 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Bias-Variance Characteristics of LIME and SHAP in High Sparsity Movie Recommendation Explanation Tasks
Jun 09, 2022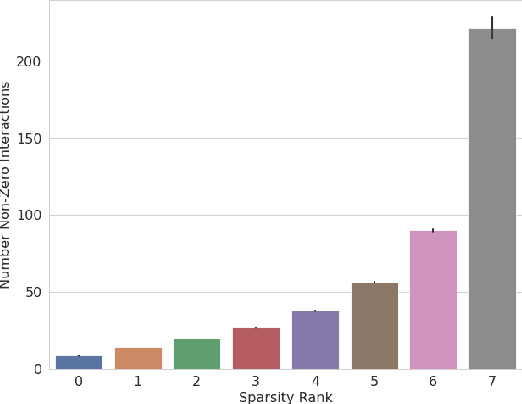
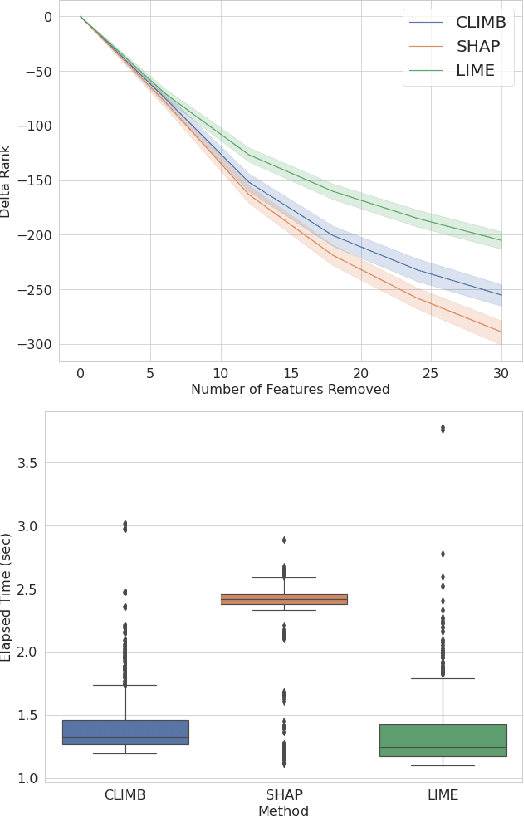
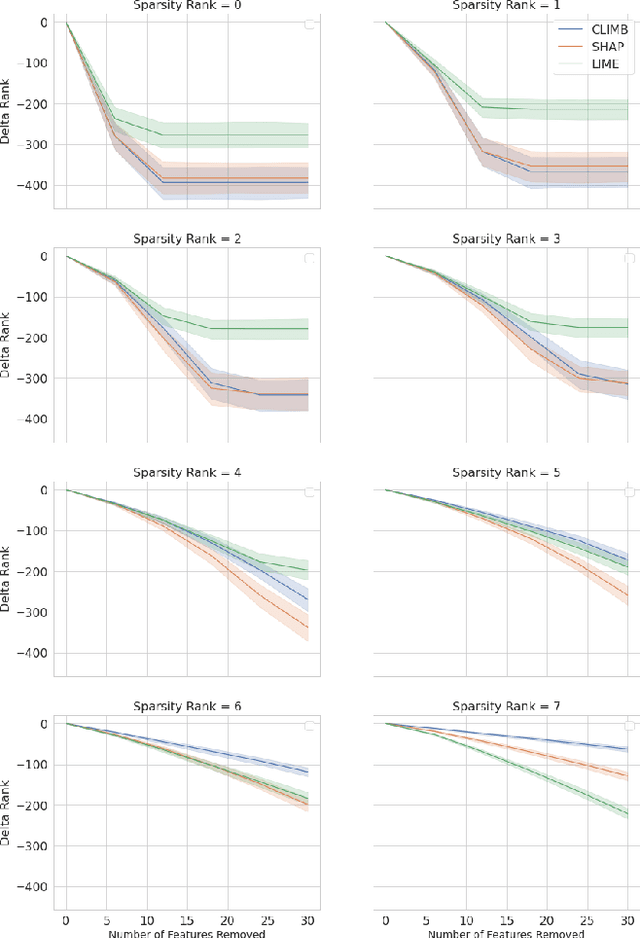
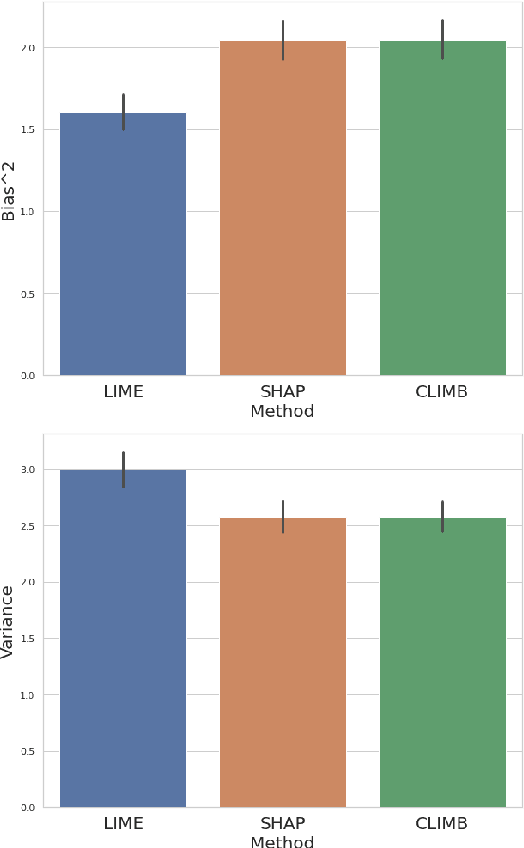
We evaluate two popular local explainability techniques, LIME and SHAP, on a movie recommendation task. We discover that the two methods behave very differently depending on the sparsity of the data set. LIME does better than SHAP in dense segments of the data set and SHAP does better in sparse segments. We trace this difference to the differing bias-variance characteristics of the underlying estimators of LIME and SHAP. We find that SHAP exhibits lower variance in sparse segments of the data compared to LIME. We attribute this lower variance to the completeness constraint property inherent in SHAP and missing in LIME. This constraint acts as a regularizer and therefore increases the bias of the SHAP estimator but decreases its variance, leading to a favorable bias-variance trade-off especially in high sparsity data settings. With this insight, we introduce the same constraint into LIME and formulate a novel local explainabilty framework called Completeness-Constrained LIME (CLIMB) that is superior to LIME and much faster than SHAP.
On Negative Sampling for Audio-Visual Contrastive Learning from Movies
Apr 29, 2022
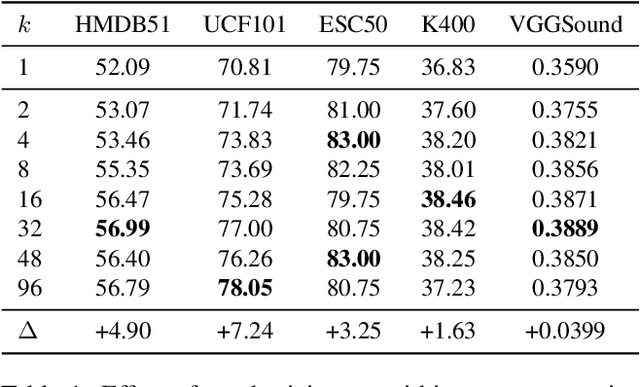
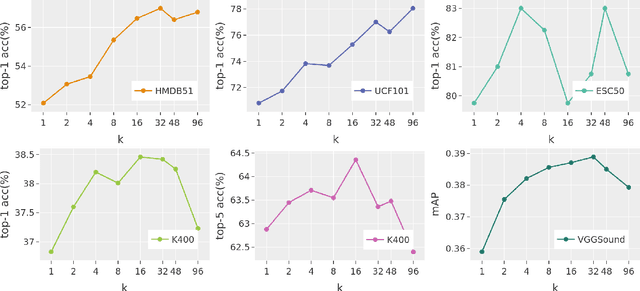
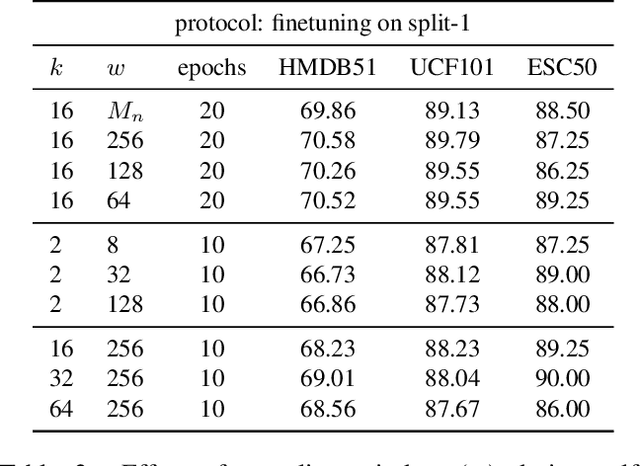
The abundance and ease of utilizing sound, along with the fact that auditory clues reveal a plethora of information about what happens in a scene, make the audio-visual space an intuitive choice for representation learning. In this paper, we explore the efficacy of audio-visual self-supervised learning from uncurated long-form content i.e movies. Studying its differences with conventional short-form content, we identify a non-i.i.d distribution of data, driven by the nature of movies. Specifically, we find long-form content to naturally contain a diverse set of semantic concepts (semantic diversity), where a large portion of them, such as main characters and environments often reappear frequently throughout the movie (reoccurring semantic concepts). In addition, movies often contain content-exclusive artistic artifacts, such as color palettes or thematic music, which are strong signals for uniquely distinguishing a movie (non-semantic consistency). Capitalizing on these observations, we comprehensively study the effect of emphasizing within-movie negative sampling in a contrastive learning setup. Our view is different from those of prior works who consider within-video positive sampling, inspired by the notion of semantic persistency over time, and operate in a short-video regime. Our empirical findings suggest that, with certain modifications, training on uncurated long-form videos yields representations which transfer competitively with the state-of-the-art to a variety of action recognition and audio classification tasks.
Watching Too Much Television is Good: Self-Supervised Audio-Visual Representation Learning from Movies and TV Shows
Jun 16, 2021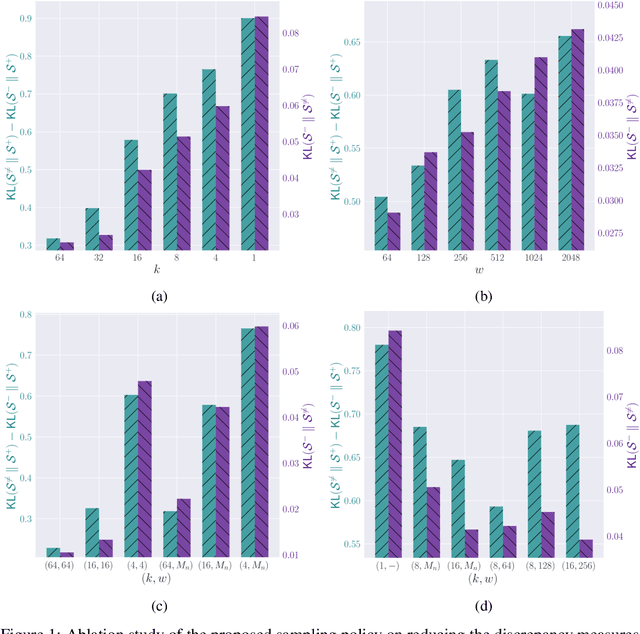
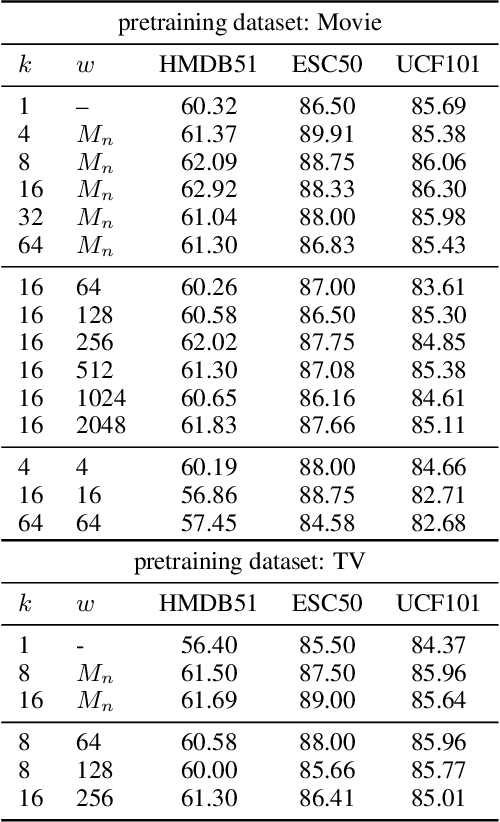
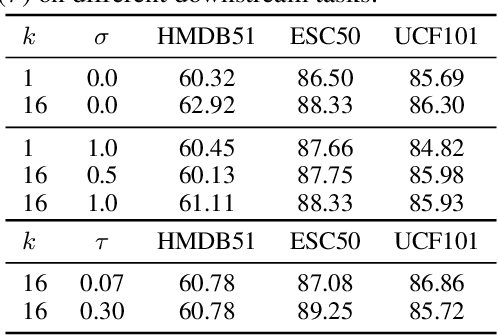
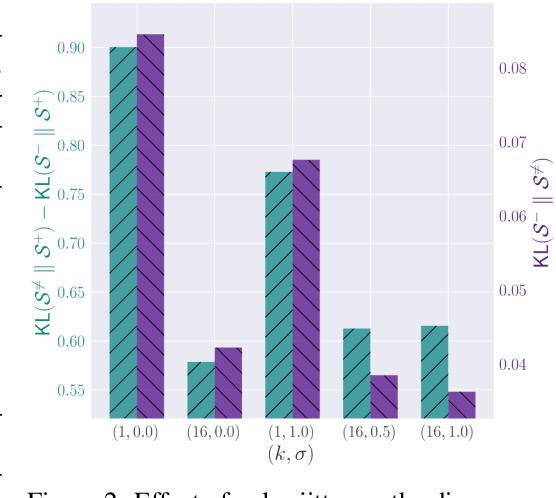
The abundance and ease of utilizing sound, along with the fact that auditory clues reveal so much about what happens in the scene, make the audio-visual space a perfectly intuitive choice for self-supervised representation learning. However, the current literature suggests that training on \textit{uncurated} data yields considerably poorer representations compared to the \textit{curated} alternatives collected in supervised manner, and the gap only narrows when the volume of data significantly increases. Furthermore, the quality of learned representations is known to be heavily influenced by the size and taxonomy of the curated datasets used for self-supervised training. This begs the question of whether we are celebrating too early on catching up with supervised learning when our self-supervised efforts still rely almost exclusively on curated data. In this paper, we study the efficacy of learning from Movies and TV Shows as forms of uncurated data for audio-visual self-supervised learning. We demonstrate that a simple model based on contrastive learning, trained on a collection of movies and TV shows, not only dramatically outperforms more complex methods which are trained on orders of magnitude larger uncurated datasets, but also performs very competitively with the state-of-the-art that learns from large-scale curated data. We identify that audiovisual patterns like the appearance of the main character or prominent scenes and mise-en-sc\`ene which frequently occur through the whole duration of a movie, lead to an overabundance of easy negative instances in the contrastive learning formulation. Capitalizing on such observation, we propose a hierarchical sampling policy, which despite its simplicity, effectively improves the performance, particularly when learning from TV shows which naturally face less semantic diversity.
Control Variates for Slate Off-Policy Evaluation
Jun 15, 2021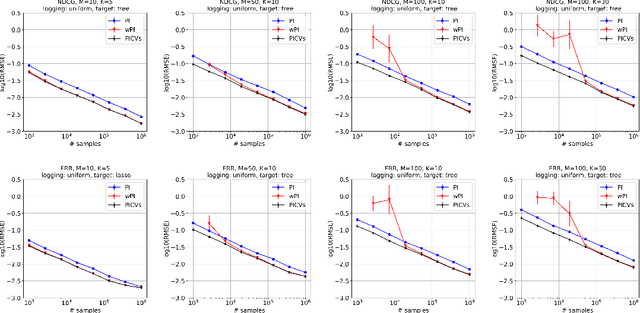
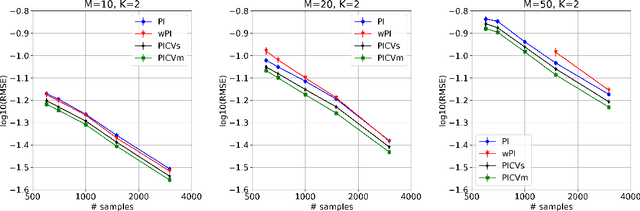
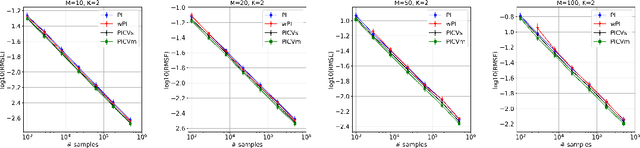
We study the problem of off-policy evaluation from batched contextual bandit data with multidimensional actions, often termed slates. The problem is common to recommender systems and user-interface optimization, and it is particularly challenging because of the combinatorially-sized action space. Swaminathan et al. (2017) have proposed the pseudoinverse (PI) estimator under the assumption that the conditional mean rewards are additive in actions. Using control variates, we consider a large class of unbiased estimators that includes as specific cases the PI estimator and (asymptotically) its self-normalized variant. By optimizing over this class, we obtain new estimators with risk improvement guarantees over both the PI and self-normalized PI estimators. Experiments with real-world recommender data as well as synthetic data validate these improvements in practice.
Off-Policy Evaluation of Slate Policies under Bayes Risk
Jan 05, 2021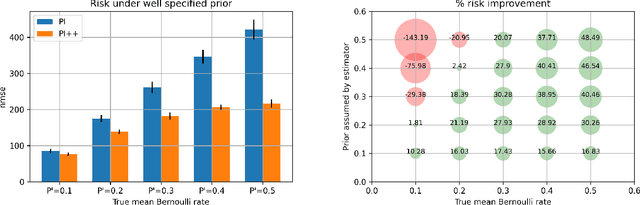
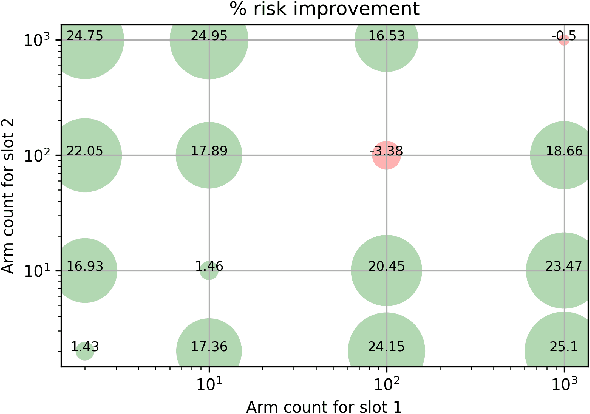
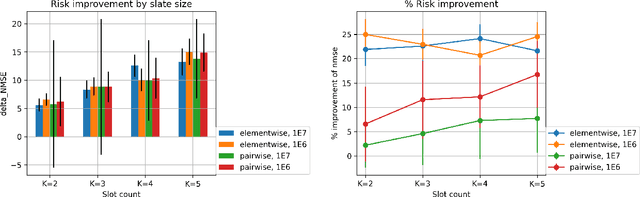
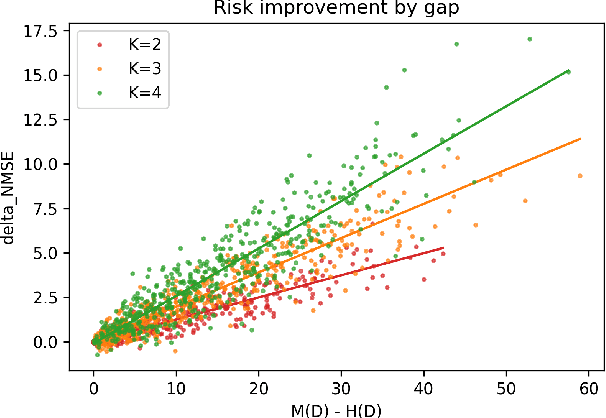
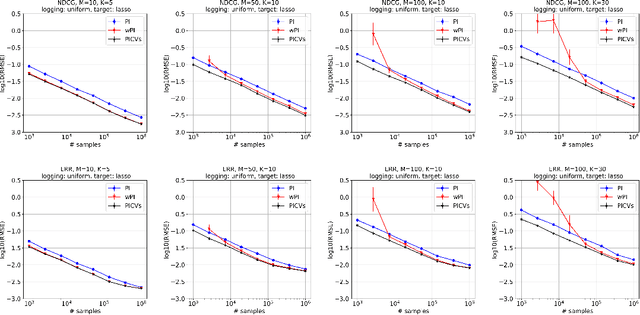
We study the problem of off-policy evaluation for slate bandits, for the typical case in which the logging policy factorizes over the slots of the slate. We slightly depart from the existing literature by taking Bayes risk as the criterion by which to evaluate estimators, and we analyze the family of 'additive' estimators that includes the pseudoinverse (PI) estimator of Swaminathan et al.\ (2017; arXiv:1605.04812). Using a control variate approach, we identify a new estimator in this family that is guaranteed to have lower risk than PI in the above class of problems. In particular, we show that the risk improvement over PI grows linearly with the number of slots, and linearly with the gap between the arithmetic and the harmonic mean of a set of slot-level divergences between the logging and the target policy. In the typical case of a uniform logging policy and a deterministic target policy, each divergence corresponds to slot size, showing that maximal gains can be obtained for slate problems with diverse numbers of actions per slot.
Learning Representations of Hierarchical Slates in Collaborative Filtering
Sep 25, 2020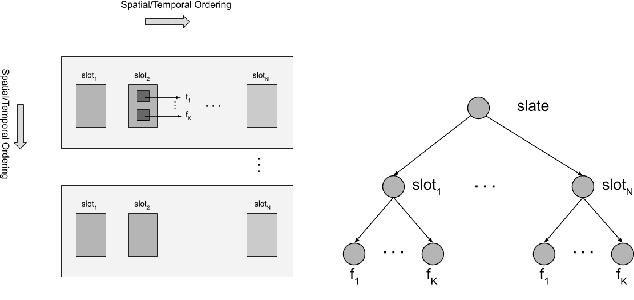
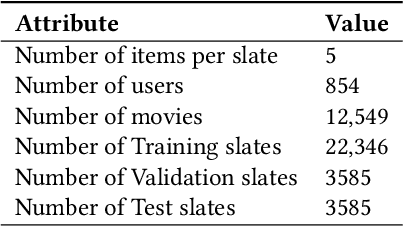

We are interested in building collaborative filtering models for recommendation systems where users interact with slates instead of individual items. These slates can be hierarchical in nature. The central idea of our approach is to learn low dimensional embeddings of these slates. We present a novel way to learn these embeddings by making use of the (unknown) statistics of the underlying distribution generating the hierarchical data. Our representation learning algorithm can be viewed as a simple composition rule that can be applied recursively in a bottom-up fashion to represent arbitrarily complex hierarchical structures in terms of the representations of its constituent components. We demonstrate our ideas on two real world recommendation systems datasets including the one used for the RecSys 2019 challenge. For that dataset, we improve upon the performance achieved by the winning team's model by incorporating embeddings as features generated by our approach in their solution.