 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentTalk: Cross-lingual Talking Face Generation via Semantic Disentangled Diffusion Model
Paper and Code
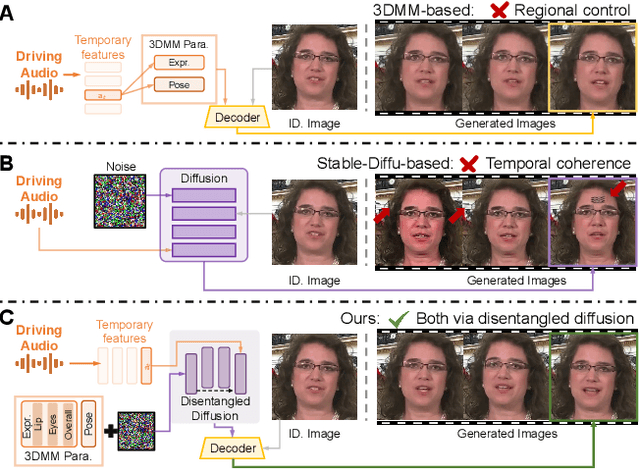
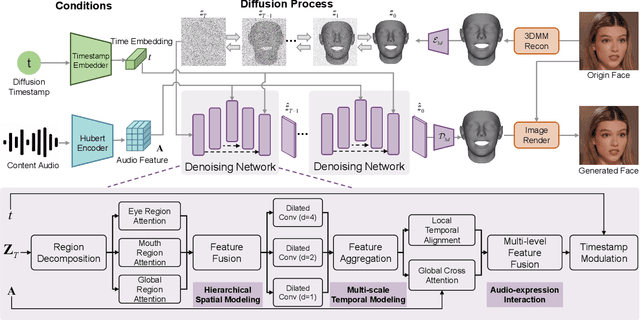
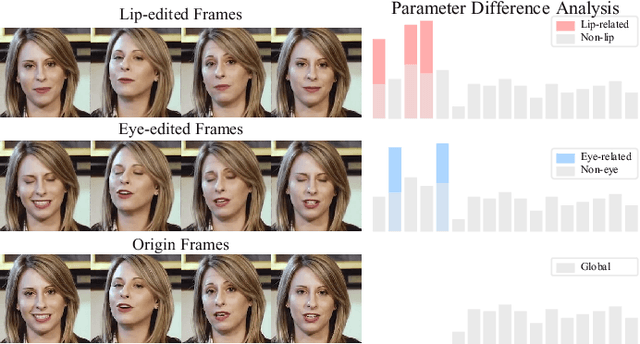

Recent advances in talking face generation have significantly improved facial animation synthesis. However, existing approaches face fundamental limitations: 3DMM-based methods maintain temporal consistency but lack fine-grained regional control, while Stable Diffusion-based methods enable spatial manipulation but suffer from temporal inconsistencies. The integration of these approaches is hindered by incompatible control mechanisms and semantic entanglement of facial representations. This paper presents DisentTalk, introducing a data-driven semantic disentanglement framework that decomposes 3DMM expression parameters into meaningful subspaces for fine-grained facial control. Building upon this disentangled representation, we develop a hierarchical latent diffusion architecture that operates in 3DMM parameter space, integrating region-aware attention mechanisms to ensure both spatial precision and temporal coherence. To address the scarcity of high-quality Chinese training data, we introduce CHDTF, a Chinese high-definition talking face dataset. Extensive experiments show superior performance over existing methods across multiple metrics, including lip synchronization, expression quality, and temporal consistency. Project Page: https://kangweiiliu.github.io/DisentTalk.