 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIStego100K: Large-scale Image Steganalysis Dataset
Paper and Code
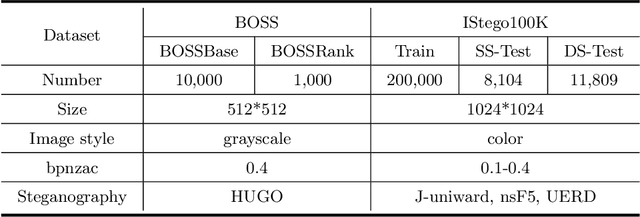

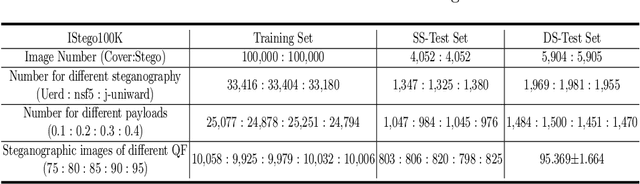
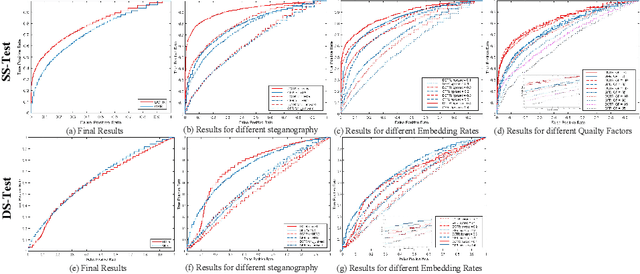
In order to promote the rapid development of image steganalysis technology, in this paper, we construct and release a multivariable large-scale image steganalysis dataset called IStego100K. It contains 208,104 images with the same size of 1024*1024. Among them, 200,000 images (100,000 cover-stego image pairs) are divided as the training set and the remaining 8,104 as testing set. In addition, we hope that IStego100K can help researchers further explore the development of universal image steganalysis algorithms, so we try to reduce limits on the images in IStego100K. For each image in IStego100K, the quality factors is randomly set in the range of 75-95, the steganographic algorithm is randomly selected from three well-known steganographic algorithms, which are J-uniward, nsF5 and UERD, and the embedding rate is also randomly set to be a value of 0.1-0.4. In addition, considering the possible mismatch between training samples and test samples in real environment, we add a test set (DS-Test) whose source of samples are different from the training set. We hope that this test set can help to evaluate the robustness of steganalysis algorithms. We tested the performance of some latest steganalysis algorithms on IStego100K, with specific results and analysis details in the experimental part. We hope that the IStego100K dataset will further promote the development of universal image steganalysis technology. The description of IStego100K and instructions for use can be found at https://github.com/YangzlTHU/IStego100K