 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentTalk: Cross-lingual Talking Face Generation via Semantic Disentangled Diffusion Model
Mar 24, 2025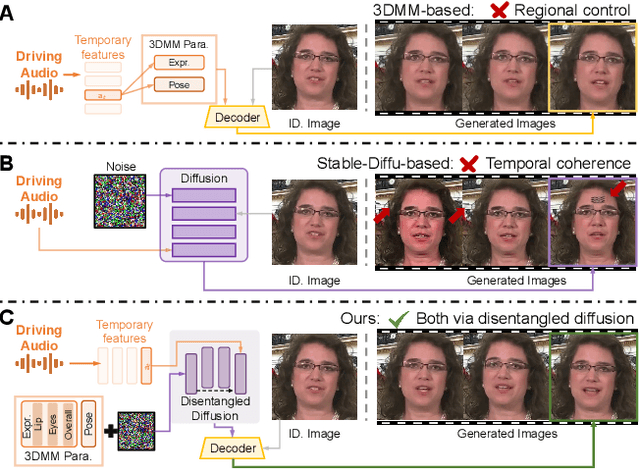
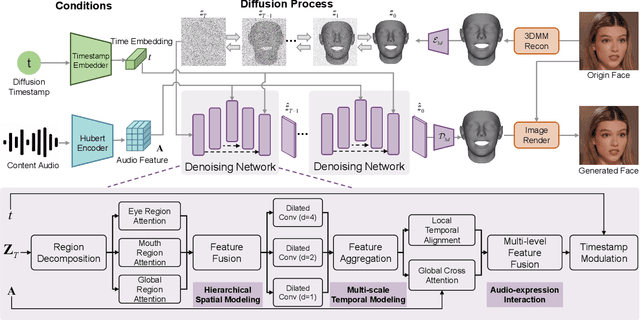
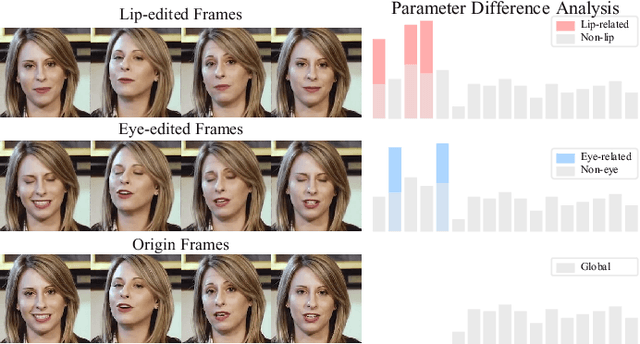

Recent advances in talking face generation have significantly improved facial animation synthesis. However, existing approaches face fundamental limitations: 3DMM-based methods maintain temporal consistency but lack fine-grained regional control, while Stable Diffusion-based methods enable spatial manipulation but suffer from temporal inconsistencies. The integration of these approaches is hindered by incompatible control mechanisms and semantic entanglement of facial representations. This paper presents DisentTalk, introducing a data-driven semantic disentanglement framework that decomposes 3DMM expression parameters into meaningful subspaces for fine-grained facial control. Building upon this disentangled representation, we develop a hierarchical latent diffusion architecture that operates in 3DMM parameter space, integrating region-aware attention mechanisms to ensure both spatial precision and temporal coherence. To address the scarcity of high-quality Chinese training data, we introduce CHDTF, a Chinese high-definition talking face dataset. Extensive experiments show superior performance over existing methods across multiple metrics, including lip synchronization, expression quality, and temporal consistency. Project Page: https://kangweiiliu.github.io/DisentTalk.
Vision Transformer Based Video Hashing Retrieval for Tracing the Source of Fake Videos
Dec 15, 2021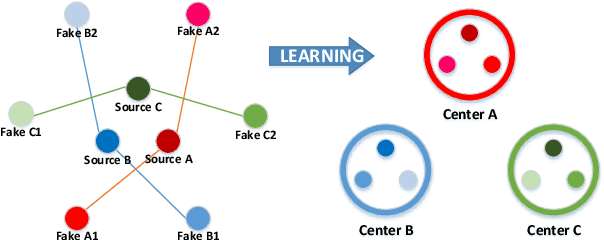
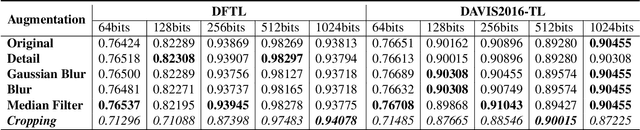
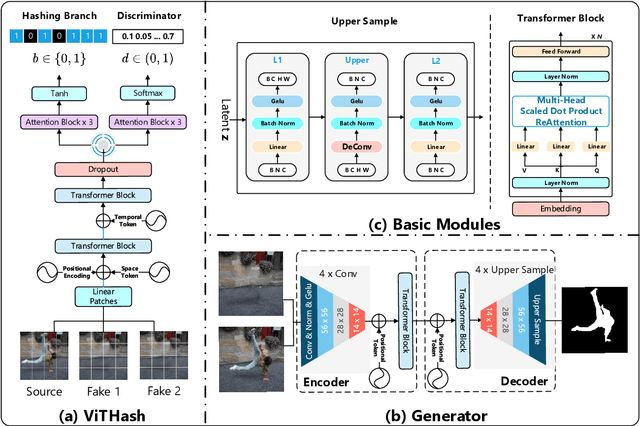

Conventional fake video detection methods outputs a possibility value or a suspected mask of tampering images. However, such unexplainable results cannot be used as convincing evidence. So it is better to trace the sources of fake videos. The traditional hashing methods are used to retrieve semantic-similar images, which can't discriminate the nuances of the image. Specifically, the sources tracing compared with traditional video retrieval. It is a challenge to find the real one from similar source videos. We designed a novel loss Hash Triplet Loss to solve the problem that the videos of people are very similar: the same scene with different angles, similar scenes with the same person. We propose Vision Transformer based models named Video Tracing and Tampering Localization (VTL). In the first stage, we train the hash centers by ViTHash (VTL-T). Then, a fake video is inputted to ViTHash, which outputs a hash code. The hash code is used to retrieve the source video from hash centers. In the second stage, the source video and fake video are inputted to generator (VTL-L). Then, the suspect regions are masked to provide auxiliary information. Moreover, we constructed two datasets: DFTL and DAVIS2016-TL. Experiments on DFTL clearly show the superiority of our framework in sources tracing of similar videos. In particular, the VTL also achieved comparable performance with state-of-the-art methods on DAVIS2016-TL. Our source code and datasets have been released on GitHub: \url{https://github.com/lajlksdf/vtl}.
FMFCC-A: A Challenging Mandarin Dataset for Synthetic Speech Detection
Oct 18, 2021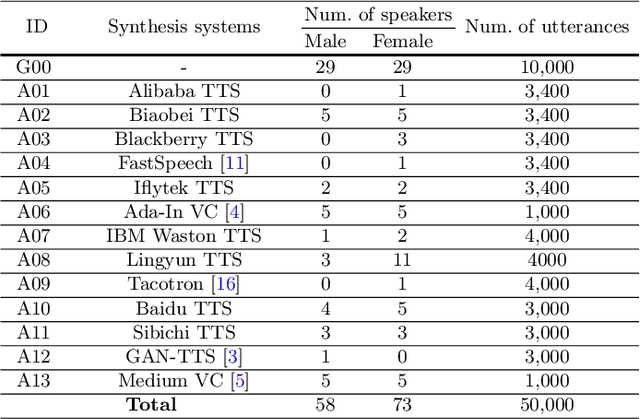
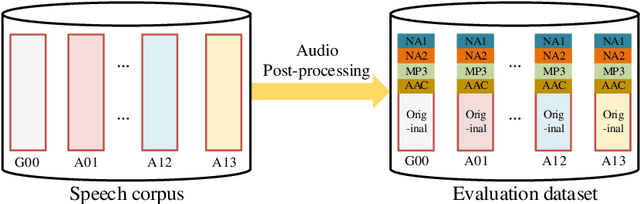

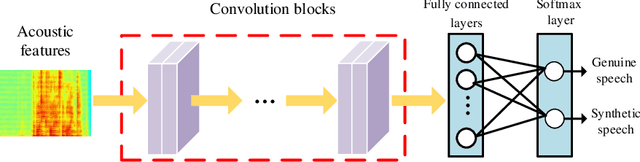
As increasing development of text-to-speech (TTS) and voice conversion (VC) technologies, the detection of synthetic speech has been suffered dramatically. In order to promote the development of synthetic speech detection model against Mandarin TTS and VC technologies, we have constructed a challenging Mandarin dataset and organized the accompanying audio track of the first fake media forensic challenge of China Society of Image and Graphics (FMFCC-A). The FMFCC-A dataset is by far the largest publicly-available Mandarin dataset for synthetic speech detection, which contains 40,000 synthesized Mandarin utterances that generated by 11 Mandarin TTS systems and two Mandarin VC systems, and 10,000 genuine Mandarin utterances collected from 58 speakers. The FMFCC-A dataset is divided into the training, development and evaluation sets, which are used for the research of detection of synthesized Mandarin speech under various previously unknown speech synthesis systems or audio post-processing operations. In addition to describing the construction of the FMFCC-A dataset, we provide a detailed analysis of two baseline methods and the top-performing submissions from the FMFCC-A, which illustrates the usefulness and challenge of FMFCC-A dataset. We hope that the FMFCC-A dataset can fill the gap of lack of Mandarin datasets for synthetic speech detection.
MediumVC: Any-to-any voice conversion using synthetic specific-speaker speeches as intermedium features
Oct 06, 2021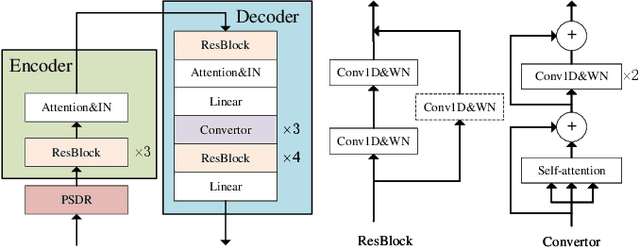
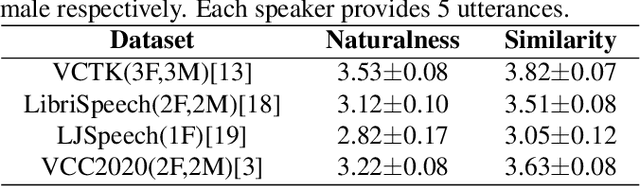
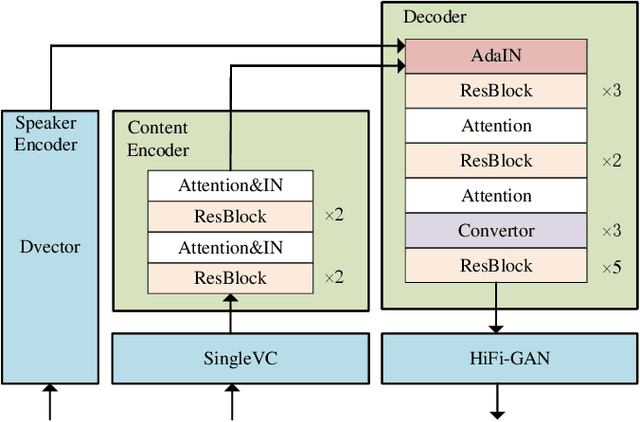

To realize any-to-any (A2A) voice conversion (VC), most methods are to perform symmetric self-supervised reconstruction tasks (Xi to Xi), which usually results in inefficient performances due to inadequate feature decoupling, especially for unseen speakers. We propose a two-stage reconstruction task (Xi to Yi to Xi) using synthetic specific-speaker speeches as intermedium features, where A2A VC is divided into two stages: any-to-one (A2O) and one-to-Any (O2A). In the A2O stage, we propose a new A2O method: SingleVC, by employing a noval data augment strategy(pitch-shifted and duration-remained, PSDR) to accomplish Xi to Yi. In the O2A stage, MediumVC is proposed based on pre-trained SingleVC to conduct Yi to Xi. Through such asymmetrical reconstruction tasks (Xi to Yi in SingleVC and Yi to Xi in MediumVC), the models are to capture robust disentangled features purposefully. Experiments indicate MediumVC can enhance the similarity of converted speeches while maintaining a high degree of naturalness.