 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Negative Sampling for Audio-Visual Contrastive Learning from Movies
Apr 29, 2022
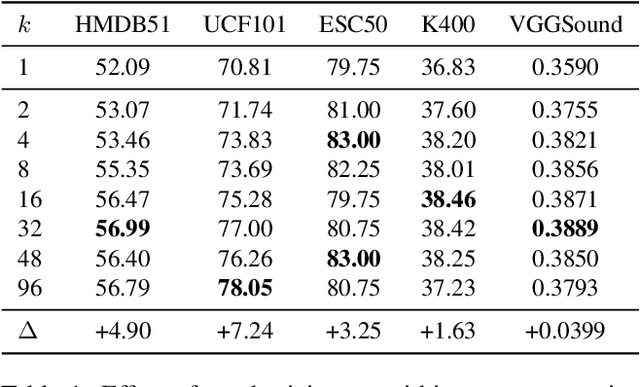
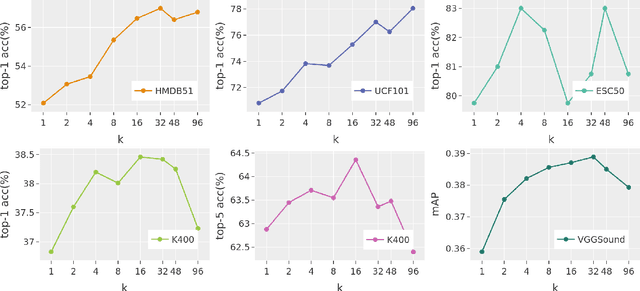
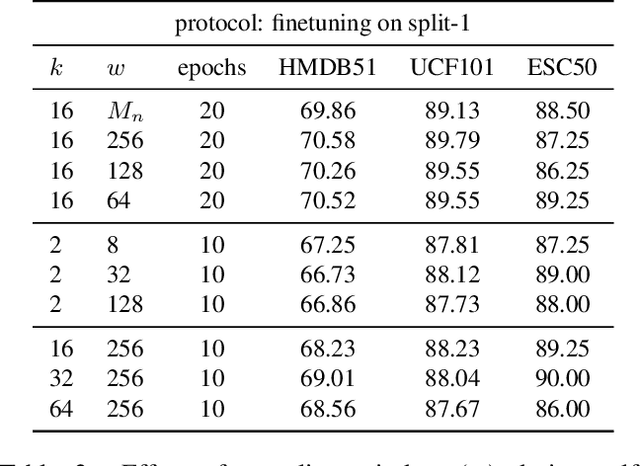
The abundance and ease of utilizing sound, along with the fact that auditory clues reveal a plethora of information about what happens in a scene, make the audio-visual space an intuitive choice for representation learning. In this paper, we explore the efficacy of audio-visual self-supervised learning from uncurated long-form content i.e movies. Studying its differences with conventional short-form content, we identify a non-i.i.d distribution of data, driven by the nature of movies. Specifically, we find long-form content to naturally contain a diverse set of semantic concepts (semantic diversity), where a large portion of them, such as main characters and environments often reappear frequently throughout the movie (reoccurring semantic concepts). In addition, movies often contain content-exclusive artistic artifacts, such as color palettes or thematic music, which are strong signals for uniquely distinguishing a movie (non-semantic consistency). Capitalizing on these observations, we comprehensively study the effect of emphasizing within-movie negative sampling in a contrastive learning setup. Our view is different from those of prior works who consider within-video positive sampling, inspired by the notion of semantic persistency over time, and operate in a short-video regime. Our empirical findings suggest that, with certain modifications, training on uncurated long-form videos yields representations which transfer competitively with the state-of-the-art to a variety of action recognition and audio classification tasks.
Character-focused Video Thumbnail Retrieval
Apr 13, 2022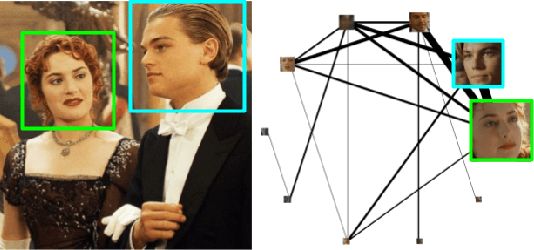
We explore retrieving character-focused video frames as candidates for being video thumbnails. To evaluate each frame of the video based on the character(s) present in it, characters (faces) are evaluated in two aspects: Facial-expression: We train a CNN model to measure whether a face has an acceptable facial expression for being in a video thumbnail. This model is trained to distinguish faces extracted from artworks/thumbnails, from faces extracted from random frames of videos. Prominence and interactions: Character(s) in the thumbnail should be important character(s) in the video, to prevent the algorithm from suggesting non-representative frames as candidates. We use face clustering to identify the characters in the video, and form a graph in which the prominence (frequency of appearance) of the character(s), and their interactions (co-occurrence) are captured. We use this graph to infer the relevance of the characters present in each candidate frame. Once every face is scored based on the two criteria above, we infer frame level scores by combining the scores for all the faces within a frame.
Watching Too Much Television is Good: Self-Supervised Audio-Visual Representation Learning from Movies and TV Shows
Jun 16, 2021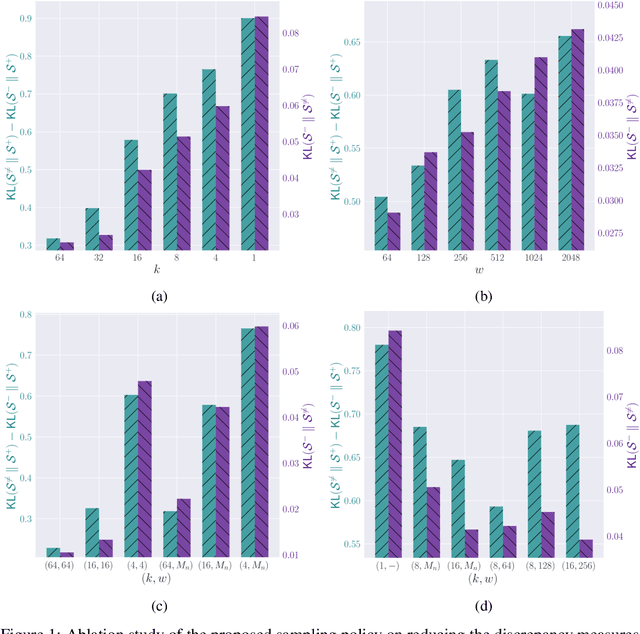
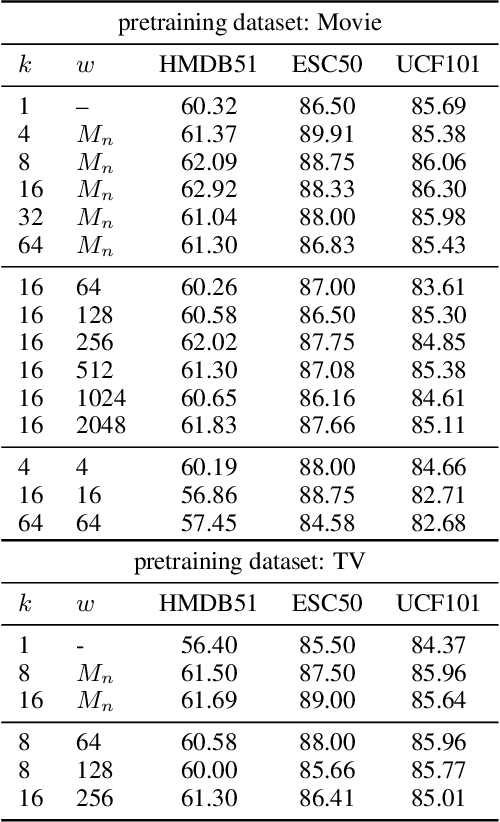
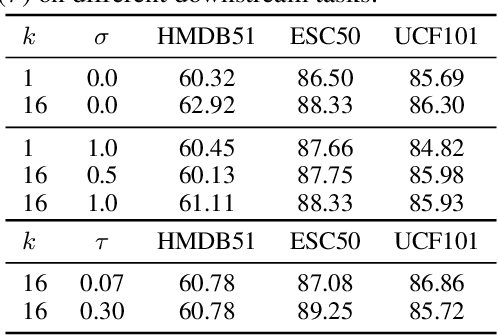
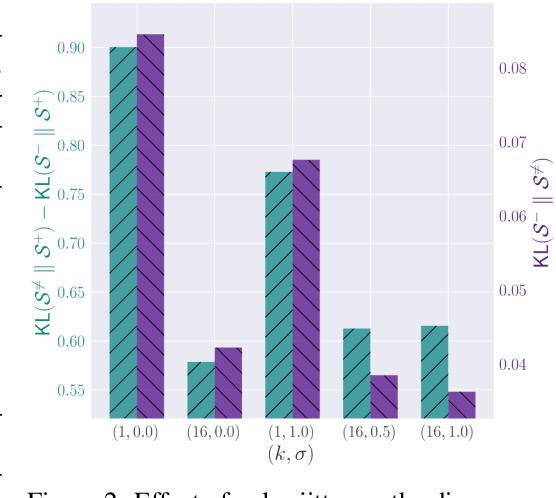
The abundance and ease of utilizing sound, along with the fact that auditory clues reveal so much about what happens in the scene, make the audio-visual space a perfectly intuitive choice for self-supervised representation learning. However, the current literature suggests that training on \textit{uncurated} data yields considerably poorer representations compared to the \textit{curated} alternatives collected in supervised manner, and the gap only narrows when the volume of data significantly increases. Furthermore, the quality of learned representations is known to be heavily influenced by the size and taxonomy of the curated datasets used for self-supervised training. This begs the question of whether we are celebrating too early on catching up with supervised learning when our self-supervised efforts still rely almost exclusively on curated data. In this paper, we study the efficacy of learning from Movies and TV Shows as forms of uncurated data for audio-visual self-supervised learning. We demonstrate that a simple model based on contrastive learning, trained on a collection of movies and TV shows, not only dramatically outperforms more complex methods which are trained on orders of magnitude larger uncurated datasets, but also performs very competitively with the state-of-the-art that learns from large-scale curated data. We identify that audiovisual patterns like the appearance of the main character or prominent scenes and mise-en-sc\`ene which frequently occur through the whole duration of a movie, lead to an overabundance of easy negative instances in the contrastive learning formulation. Capitalizing on such observation, we propose a hierarchical sampling policy, which despite its simplicity, effectively improves the performance, particularly when learning from TV shows which naturally face less semantic diversity.
Composition-Aware Image Aesthetics Assessment
Jul 25, 2019



Automatic image aesthetics assessment is important for a wide variety of applications such as on-line photo suggestion, photo album management and image retrieval. Previous methods have focused on mapping the holistic image content to a high or low aesthetics rating. However, the composition information of an image characterizes the harmony of its visual elements according to the principles of art, and provides richer information for learning aesthetics. In this work, we propose to model the image composition information as the mutual dependency of its local regions, and design a novel architecture to leverage such information to boost the performance of aesthetics assessment. To achieve this, we densely partition an image into local regions and compute aesthetics-preserving features over the regions to characterize the aesthetics properties of image content. With the feature representation of local regions, we build a region composition graph in which each node denotes one region and any two nodes are connected by an edge weighted by the similarity of the region features. We perform reasoning on this graph via graph convolution, in which the activation of each node is determined by its highly correlated neighbors. Our method naturally uncovers the mutual dependency of local regions in the network training procedure, and achieves the state-of-the-art performance on the benchmark visual aesthetics datasets.