fine-tuned small-scale LLM model within the reflective stage, offering auxiliary decision-making support. Experimental results confirm that the competition can boost agents' capacity for innovative thinking, which can significantly improve the performances of time series prediction. Similar to the findings of social science, the intensity of competition within this framework can influence the performances of agents, providing a new perspective for studying LLMs-based multi-agent systems.
Structuring Scientific Innovation: A Framework for Modeling and Discovering Impactful Knowledge Combinations
Mar 25, 2025The emergence of large language models offers new possibilities for structured exploration of scientific knowledge. Rather than viewing scientific discovery as isolated ideas or content, we propose a structured approach that emphasizes the role of method combinations in shaping disruptive insights. Specifically, we investigate how knowledge unit--especially those tied to methodological design--can be modeled and recombined to yield research breakthroughs. Our proposed framework addresses two key challenges. First, we introduce a contrastive learning-based mechanism to identify distinguishing features of historically disruptive method combinations within problem-driven contexts. Second, we propose a reasoning-guided Monte Carlo search algorithm that leverages the chain-of-thought capability of LLMs to identify promising knowledge recombinations for new problem statements.Empirical studies across multiple domains show that the framework is capable of modeling the structural dynamics of innovation and successfully highlights combinations with high disruptive potential. This research provides a new path for computationally guided scientific ideation grounded in structured reasoning and historical data modeling.
Enhancing Crash Frequency Modeling Based on Augmented Multi-Type Data by Hybrid VAE-Diffusion-Based Generative Neural Networks
Jan 17, 2025Crash frequency modelling analyzes the impact of factors like traffic volume, road geometry, and environmental conditions on crash occurrences. Inaccurate predictions can distort our understanding of these factors, leading to misguided policies and wasted resources, which jeopardize traffic safety. A key challenge in crash frequency modelling is the prevalence of excessive zero observations, caused by underreporting, the low probability of crashes, and high data collection costs. These zero observations often reduce model accuracy and introduce bias, complicating safety decision making. While existing approaches, such as statistical methods, data aggregation, and resampling, attempt to address this issue, they either rely on restrictive assumptions or result in significant information loss, distorting crash data. To overcome these limitations, we propose a hybrid VAE-Diffusion neural network, designed to reduce zero observations and handle the complexities of multi-type tabular crash data (count, ordinal, nominal, and real-valued variables). We assess the synthetic data quality generated by this model through metrics like similarity, accuracy, diversity, and structural consistency, and compare its predictive performance against traditional statistical models. Our findings demonstrate that the hybrid VAE-Diffusion model outperforms baseline models across all metrics, offering a more effective approach to augmenting crash data and improving the accuracy of crash frequency predictions. This study highlights the potential of synthetic data to enhance traffic safety by improving crash frequency modelling and informing better policy decisions.
Spatiotemporal Prediction of Secondary Crashes by Rebalancing Dynamic and Static Data with Generative Adversarial Networks
Jan 17, 2025



Data imbalance is a common issue in analyzing and predicting sudden traffic events. Secondary crashes constitute only a small proportion of all crashes. These secondary crashes, triggered by primary crashes, significantly exacerbate traffic congestion and increase the severity of incidents. However, the severe imbalance of secondary crash data poses significant challenges for prediction models, affecting their generalization ability and prediction accuracy. Existing methods fail to fully address the complexity of traffic crash data, particularly the coexistence of dynamic and static features, and often struggle to effectively handle data samples of varying lengths. Furthermore, most current studies predict the occurrence probability and spatiotemporal distribution of secondary crashes separately, lacking an integrated solution. To address these challenges, this study proposes a hybrid model named VarFusiGAN-Transformer, aimed at improving the fidelity of secondary crash data generation and jointly predicting the occurrence and spatiotemporal distribution of secondary crashes. The VarFusiGAN-Transformer model employs Long Short-Term Memory (LSTM) networks to enhance the generation of multivariate long-time series data, incorporating a static data generator and an auxiliary discriminator to model the joint distribution of dynamic and static features. In addition, the model's prediction module achieves simultaneous prediction of both the occurrence and spatiotemporal distribution of secondary crashes. Compared to existing methods, the proposed model demonstrates superior performance in generating high-fidelity data and improving prediction accuracy.
Kaninfradet3D:A Road-side Camera-LiDAR Fusion 3D Perception Model based on Nonlinear Feature Extraction and Intrinsic Correlation
Oct 21, 2024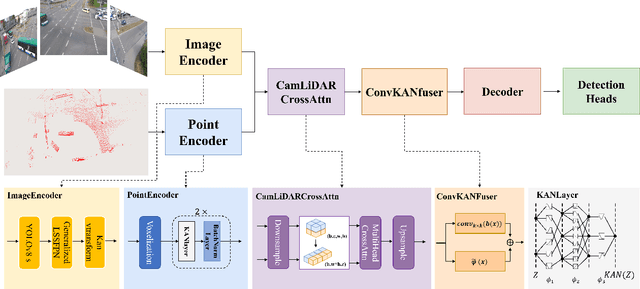


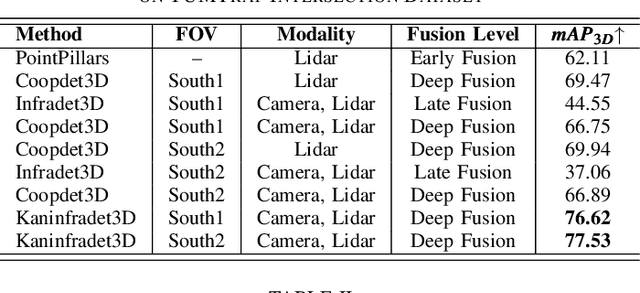
With the development of AI-assisted driving, numerous methods have emerged for ego-vehicle 3D perception tasks, but there has been limited research on roadside perception. With its ability to provide a global view and a broader sensing range, the roadside perspective is worth developing. LiDAR provides precise three-dimensional spatial information, while cameras offer semantic information. These two modalities are complementary in 3D detection. However, adding camera data does not increase accuracy in some studies since the information extraction and fusion procedure is not sufficiently reliable. Recently, Kolmogorov-Arnold Networks (KANs) have been proposed as replacements for MLPs, which are better suited for high-dimensional, complex data. Both the camera and the LiDAR provide high-dimensional information, and employing KANs should enhance the extraction of valuable features to produce better fusion outcomes. This paper proposes Kaninfradet3D, which optimizes the feature extraction and fusion modules. To extract features from complex high-dimensional data, the model's encoder and fuser modules were improved using KAN Layers. Cross-attention was applied to enhance feature fusion, and visual comparisons verified that camera features were more evenly integrated. This addressed the issue of camera features being abnormally concentrated, negatively impacting fusion. Compared to the benchmark, our approach shows improvements of +9.87 mAP and +10.64 mAP in the two viewpoints of the TUMTraf Intersection Dataset and an improvement of +1.40 mAP in the roadside end of the TUMTraf V2X Cooperative Perception Dataset. The results indicate that Kaninfradet3D can effectively fuse features, demonstrating the potential of applying KANs in roadside perception tasks.
A Generative Deep Learning Approach for Crash Severity Modeling with Imbalanced Data
Apr 02, 2024Crash data is often greatly imbalanced, with the majority of crashes being non-fatal crashes, and only a small number being fatal crashes due to their rarity. Such data imbalance issue poses a challenge for crash severity modeling since it struggles to fit and interpret fatal crash outcomes with very limited samples. Usually, such data imbalance issues are addressed by data resampling methods, such as under-sampling and over-sampling techniques. However, most traditional and deep learning-based data resampling methods, such as synthetic minority oversampling technique (SMOTE) and generative Adversarial Networks (GAN) are designed dedicated to processing continuous variables. Though some resampling methods have improved to handle both continuous and discrete variables, they may have difficulties in dealing with the collapse issue associated with sparse discrete risk factors. Moreover, there is a lack of comprehensive studies that compare the performance of various resampling methods in crash severity modeling. To address the aforementioned issues, the current study proposes a crash data generation method based on the Conditional Tabular GAN. After data balancing, a crash severity model is employed to estimate the performance of classification and interpretation. A comparative study is conducted to assess classification accuracy and distribution consistency of the proposed generation method using a 4-year imbalanced crash dataset collected in Washington State, U.S. Additionally, Monte Carlo simulation is employed to estimate the performance of parameter and probability estimation in both two- and three-class imbalance scenarios. The results indicate that using synthetic data generated by CTGAN-RU for crash severity modeling outperforms using original data or synthetic data generated by other resampling methods.
Salient Bundle Adjustment for Visual SLAM
Dec 22, 2020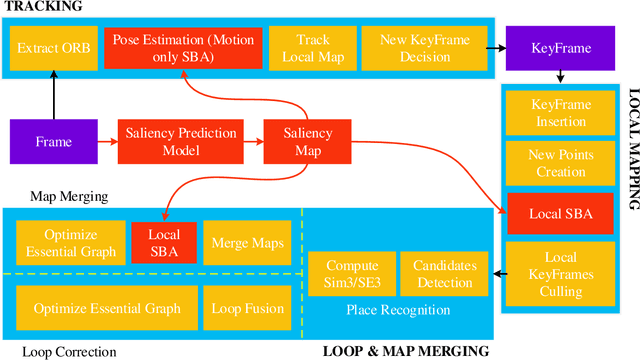

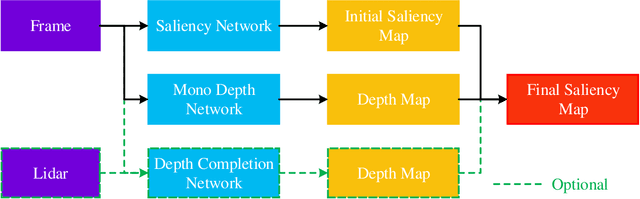

Recently, the philosophy of visual saliency and attention has started to gain popularity in the robotics community. Therefore, this paper aims to mimic this mechanism in SLAM framework by using saliency prediction model. Comparing with traditional SLAM that treated all feature points as equal important in optimization process, we think that the salient feature points should play more important role in optimization process. Therefore, we proposed a saliency model to predict the saliency map, which can capture both scene semantic and geometric information. Then, we proposed Salient Bundle Adjustment by using the value of saliency map as the weight of the feature points in traditional Bundle Adjustment approach. Exhaustive experiments conducted with the state-of-the-art algorithm in KITTI and EuRoc datasets show that our proposed algorithm outperforms existing algorithms in both indoor and outdoor environments. Finally, we will make our saliency dataset and relevant source code open-source for enabling future research.
Approaches, Challenges, and Applications for Deep Visual Odometry: Toward to Complicated and Emerging Areas
Sep 06, 2020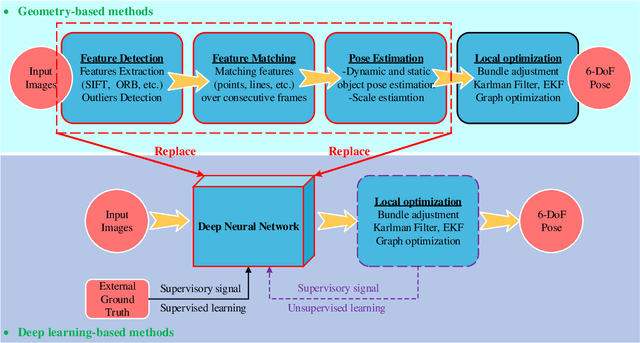

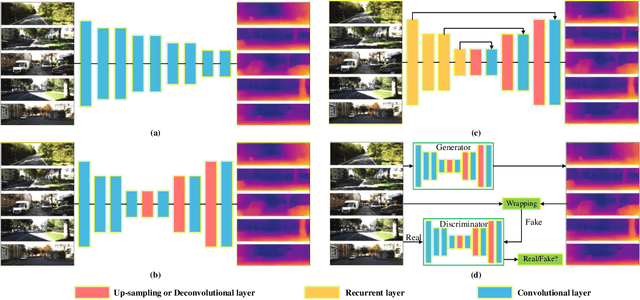
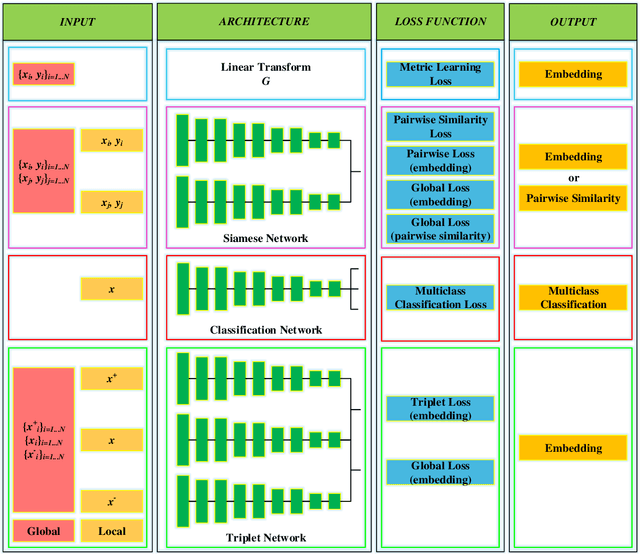
Visual odometry (VO) is a prevalent way to deal with the relative localization problem, which is becoming increasingly mature and accurate, but it tends to be fragile under challenging environments. Comparing with classical geometry-based methods, deep learning-based methods can automatically learn effective and robust representations, such as depth, optical flow, feature, ego-motion, etc., from data without explicit computation. Nevertheless, there still lacks a thorough review of the recent advances of deep learning-based VO (Deep VO). Therefore, this paper aims to gain a deep insight on how deep learning can profit and optimize the VO systems. We first screen out a number of qualifications including accuracy, efficiency, scalability, dynamicity, practicability, and extensibility, and employ them as the criteria. Then, using the offered criteria as the uniform measurements, we detailedly evaluate and discuss how deep learning improves the performance of VO from the aspects of depth estimation, feature extraction and matching, pose estimation. We also summarize the complicated and emerging areas of Deep VO, such as mobile robots, medical robots, augmented reality and virtual reality, etc. Through the literature decomposition, analysis, and comparison, we finally put forward a number of open issues and raise some future research directions in this field.
A feature-supervised generative adversarial network for environmental monitoring during hazy days
Aug 05, 2020
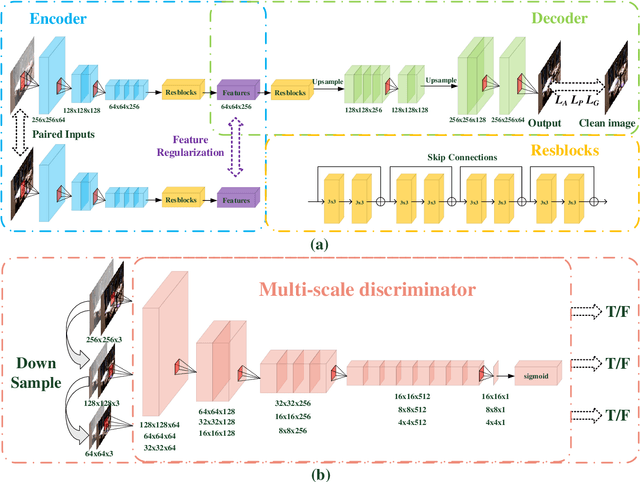


The adverse haze weather condition has brought considerable difficulties in vision-based environmental applications. While, until now, most of the existing environmental monitoring studies are under ordinary conditions, and the studies of complex haze weather conditions have been ignored. Thence, this paper proposes a feature-supervised learning network based on generative adversarial networks (GAN) for environmental monitoring during hazy days. Its main idea is to train the model under the supervision of feature maps from the ground truth. Four key technical contributions are made in the paper. First, pairs of hazy and clean images are used as inputs to supervise the encoding process and obtain high-quality feature maps. Second, the basic GAN formulation is modified by introducing perception loss, style loss, and feature regularization loss to generate better results. Third, multi-scale images are applied as the input to enhance the performance of discriminator. Finally, a hazy remote sensing dataset is created for testing our dehazing method and environmental detection. Extensive experimental results show that the proposed method has achieved better performance than current state-of-the-art methods on both synthetic datasets and real-world remote sensing images.