 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergistic Signals: Exploiting Co-Engagement and Semantic Links via Graph Neural Networks
Dec 07, 2023



Given a set of candidate entities (e.g. movie titles), the ability to identify similar entities is a core capability of many recommender systems. Most often this is achieved by collaborative filtering approaches, i.e. if users co-engage with a pair of entities frequently enough, the embeddings should be similar. However, relying on co-engagement data alone can result in lower-quality embeddings for new and unpopular entities. We study this problem in the context recommender systems at Netflix. We observe that there is abundant semantic information such as genre, content maturity level, themes, etc. that complements co-engagement signals and provides interpretability in similarity models. To learn entity similarities from both data sources holistically, we propose a novel graph-based approach called SemanticGNN. SemanticGNN models entities, semantic concepts, collaborative edges, and semantic edges within a large-scale knowledge graph and conducts representation learning over it. Our key technical contributions are twofold: (1) we develop a novel relation-aware attention graph neural network (GNN) to handle the imbalanced distribution of relation types in our graph; (2) to handle web-scale graph data that has millions of nodes and billions of edges, we develop a novel distributed graph training paradigm. The proposed model is successfully deployed within Netflix and empirical experiments indicate it yields up to 35% improvement in performance on similarity judgment tasks.
InTune: Reinforcement Learning-based Data Pipeline Optimization for Deep Recommendation Models
Aug 13, 2023



Deep learning-based recommender models (DLRMs) have become an essential component of many modern recommender systems. Several companies are now building large compute clusters reserved only for DLRM training, driving new interest in cost- and time- saving optimizations. The systems challenges faced in this setting are unique; while typical deep learning training jobs are dominated by model execution, the most important factor in DLRM training performance is often online data ingestion. In this paper, we explore the unique characteristics of this data ingestion problem and provide insights into DLRM training pipeline bottlenecks and challenges. We study real-world DLRM data processing pipelines taken from our compute cluster at Netflix to observe the performance impacts of online ingestion and to identify shortfalls in existing pipeline optimizers. We find that current tooling either yields sub-optimal performance, frequent crashes, or else requires impractical cluster re-organization to adopt. Our studies lead us to design and build a new solution for data pipeline optimization, InTune. InTune employs a reinforcement learning (RL) agent to learn how to distribute the CPU resources of a trainer machine across a DLRM data pipeline to more effectively parallelize data loading and improve throughput. Our experiments show that InTune can build an optimized data pipeline configuration within only a few minutes, and can easily be integrated into existing training workflows. By exploiting the responsiveness and adaptability of RL, InTune achieves higher online data ingestion rates than existing optimizers, thus reducing idle times in model execution and increasing efficiency. We apply InTune to our real-world cluster, and find that it increases data ingestion throughput by as much as 2.29X versus state-of-the-art data pipeline optimizers while also improving both CPU & GPU utilization.
On Negative Sampling for Audio-Visual Contrastive Learning from Movies
Apr 29, 2022
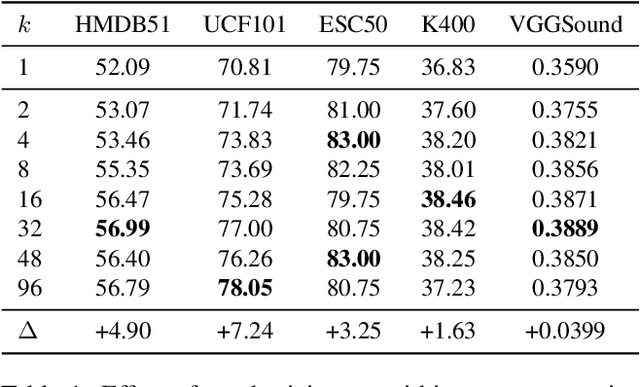
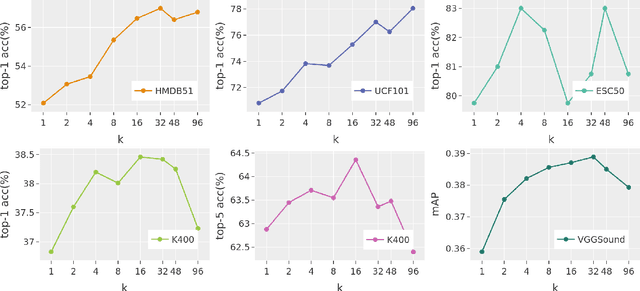
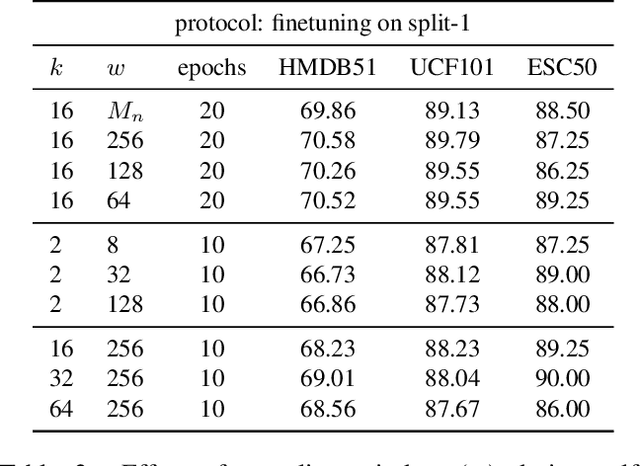
The abundance and ease of utilizing sound, along with the fact that auditory clues reveal a plethora of information about what happens in a scene, make the audio-visual space an intuitive choice for representation learning. In this paper, we explore the efficacy of audio-visual self-supervised learning from uncurated long-form content i.e movies. Studying its differences with conventional short-form content, we identify a non-i.i.d distribution of data, driven by the nature of movies. Specifically, we find long-form content to naturally contain a diverse set of semantic concepts (semantic diversity), where a large portion of them, such as main characters and environments often reappear frequently throughout the movie (reoccurring semantic concepts). In addition, movies often contain content-exclusive artistic artifacts, such as color palettes or thematic music, which are strong signals for uniquely distinguishing a movie (non-semantic consistency). Capitalizing on these observations, we comprehensively study the effect of emphasizing within-movie negative sampling in a contrastive learning setup. Our view is different from those of prior works who consider within-video positive sampling, inspired by the notion of semantic persistency over time, and operate in a short-video regime. Our empirical findings suggest that, with certain modifications, training on uncurated long-form videos yields representations which transfer competitively with the state-of-the-art to a variety of action recognition and audio classification tasks.
Detection of Deepfake Videos Using Long Distance Attention
Jun 24, 2021
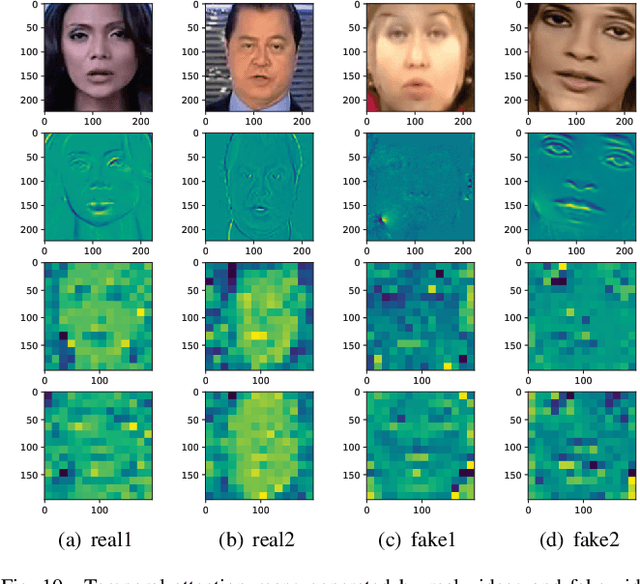
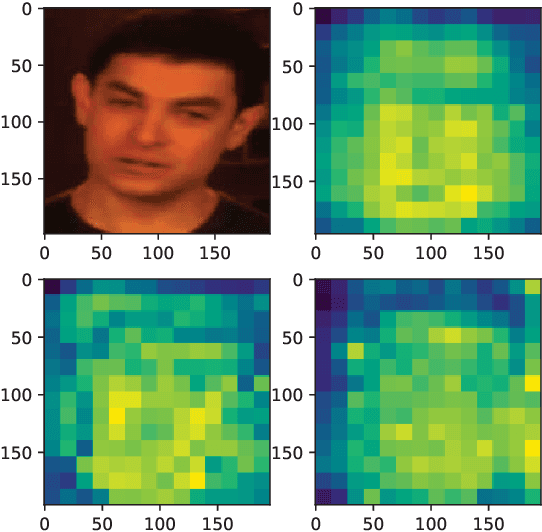

With the rapid progress of deepfake techniques in recent years, facial video forgery can generate highly deceptive video contents and bring severe security threats. And detection of such forgery videos is much more urgent and challenging. Most existing detection methods treat the problem as a vanilla binary classification problem. In this paper, the problem is treated as a special fine-grained classification problem since the differences between fake and real faces are very subtle. It is observed that most existing face forgery methods left some common artifacts in the spatial domain and time domain, including generative defects in the spatial domain and inter-frame inconsistencies in the time domain. And a spatial-temporal model is proposed which has two components for capturing spatial and temporal forgery traces in global perspective respectively. The two components are designed using a novel long distance attention mechanism. The one component of the spatial domain is used to capture artifacts in a single frame, and the other component of the time domain is used to capture artifacts in consecutive frames. They generate attention maps in the form of patches. The attention method has a broader vision which contributes to better assembling global information and extracting local statistic information. Finally, the attention maps are used to guide the network to focus on pivotal parts of the face, just like other fine-grained classification methods. The experimental results on different public datasets demonstrate that the proposed method achieves the state-of-the-art performance, and the proposed long distance attention method can effectively capture pivotal parts for face forgery.
Watching Too Much Television is Good: Self-Supervised Audio-Visual Representation Learning from Movies and TV Shows
Jun 16, 2021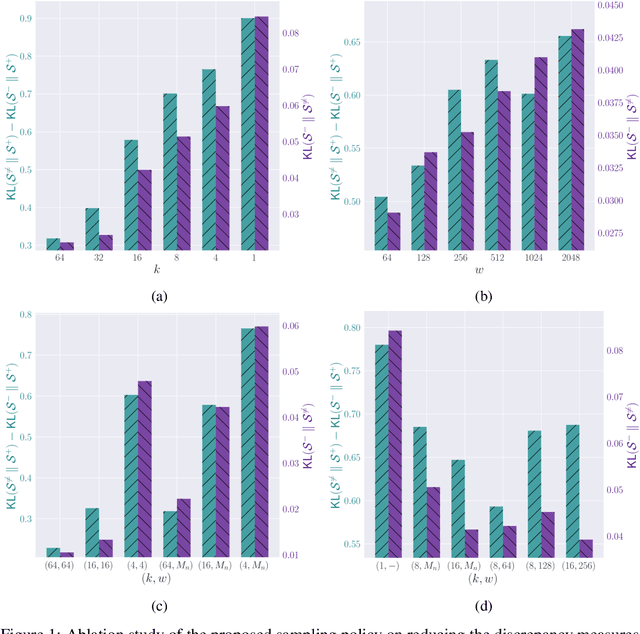
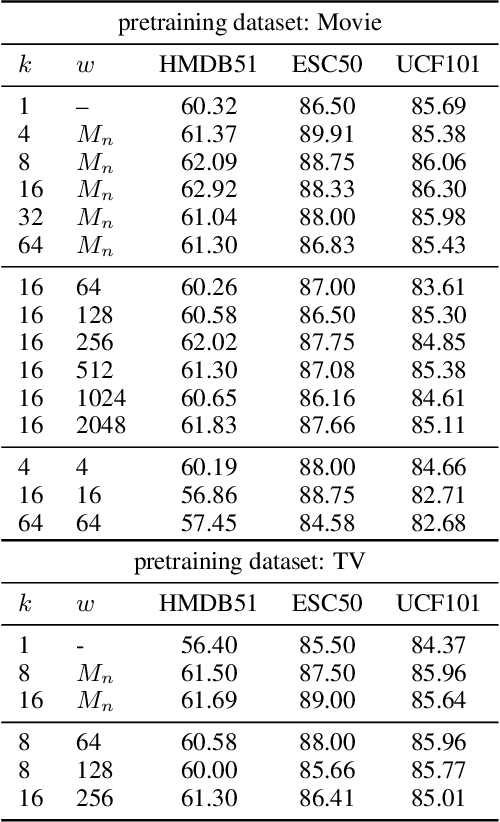
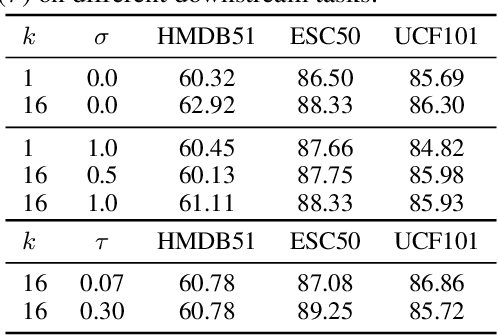
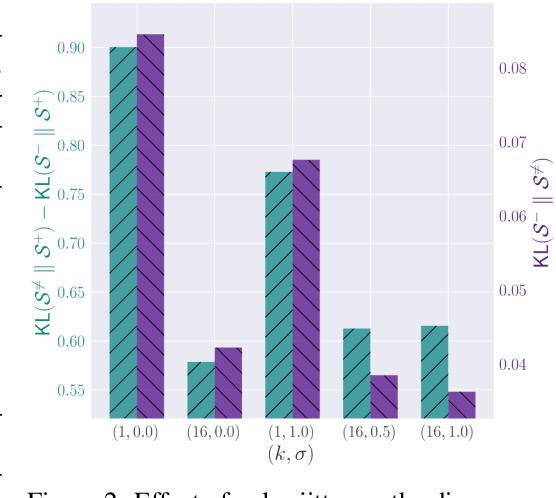
The abundance and ease of utilizing sound, along with the fact that auditory clues reveal so much about what happens in the scene, make the audio-visual space a perfectly intuitive choice for self-supervised representation learning. However, the current literature suggests that training on \textit{uncurated} data yields considerably poorer representations compared to the \textit{curated} alternatives collected in supervised manner, and the gap only narrows when the volume of data significantly increases. Furthermore, the quality of learned representations is known to be heavily influenced by the size and taxonomy of the curated datasets used for self-supervised training. This begs the question of whether we are celebrating too early on catching up with supervised learning when our self-supervised efforts still rely almost exclusively on curated data. In this paper, we study the efficacy of learning from Movies and TV Shows as forms of uncurated data for audio-visual self-supervised learning. We demonstrate that a simple model based on contrastive learning, trained on a collection of movies and TV shows, not only dramatically outperforms more complex methods which are trained on orders of magnitude larger uncurated datasets, but also performs very competitively with the state-of-the-art that learns from large-scale curated data. We identify that audiovisual patterns like the appearance of the main character or prominent scenes and mise-en-sc\`ene which frequently occur through the whole duration of a movie, lead to an overabundance of easy negative instances in the contrastive learning formulation. Capitalizing on such observation, we propose a hierarchical sampling policy, which despite its simplicity, effectively improves the performance, particularly when learning from TV shows which naturally face less semantic diversity.
Locality-Aware Rotated Ship Detection in High-Resolution Remote Sensing Imagery Based on Multi-Scale Convolutional Network
Jul 24, 2020
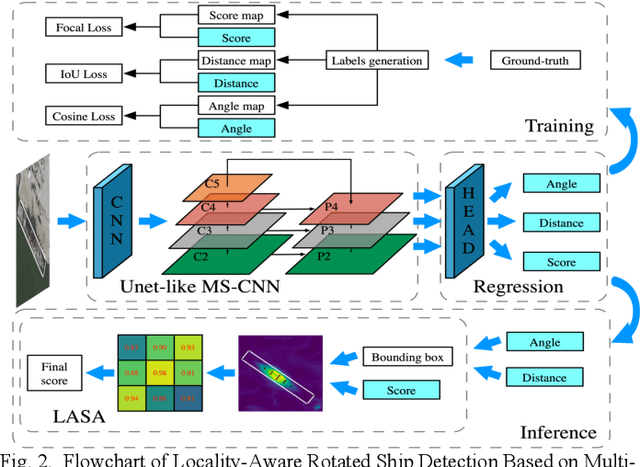
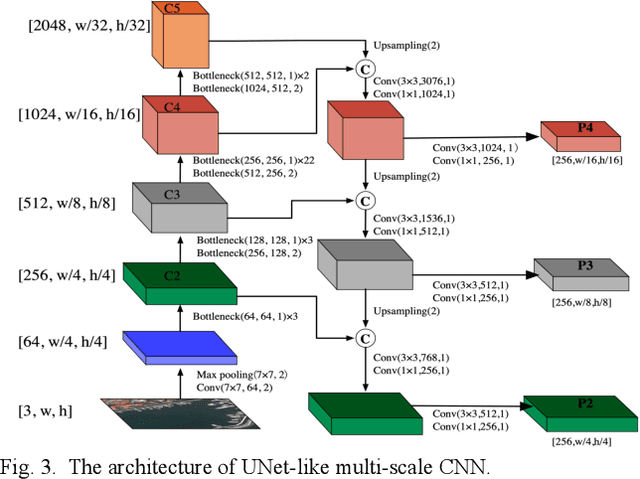
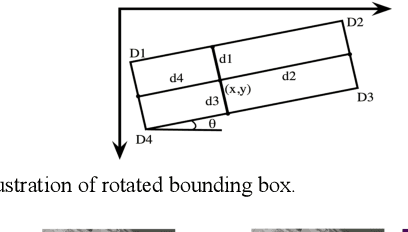
Ship detection has been an active and vital topic in the field of remote sensing for a decade, but it is still a challenging problem due to the large scale variations, the high aspect ratios, the intensive arrangement, and the background clutter disturbance. In this letter, we propose a locality-aware rotated ship detection (LARSD) framework based on a multi-scale convolutional neural network (CNN) to tackle these issues. The proposed framework applies a UNet-like multi-scale CNN to generate multi-scale feature maps with high-level semantic information in high resolution. Then, a rotated anchor-based regression is applied for directly predicting the probability, the edge distances, and the angle of ships. Finally, a locality-aware score alignment is proposed to fix the mismatch between classification results and location results caused by the independence of each subnet. Furthermore, to enlarge the datasets of ship detection, we build a new high-resolution ship detection (HRSD) dataset, where 2499 images and 9269 instances were collected from Google Earth with different resolutions. Experiments based on public dataset HRSC2016 and our HRSD dataset demonstrate that our detection method achieves state-of-the-art performance.