 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Trailer Moments in Full-Length Movies
Aug 19, 2020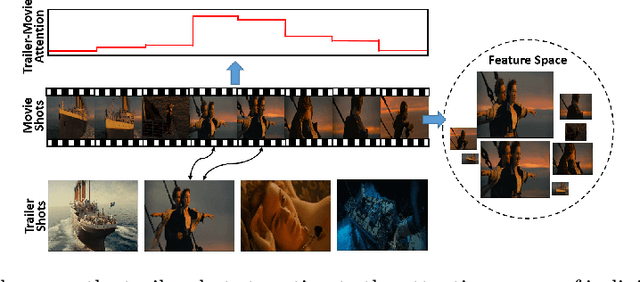
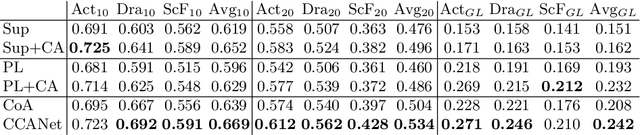
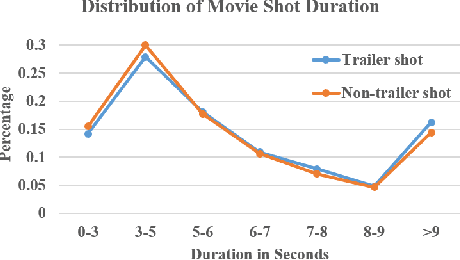
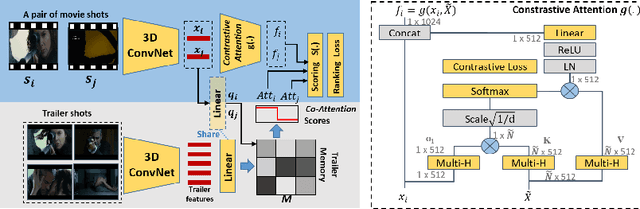
A movie's key moments stand out of the screenplay to grab an audience's attention and make movie browsing efficient. But a lack of annotations makes the existing approaches not applicable to movie key moment detection. To get rid of human annotations, we leverage the officially-released trailers as the weak supervision to learn a model that can detect the key moments from full-length movies. We introduce a novel ranking network that utilizes the Co-Attention between movies and trailers as guidance to generate the training pairs, where the moments highly corrected with trailers are expected to be scored higher than the uncorrelated moments. Additionally, we propose a Contrastive Attention module to enhance the feature representations such that the comparative contrast between features of the key and non-key moments are maximized. We construct the first movie-trailer dataset, and the proposed Co-Attention assisted ranking network shows superior performance even over the supervised approach. The effectiveness of our Contrastive Attention module is also demonstrated by the performance improvement over the state-of-the-art on the public benchmarks.
Composition-Aware Image Aesthetics Assessment
Jul 25, 2019



Automatic image aesthetics assessment is important for a wide variety of applications such as on-line photo suggestion, photo album management and image retrieval. Previous methods have focused on mapping the holistic image content to a high or low aesthetics rating. However, the composition information of an image characterizes the harmony of its visual elements according to the principles of art, and provides richer information for learning aesthetics. In this work, we propose to model the image composition information as the mutual dependency of its local regions, and design a novel architecture to leverage such information to boost the performance of aesthetics assessment. To achieve this, we densely partition an image into local regions and compute aesthetics-preserving features over the regions to characterize the aesthetics properties of image content. With the feature representation of local regions, we build a region composition graph in which each node denotes one region and any two nodes are connected by an edge weighted by the similarity of the region features. We perform reasoning on this graph via graph convolution, in which the activation of each node is determined by its highly correlated neighbors. Our method naturally uncovers the mutual dependency of local regions in the network training procedure, and achieves the state-of-the-art performance on the benchmark visual aesthetics datasets.
On Attention Modules for Audio-Visual Synchronization
Dec 14, 2018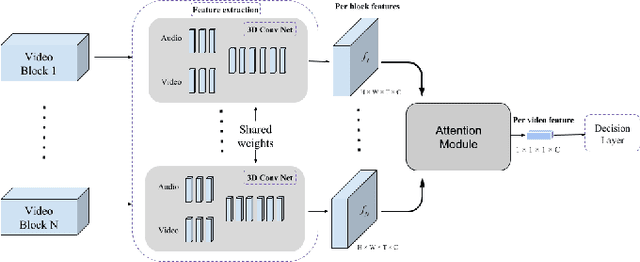
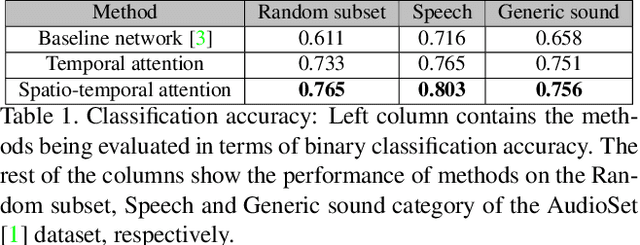
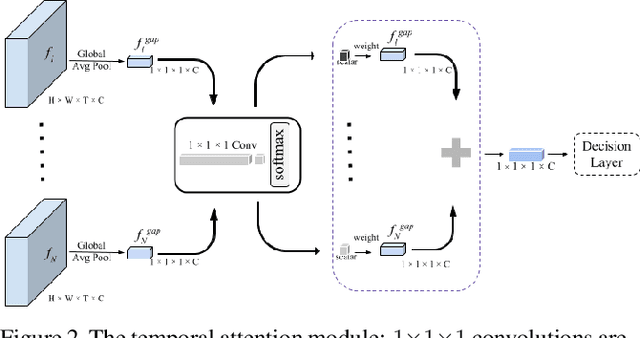
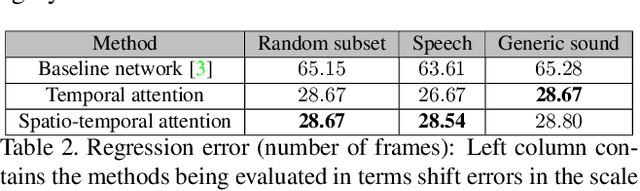
With the development of media and networking technologies, multimedia applications ranging from feature presentation in a cinema setting to video on demand to interactive video conferencing are in great demand. Good synchronization between audio and video modalities is a key factor towards defining the quality of a multimedia presentation. The audio and visual signals of a multimedia presentation are commonly managed by independent workflows - they are often separately authored, processed, stored and even delivered to the playback system. This opens up the possibility of temporal misalignment between the two modalities - such a tendency is often more pronounced in the case of produced content (such as movies). To judge whether audio and video signals of a multimedia presentation are synchronized, we as humans often pay close attention to discriminative spatio-temporal blocks of the video (e.g. synchronizing the lip movement with the utterance of words, or the sound of a bouncing ball at the moment it hits the ground). At the same time, we ignore large portions of the video in which no discriminative sounds exist (e.g. background music playing in a movie). Inspired by this observation, we study leveraging attention modules for automatically detecting audio-visual synchronization. We propose neural network based attention modules, capable of weighting different portions (spatio-temporal blocks) of the video based on their respective discriminative power. Our experiments indicate that incorporating attention modules yields state-of-the-art results for the audio-visual synchronization classification problem.