 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUVL: A Unified Framework for Video Tampering Localization
Sep 28, 2023

With the development of deep learning technology, various forgery methods emerge endlessly. Meanwhile, methods to detect these fake videos have also achieved excellent performance on some datasets. However, these methods suffer from poor generalization to unknown videos and are inefficient for new forgery methods. To address this challenging problem, we propose UVL, a novel unified video tampering localization framework for synthesizing forgeries. Specifically, UVL extracts common features of synthetic forgeries: boundary artifacts of synthetic edges, unnatural distribution of generated pixels, and noncorrelation between the forgery region and the original. These features are widely present in different types of synthetic forgeries and help improve generalization for detecting unknown videos. Extensive experiments on three types of synthetic forgery: video inpainting, video splicing and DeepFake show that the proposed UVL achieves state-of-the-art performance on various benchmarks and outperforms existing methods by a large margin on cross-dataset.
ZeroGen: Zero-shot Multimodal Controllable Text Generation with Multiple Oracles
Jun 29, 2023



Automatically generating textual content with desired attributes is an ambitious task that people have pursued long. Existing works have made a series of progress in incorporating unimodal controls into language models (LMs), whereas how to generate controllable sentences with multimodal signals and high efficiency remains an open question. To tackle the puzzle, we propose a new paradigm of zero-shot controllable text generation with multimodal signals (\textsc{ZeroGen}). Specifically, \textsc{ZeroGen} leverages controls of text and image successively from token-level to sentence-level and maps them into a unified probability space at decoding, which customizes the LM outputs by weighted addition without extra training. To achieve better inter-modal trade-offs, we further introduce an effective dynamic weighting mechanism to regulate all control weights. Moreover, we conduct substantial experiments to probe the relationship of being in-depth or in-width between signals from distinct modalities. Encouraging empirical results on three downstream tasks show that \textsc{ZeroGen} not only outperforms its counterparts on captioning tasks by a large margin but also shows great potential in multimodal news generation with a higher degree of control. Our code will be released at https://github.com/ImKeTT/ZeroGen.
Vision Transformer Based Video Hashing Retrieval for Tracing the Source of Fake Videos
Dec 15, 2021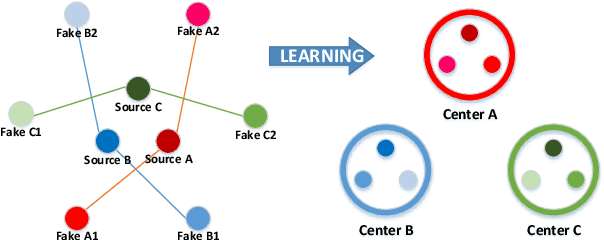
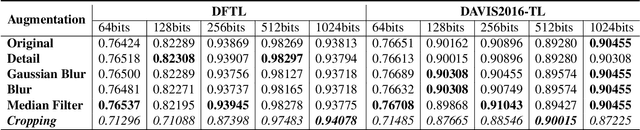
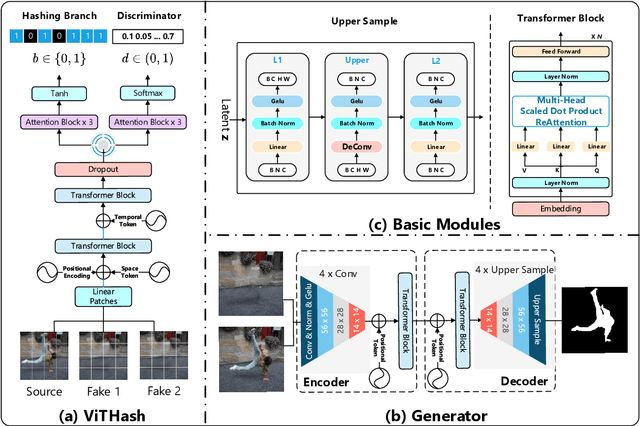

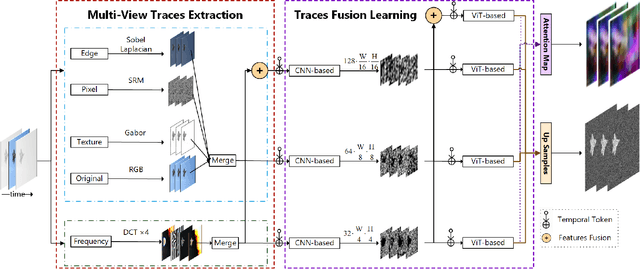
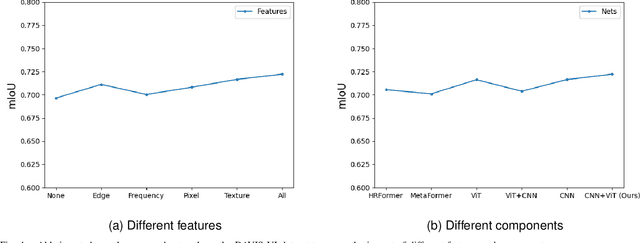
Conventional fake video detection methods outputs a possibility value or a suspected mask of tampering images. However, such unexplainable results cannot be used as convincing evidence. So it is better to trace the sources of fake videos. The traditional hashing methods are used to retrieve semantic-similar images, which can't discriminate the nuances of the image. Specifically, the sources tracing compared with traditional video retrieval. It is a challenge to find the real one from similar source videos. We designed a novel loss Hash Triplet Loss to solve the problem that the videos of people are very similar: the same scene with different angles, similar scenes with the same person. We propose Vision Transformer based models named Video Tracing and Tampering Localization (VTL). In the first stage, we train the hash centers by ViTHash (VTL-T). Then, a fake video is inputted to ViTHash, which outputs a hash code. The hash code is used to retrieve the source video from hash centers. In the second stage, the source video and fake video are inputted to generator (VTL-L). Then, the suspect regions are masked to provide auxiliary information. Moreover, we constructed two datasets: DFTL and DAVIS2016-TL. Experiments on DFTL clearly show the superiority of our framework in sources tracing of similar videos. In particular, the VTL also achieved comparable performance with state-of-the-art methods on DAVIS2016-TL. Our source code and datasets have been released on GitHub: \url{https://github.com/lajlksdf/vtl}.
FMFCC-A: A Challenging Mandarin Dataset for Synthetic Speech Detection
Oct 18, 2021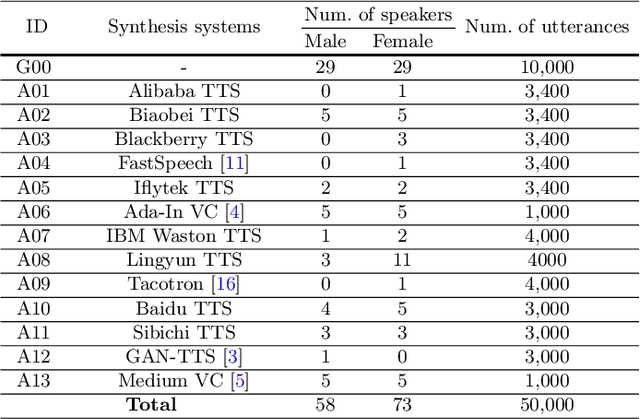
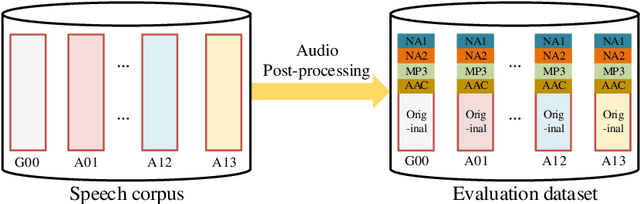

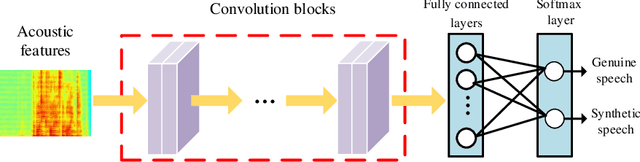
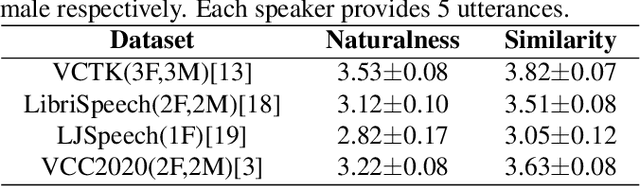
As increasing development of text-to-speech (TTS) and voice conversion (VC) technologies, the detection of synthetic speech has been suffered dramatically. In order to promote the development of synthetic speech detection model against Mandarin TTS and VC technologies, we have constructed a challenging Mandarin dataset and organized the accompanying audio track of the first fake media forensic challenge of China Society of Image and Graphics (FMFCC-A). The FMFCC-A dataset is by far the largest publicly-available Mandarin dataset for synthetic speech detection, which contains 40,000 synthesized Mandarin utterances that generated by 11 Mandarin TTS systems and two Mandarin VC systems, and 10,000 genuine Mandarin utterances collected from 58 speakers. The FMFCC-A dataset is divided into the training, development and evaluation sets, which are used for the research of detection of synthesized Mandarin speech under various previously unknown speech synthesis systems or audio post-processing operations. In addition to describing the construction of the FMFCC-A dataset, we provide a detailed analysis of two baseline methods and the top-performing submissions from the FMFCC-A, which illustrates the usefulness and challenge of FMFCC-A dataset. We hope that the FMFCC-A dataset can fill the gap of lack of Mandarin datasets for synthetic speech detection.
MediumVC: Any-to-any voice conversion using synthetic specific-speaker speeches as intermedium features
Oct 06, 2021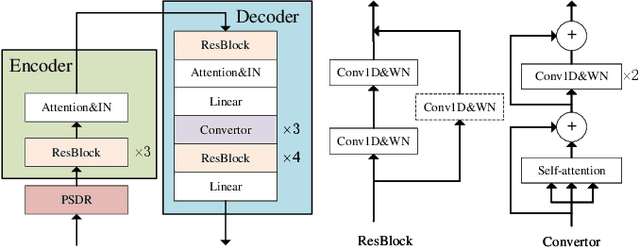
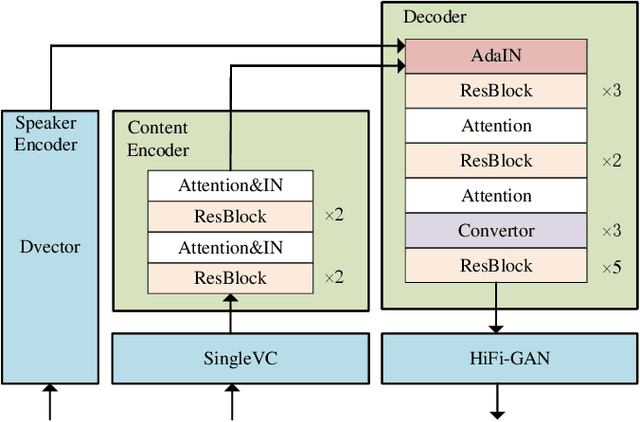

To realize any-to-any (A2A) voice conversion (VC), most methods are to perform symmetric self-supervised reconstruction tasks (Xi to Xi), which usually results in inefficient performances due to inadequate feature decoupling, especially for unseen speakers. We propose a two-stage reconstruction task (Xi to Yi to Xi) using synthetic specific-speaker speeches as intermedium features, where A2A VC is divided into two stages: any-to-one (A2O) and one-to-Any (O2A). In the A2O stage, we propose a new A2O method: SingleVC, by employing a noval data augment strategy(pitch-shifted and duration-remained, PSDR) to accomplish Xi to Yi. In the O2A stage, MediumVC is proposed based on pre-trained SingleVC to conduct Yi to Xi. Through such asymmetrical reconstruction tasks (Xi to Yi in SingleVC and Yi to Xi in MediumVC), the models are to capture robust disentangled features purposefully. Experiments indicate MediumVC can enhance the similarity of converted speeches while maintaining a high degree of naturalness.
Detection of Deepfake Videos Using Long Distance Attention
Jun 24, 2021
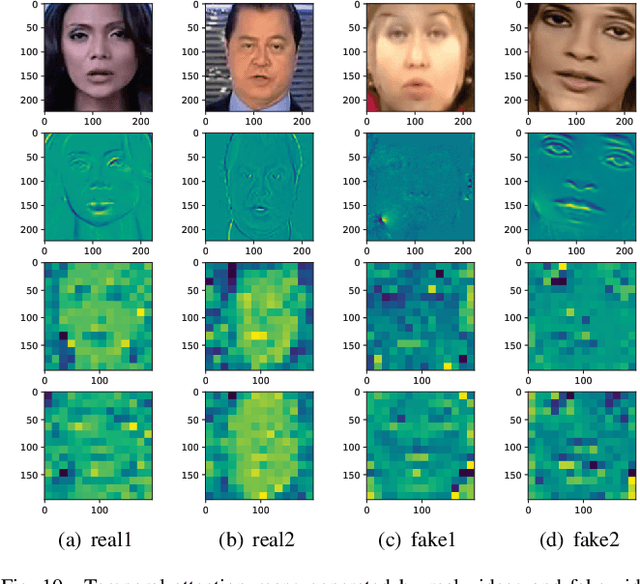
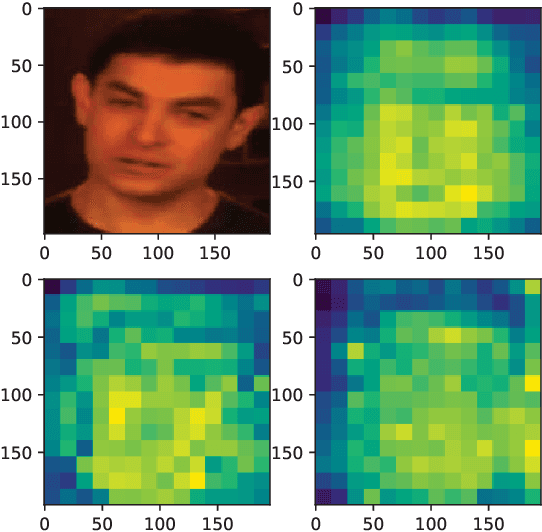

With the rapid progress of deepfake techniques in recent years, facial video forgery can generate highly deceptive video contents and bring severe security threats. And detection of such forgery videos is much more urgent and challenging. Most existing detection methods treat the problem as a vanilla binary classification problem. In this paper, the problem is treated as a special fine-grained classification problem since the differences between fake and real faces are very subtle. It is observed that most existing face forgery methods left some common artifacts in the spatial domain and time domain, including generative defects in the spatial domain and inter-frame inconsistencies in the time domain. And a spatial-temporal model is proposed which has two components for capturing spatial and temporal forgery traces in global perspective respectively. The two components are designed using a novel long distance attention mechanism. The one component of the spatial domain is used to capture artifacts in a single frame, and the other component of the time domain is used to capture artifacts in consecutive frames. They generate attention maps in the form of patches. The attention method has a broader vision which contributes to better assembling global information and extracting local statistic information. Finally, the attention maps are used to guide the network to focus on pivotal parts of the face, just like other fine-grained classification methods. The experimental results on different public datasets demonstrate that the proposed method achieves the state-of-the-art performance, and the proposed long distance attention method can effectively capture pivotal parts for face forgery.
IStego100K: Large-scale Image Steganalysis Dataset
Nov 13, 2019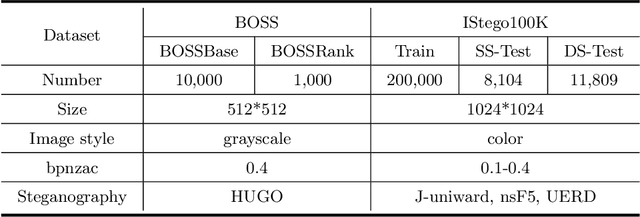

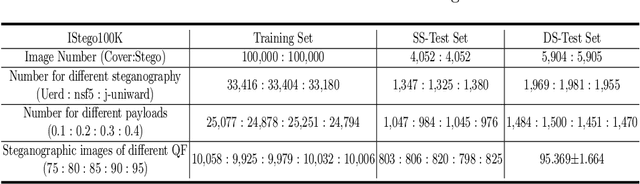
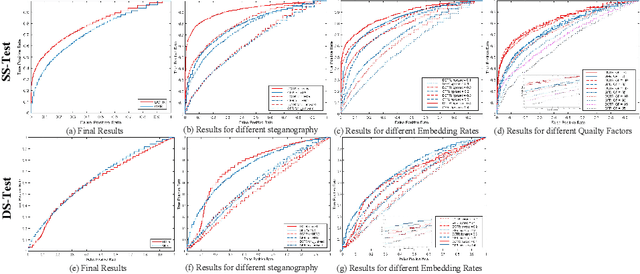
In order to promote the rapid development of image steganalysis technology, in this paper, we construct and release a multivariable large-scale image steganalysis dataset called IStego100K. It contains 208,104 images with the same size of 1024*1024. Among them, 200,000 images (100,000 cover-stego image pairs) are divided as the training set and the remaining 8,104 as testing set. In addition, we hope that IStego100K can help researchers further explore the development of universal image steganalysis algorithms, so we try to reduce limits on the images in IStego100K. For each image in IStego100K, the quality factors is randomly set in the range of 75-95, the steganographic algorithm is randomly selected from three well-known steganographic algorithms, which are J-uniward, nsF5 and UERD, and the embedding rate is also randomly set to be a value of 0.1-0.4. In addition, considering the possible mismatch between training samples and test samples in real environment, we add a test set (DS-Test) whose source of samples are different from the training set. We hope that this test set can help to evaluate the robustness of steganalysis algorithms. We tested the performance of some latest steganalysis algorithms on IStego100K, with specific results and analysis details in the experimental part. We hope that the IStego100K dataset will further promote the development of universal image steganalysis technology. The description of IStego100K and instructions for use can be found at https://github.com/YangzlTHU/IStego100K
Adversarial Learning for Image Forensics Deep Matching with Atrous Convolution
Sep 08, 2018



Constrained image splicing detection and localization (CISDL) is a newly proposed challenging task for image forensics, which investigates two input suspected images and identifies whether one image has suspected regions pasted from the other. In this paper, we propose a novel adversarial learning framework to train the deep matching network for CISDL. Our framework mainly consists of three building blocks: 1) the deep matching network based on atrous convolution (DMAC) aims to generate two high-quality candidate masks which indicate the suspected regions of the two input images, 2) the detection network is designed to rectify inconsistencies between the two corresponding candidate masks, 3) the discriminative network drives the DMAC network to produce masks that are hard to distinguish from ground-truth ones. In DMAC, atrous convolution is adopted to extract features with rich spatial information, the correlation layer based on the skip architecture is proposed to capture hierarchical features, and atrous spatial pyramid pooling is constructed to localize tampered regions at multiple scales. The detection network and the discriminative network act as the losses with auxiliary parameters to supervise the training of DMAC in an adversarial way. Extensive experiments, conducted on 21 generated testing sets and two public datasets, demonstrate the effectiveness of the proposed framework and the superior performance of DMAC.
Image Forgery Localization Based on Multi-Scale Convolutional Neural Networks
Feb 07, 2018
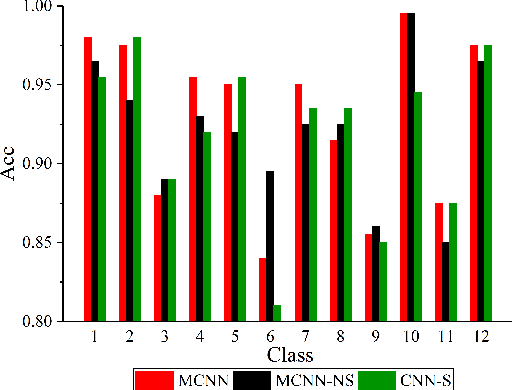


In this paper, we propose to utilize Convolutional Neural Networks (CNNs) and the segmentation-based multi-scale analysis to locate tampered areas in digital images. First, to deal with color input sliding windows of different scales, a unified CNN architecture is designed. Then, we elaborately design the training procedures of CNNs on sampled training patches. With a set of robust multi-scale tampering detectors based on CNNs, complementary tampering possibility maps can be generated. Last but not least, a segmentation-based method is proposed to fuse the maps and generate the final decision map. By exploiting the benefits of both the small-scale and large-scale analyses, the segmentation-based multi-scale analysis can lead to a performance leap in forgery localization of CNNs. Numerous experiments are conducted to demonstrate the effectiveness and efficiency of our method.
Digital image splicing detection based on Markov features in QDCT and QWT domain
Dec 21, 2017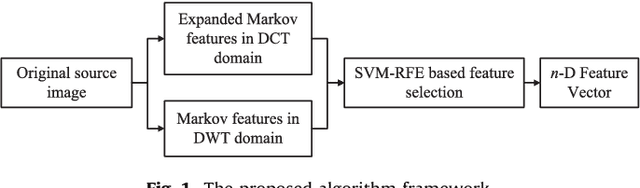
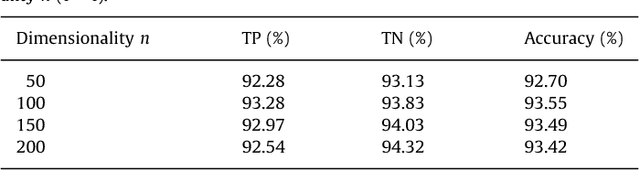


Image splicing detection is of fundamental importance in digital forensics and therefore has attracted increasing attention recently. In this paper, a color image splicing detection approach is proposed based on Markov transition probability of quaternion component separation in quaternion discrete cosine transform (QDCT) domain and quaternion wavelet transform (QWT) domain. Firstly, Markov features of the intra-block and inter-block between block QDCT coefficients are obtained from the real part and three imaginary parts of QDCT coefficients respectively. Then, additional Markov features are extracted from luminance (Y) channel in quaternion wavelet transform domain to characterize the dependency of position among quaternion wavelet subband coefficients. Finally, ensemble classifier (EC) is exploited to classify the spliced and authentic color images. The experiment results demonstrate that the proposed approach can outperforms some state-of-the-art methods.