 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFMFCC-A: A Challenging Mandarin Dataset for Synthetic Speech Detection
Oct 18, 2021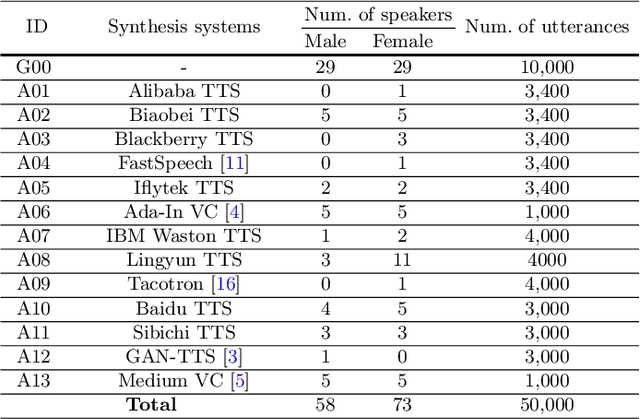
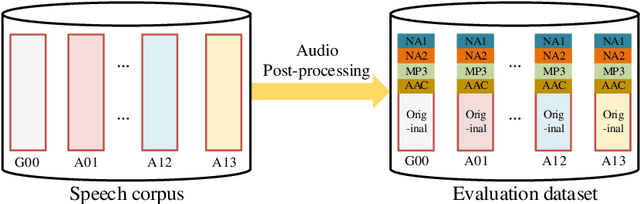

As increasing development of text-to-speech (TTS) and voice conversion (VC) technologies, the detection of synthetic speech has been suffered dramatically. In order to promote the development of synthetic speech detection model against Mandarin TTS and VC technologies, we have constructed a challenging Mandarin dataset and organized the accompanying audio track of the first fake media forensic challenge of China Society of Image and Graphics (FMFCC-A). The FMFCC-A dataset is by far the largest publicly-available Mandarin dataset for synthetic speech detection, which contains 40,000 synthesized Mandarin utterances that generated by 11 Mandarin TTS systems and two Mandarin VC systems, and 10,000 genuine Mandarin utterances collected from 58 speakers. The FMFCC-A dataset is divided into the training, development and evaluation sets, which are used for the research of detection of synthesized Mandarin speech under various previously unknown speech synthesis systems or audio post-processing operations. In addition to describing the construction of the FMFCC-A dataset, we provide a detailed analysis of two baseline methods and the top-performing submissions from the FMFCC-A, which illustrates the usefulness and challenge of FMFCC-A dataset. We hope that the FMFCC-A dataset can fill the gap of lack of Mandarin datasets for synthetic speech detection.
MediumVC: Any-to-any voice conversion using synthetic specific-speaker speeches as intermedium features
Oct 06, 2021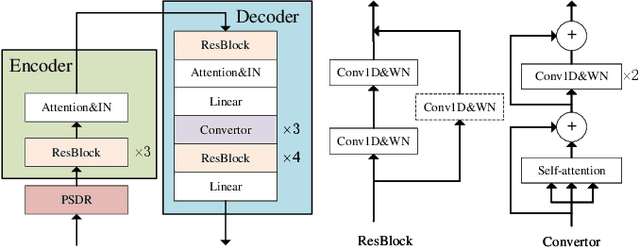
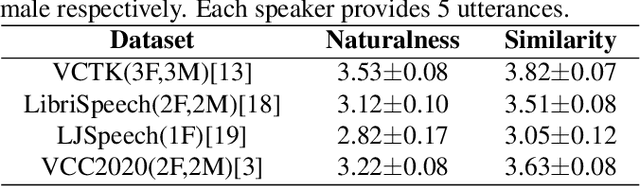
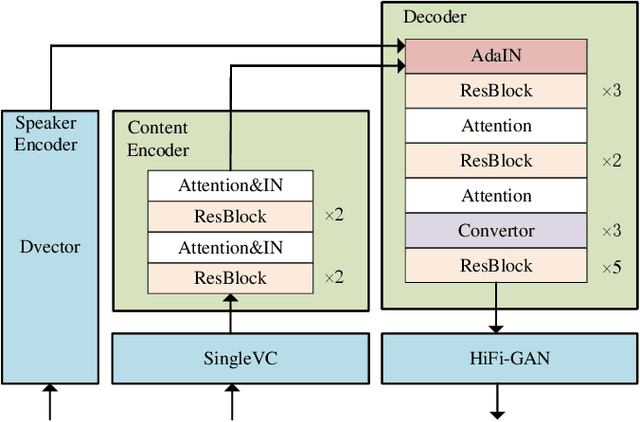

To realize any-to-any (A2A) voice conversion (VC), most methods are to perform symmetric self-supervised reconstruction tasks (Xi to Xi), which usually results in inefficient performances due to inadequate feature decoupling, especially for unseen speakers. We propose a two-stage reconstruction task (Xi to Yi to Xi) using synthetic specific-speaker speeches as intermedium features, where A2A VC is divided into two stages: any-to-one (A2O) and one-to-Any (O2A). In the A2O stage, we propose a new A2O method: SingleVC, by employing a noval data augment strategy(pitch-shifted and duration-remained, PSDR) to accomplish Xi to Yi. In the O2A stage, MediumVC is proposed based on pre-trained SingleVC to conduct Yi to Xi. Through such asymmetrical reconstruction tasks (Xi to Yi in SingleVC and Yi to Xi in MediumVC), the models are to capture robust disentangled features purposefully. Experiments indicate MediumVC can enhance the similarity of converted speeches while maintaining a high degree of naturalness.