 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoRA: Evaluating Grounded Reasonableness in Visual First-person Normative Action Reasoning
Jun 03, 2026LLMs and agentic systems are increasingly deployed in social environments, making normative competence critical for safe and appropriate behavior. However, existing approaches either assess normative judgment in text alone or reduce it to choosing among a fixed set of candidate actions. We argue both are insufficient. In practice, agents are never handed a menu of options; they must identify a reasonable action from scratch, grounded in visible facts and supported by inspectable reasons. We introduce NoRA, a visual first-person video benchmark that requires models to generate candidate next actions and justify each through an explicit fact-reason-action support graph. The benchmark comprises 1,420 annotated video clips, including HumanGold-190 and LLMSilver-1230 splits. Each instance is evaluated through action alignment, factual grounding, and support binding, aggregated into a single grounded reasonableness score. We benchmark 12 multimodal systems under direct, deliberate, and structured prompting regimes, finding that current VLMs frequently recover plausible actions and relevant scene facts, but consistently struggle to construct the full reasonable action space and bind selected actions to the correct local support. NoRA makes this gap measurable, shifting the evaluation question from whether a model can pick an action to whether it can justify an appropriate action for the right visible reasons.
FaithAct: Faithfulness Planning and Acting in MLLMs
Nov 11, 2025Unfaithfulness remains a persistent challenge for large language models (LLMs), which often produce plausible yet ungrounded reasoning chains that diverge from perceptual evidence or final conclusions. We distinguish between behavioral faithfulness (alignment between reasoning and output) and perceptual faithfulness (alignment between reasoning and input), and introduce FaithEval for quantifying step-level and chain-level faithfulness by evaluating whether each claimed object is visually supported by the image. Building on these insights, we propose FaithAct, a faithfulness-first planning and acting framework that enforces evidential grounding at every reasoning step. Experiments across multiple reasoning benchmarks demonstrate that FaithAct improves perceptual faithfulness by up to 26% without degrading task accuracy compared to prompt-based and tool-augmented baselines. Our analysis shows that treating faithfulness as a guiding principle not only mitigates hallucination but also leads to more stable reasoning trajectories. This work thereby establishes a unified framework for both evaluating and enforcing faithfulness in multimodal reasoning.
Astra: Toward General-Purpose Mobile Robots via Hierarchical Multimodal Learning
Jun 06, 2025Modern robot navigation systems encounter difficulties in diverse and complex indoor environments. Traditional approaches rely on multiple modules with small models or rule-based systems and thus lack adaptability to new environments. To address this, we developed Astra, a comprehensive dual-model architecture, Astra-Global and Astra-Local, for mobile robot navigation. Astra-Global, a multimodal LLM, processes vision and language inputs to perform self and goal localization using a hybrid topological-semantic graph as the global map, and outperforms traditional visual place recognition methods. Astra-Local, a multitask network, handles local path planning and odometry estimation. Its 4D spatial-temporal encoder, trained through self-supervised learning, generates robust 4D features for downstream tasks. The planning head utilizes flow matching and a novel masked ESDF loss to minimize collision risks for generating local trajectories, and the odometry head integrates multi-sensor inputs via a transformer encoder to predict the relative pose of the robot. Deployed on real in-house mobile robots, Astra achieves high end-to-end mission success rate across diverse indoor environments.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022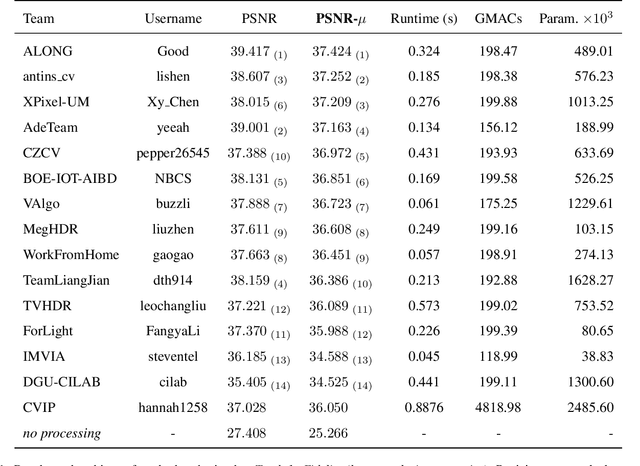
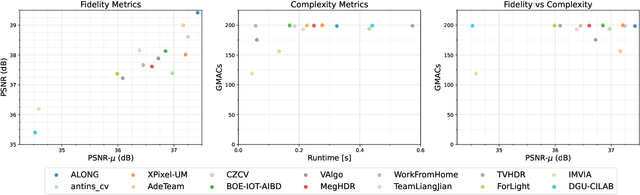
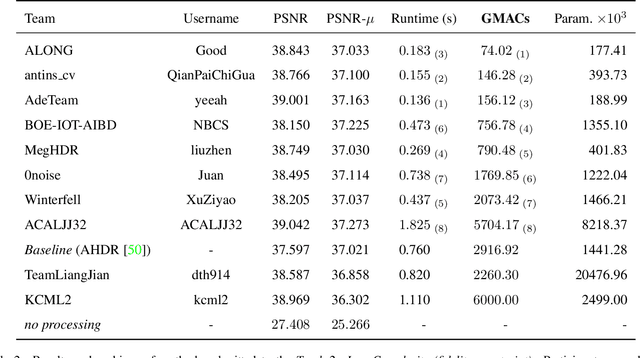
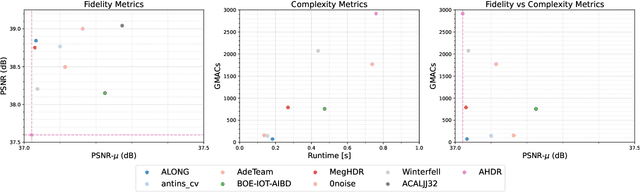
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables
Salient Bundle Adjustment for Visual SLAM
Dec 22, 2020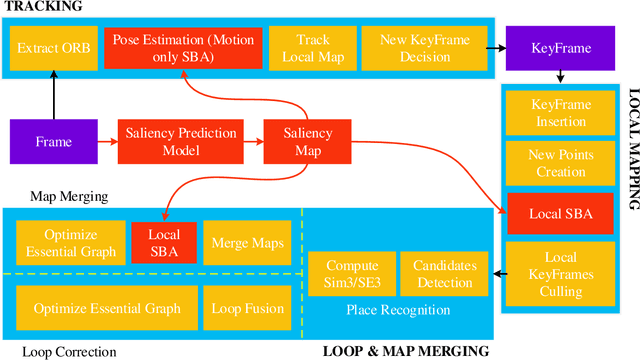

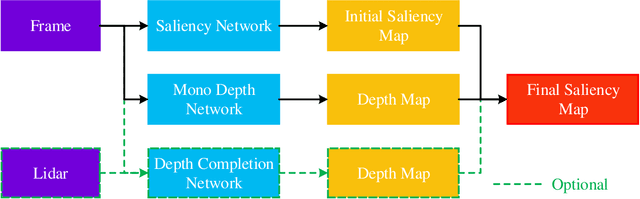

Recently, the philosophy of visual saliency and attention has started to gain popularity in the robotics community. Therefore, this paper aims to mimic this mechanism in SLAM framework by using saliency prediction model. Comparing with traditional SLAM that treated all feature points as equal important in optimization process, we think that the salient feature points should play more important role in optimization process. Therefore, we proposed a saliency model to predict the saliency map, which can capture both scene semantic and geometric information. Then, we proposed Salient Bundle Adjustment by using the value of saliency map as the weight of the feature points in traditional Bundle Adjustment approach. Exhaustive experiments conducted with the state-of-the-art algorithm in KITTI and EuRoc datasets show that our proposed algorithm outperforms existing algorithms in both indoor and outdoor environments. Finally, we will make our saliency dataset and relevant source code open-source for enabling future research.
Approaches, Challenges, and Applications for Deep Visual Odometry: Toward to Complicated and Emerging Areas
Sep 06, 2020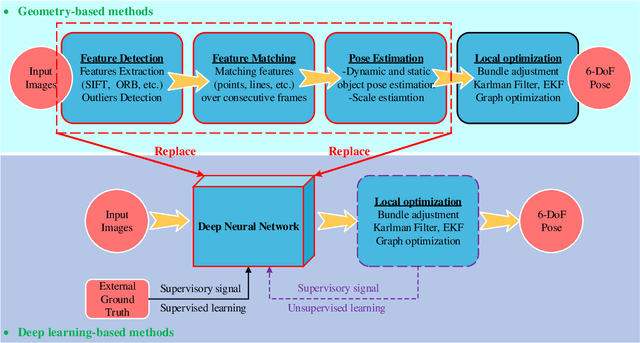

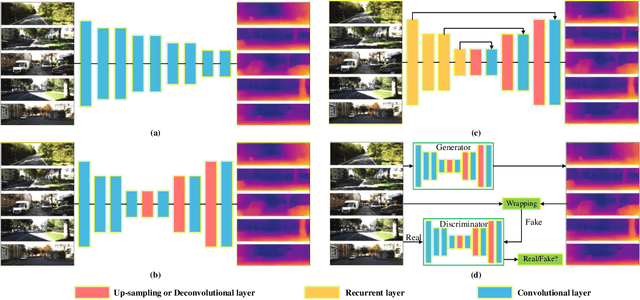
Visual odometry (VO) is a prevalent way to deal with the relative localization problem, which is becoming increasingly mature and accurate, but it tends to be fragile under challenging environments. Comparing with classical geometry-based methods, deep learning-based methods can automatically learn effective and robust representations, such as depth, optical flow, feature, ego-motion, etc., from data without explicit computation. Nevertheless, there still lacks a thorough review of the recent advances of deep learning-based VO (Deep VO). Therefore, this paper aims to gain a deep insight on how deep learning can profit and optimize the VO systems. We first screen out a number of qualifications including accuracy, efficiency, scalability, dynamicity, practicability, and extensibility, and employ them as the criteria. Then, using the offered criteria as the uniform measurements, we detailedly evaluate and discuss how deep learning improves the performance of VO from the aspects of depth estimation, feature extraction and matching, pose estimation. We also summarize the complicated and emerging areas of Deep VO, such as mobile robots, medical robots, augmented reality and virtual reality, etc. Through the literature decomposition, analysis, and comparison, we finally put forward a number of open issues and raise some future research directions in this field.
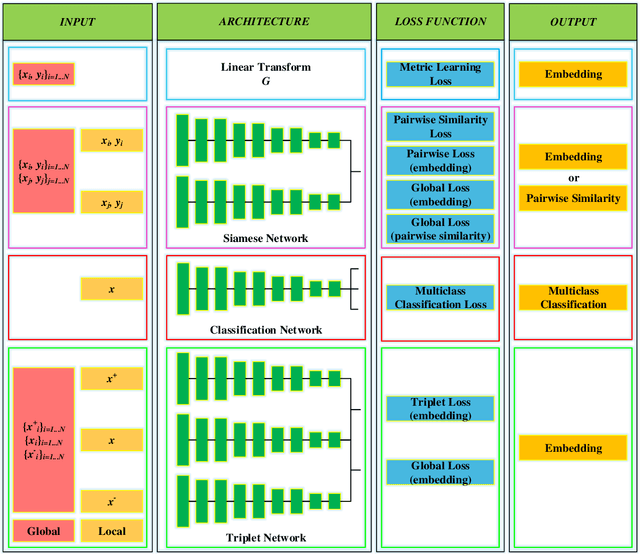
IStego100K: Large-scale Image Steganalysis Dataset
Nov 13, 2019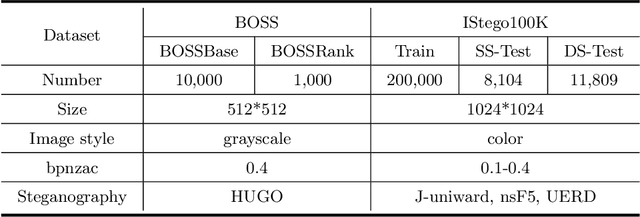

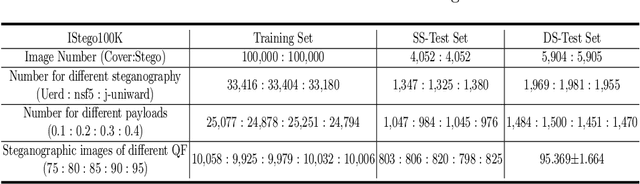
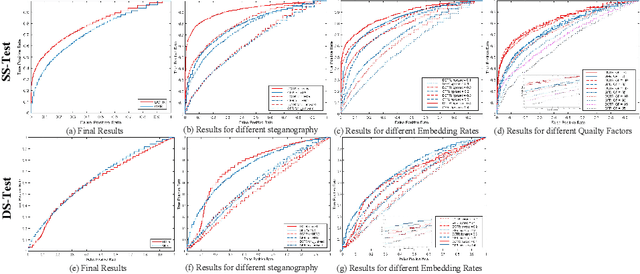
In order to promote the rapid development of image steganalysis technology, in this paper, we construct and release a multivariable large-scale image steganalysis dataset called IStego100K. It contains 208,104 images with the same size of 1024*1024. Among them, 200,000 images (100,000 cover-stego image pairs) are divided as the training set and the remaining 8,104 as testing set. In addition, we hope that IStego100K can help researchers further explore the development of universal image steganalysis algorithms, so we try to reduce limits on the images in IStego100K. For each image in IStego100K, the quality factors is randomly set in the range of 75-95, the steganographic algorithm is randomly selected from three well-known steganographic algorithms, which are J-uniward, nsF5 and UERD, and the embedding rate is also randomly set to be a value of 0.1-0.4. In addition, considering the possible mismatch between training samples and test samples in real environment, we add a test set (DS-Test) whose source of samples are different from the training set. We hope that this test set can help to evaluate the robustness of steganalysis algorithms. We tested the performance of some latest steganalysis algorithms on IStego100K, with specific results and analysis details in the experimental part. We hope that the IStego100K dataset will further promote the development of universal image steganalysis technology. The description of IStego100K and instructions for use can be found at https://github.com/YangzlTHU/IStego100K