 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial Catalysts, Not Moral Agents: The Illusion of Alignment in LLM Societies
Feb 01, 2026The rapid evolution of Large Language Models (LLMs) has led to the emergence of Multi-Agent Systems where collective cooperation is often threatened by the "Tragedy of the Commons." This study investigates the effectiveness of Anchoring Agents--pre-programmed altruistic entities--in fostering cooperation within a Public Goods Game (PGG). Using a full factorial design across three state-of-the-art LLMs, we analyzed both behavioral outcomes and internal reasoning chains. While Anchoring Agents successfully boosted local cooperation rates, cognitive decomposition and transfer tests revealed that this effect was driven by strategic compliance and cognitive offloading rather than genuine norm internalization. Notably, most agents reverted to self-interest in new environments, and advanced models like GPT-4.1 exhibited a "Chameleon Effect," masking strategic defection under public scrutiny. These findings highlight a critical gap between behavioral modification and authentic value alignment in artificial societies.
Low-Resource Crop Classification from Multi-Spectral Time Series Using Lossless Compressors
May 28, 2024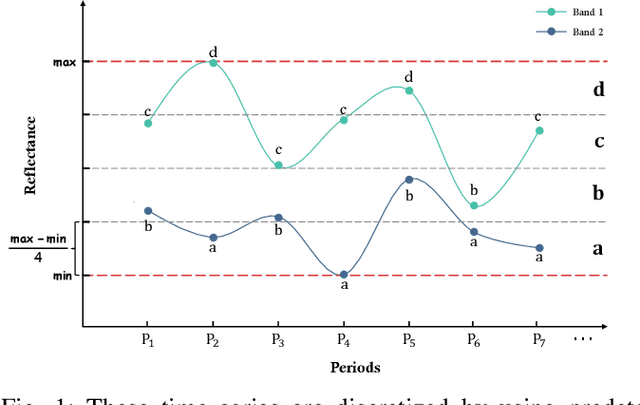
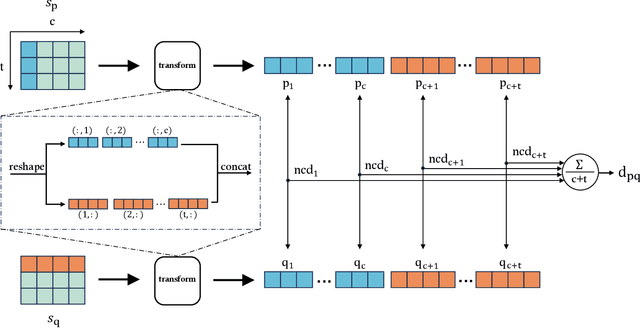
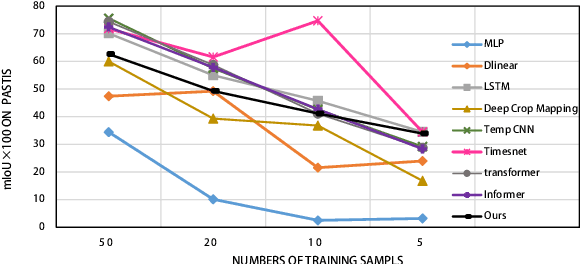
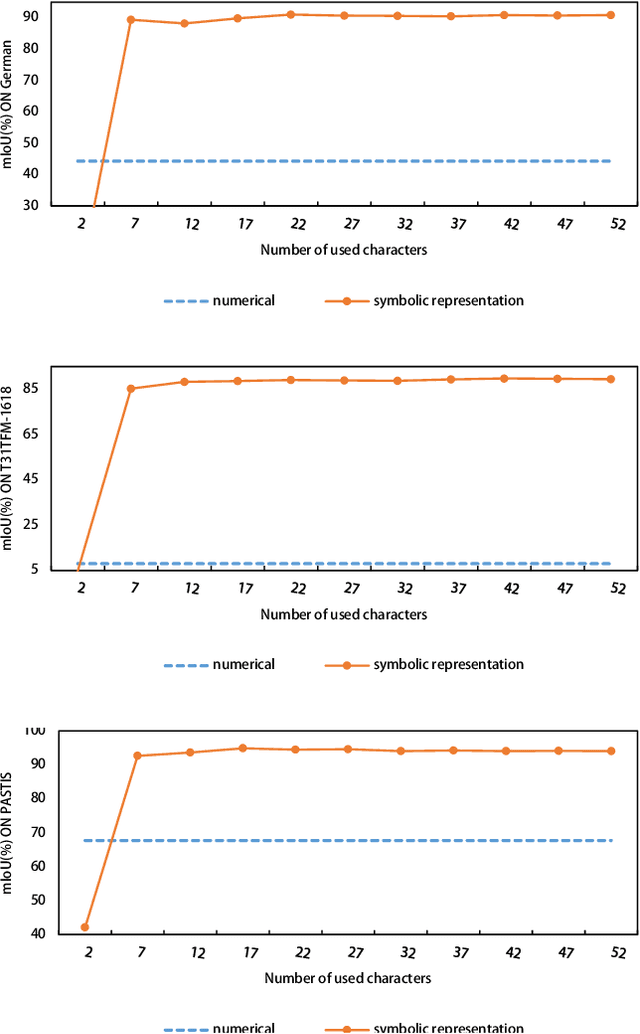
Deep learning has significantly improved the accuracy of crop classification using multispectral temporal data. However, these models have complex structures with numerous parameters, requiring large amounts of data and costly training. In low-resource situations with fewer labeled samples, deep learning models perform poorly due to insufficient data. Conversely, compressors are data-type agnostic, and non-parametric methods do not bring underlying assumptions. Inspired by this insight, we propose a non-training alternative to deep learning models, aiming to address these situations. Specifically, the Symbolic Representation Module is proposed to convert the reflectivity into symbolic representations. The symbolic representations are then cross-transformed in both the channel and time dimensions to generate symbolic embeddings. Next, the Multi-scale Normalised Compression Distance (MNCD) is designed to measure the correlation between any two symbolic embeddings. Finally, based on the MNCDs, high quality crop classification can be achieved using only a k-nearest-neighbor classifier kNN. The entire framework is ready-to-use and lightweight. Without any training, it outperformed, on average, 7 advanced deep learning models trained at scale on three benchmark datasets. It also outperforms more than half of these models in the few-shot setting with sparse crop labels. Therefore, the high performance and robustness of our non-training framework makes it truly applicable to real-world crop mapping. Codes are available at: https://github.com/qinfengsama/Compressor-Based-Crop-Mapping.
A Generative Deep Learning Approach for Crash Severity Modeling with Imbalanced Data
Apr 02, 2024Crash data is often greatly imbalanced, with the majority of crashes being non-fatal crashes, and only a small number being fatal crashes due to their rarity. Such data imbalance issue poses a challenge for crash severity modeling since it struggles to fit and interpret fatal crash outcomes with very limited samples. Usually, such data imbalance issues are addressed by data resampling methods, such as under-sampling and over-sampling techniques. However, most traditional and deep learning-based data resampling methods, such as synthetic minority oversampling technique (SMOTE) and generative Adversarial Networks (GAN) are designed dedicated to processing continuous variables. Though some resampling methods have improved to handle both continuous and discrete variables, they may have difficulties in dealing with the collapse issue associated with sparse discrete risk factors. Moreover, there is a lack of comprehensive studies that compare the performance of various resampling methods in crash severity modeling. To address the aforementioned issues, the current study proposes a crash data generation method based on the Conditional Tabular GAN. After data balancing, a crash severity model is employed to estimate the performance of classification and interpretation. A comparative study is conducted to assess classification accuracy and distribution consistency of the proposed generation method using a 4-year imbalanced crash dataset collected in Washington State, U.S. Additionally, Monte Carlo simulation is employed to estimate the performance of parameter and probability estimation in both two- and three-class imbalance scenarios. The results indicate that using synthetic data generated by CTGAN-RU for crash severity modeling outperforms using original data or synthetic data generated by other resampling methods.