 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Trailer Moments in Full-Length Movies
Aug 19, 2020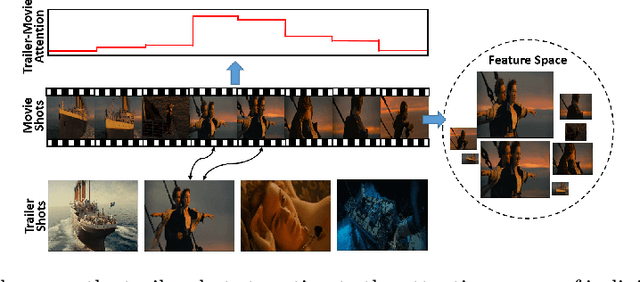
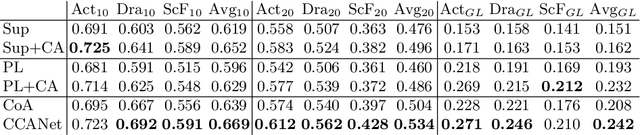
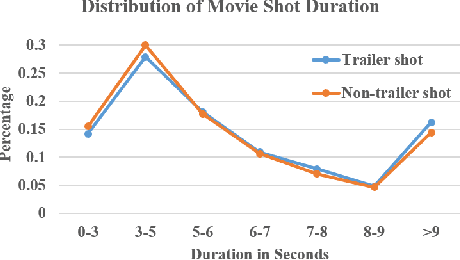
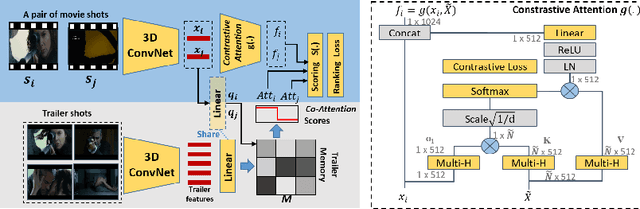
A movie's key moments stand out of the screenplay to grab an audience's attention and make movie browsing efficient. But a lack of annotations makes the existing approaches not applicable to movie key moment detection. To get rid of human annotations, we leverage the officially-released trailers as the weak supervision to learn a model that can detect the key moments from full-length movies. We introduce a novel ranking network that utilizes the Co-Attention between movies and trailers as guidance to generate the training pairs, where the moments highly corrected with trailers are expected to be scored higher than the uncorrelated moments. Additionally, we propose a Contrastive Attention module to enhance the feature representations such that the comparative contrast between features of the key and non-key moments are maximized. We construct the first movie-trailer dataset, and the proposed Co-Attention assisted ranking network shows superior performance even over the supervised approach. The effectiveness of our Contrastive Attention module is also demonstrated by the performance improvement over the state-of-the-art on the public benchmarks.
Unsupervised Domain Adaptation via Calibrating Uncertainties
Jul 25, 2019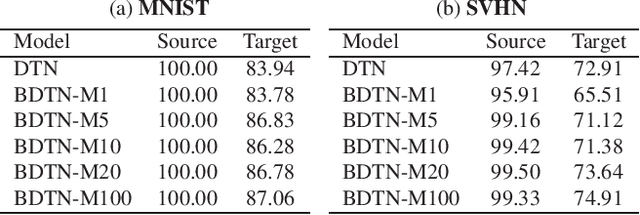
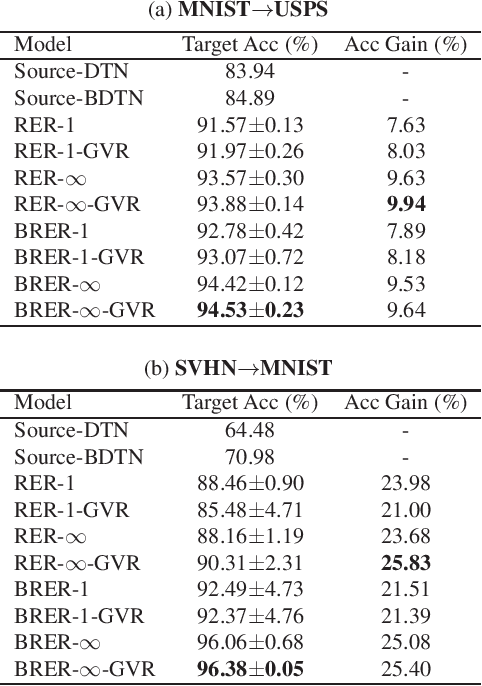
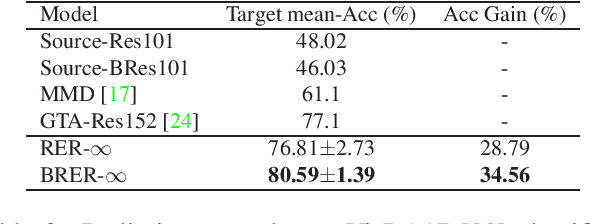
Unsupervised domain adaptation (UDA) aims at inferring class labels for unlabeled target domain given a related labeled source dataset. Intuitively, a model trained on source domain normally produces higher uncertainties for unseen data. In this work, we build on this assumption and propose to adapt from source to target domain via calibrating their predictive uncertainties. The uncertainty is quantified as the Renyi entropy, from which we propose a general Renyi entropy regularization (RER) framework. We further employ variational Bayes learning for reliable uncertainty estimation. In addition, calibrating the sample variance of network parameters serves as a plug-in regularizer for training. We discuss the theoretical properties of the proposed method and demonstrate its effectiveness on three domain-adaptation tasks.
* 4 pages
Reducing Visual Confusion with Discriminative Attention
Nov 19, 2018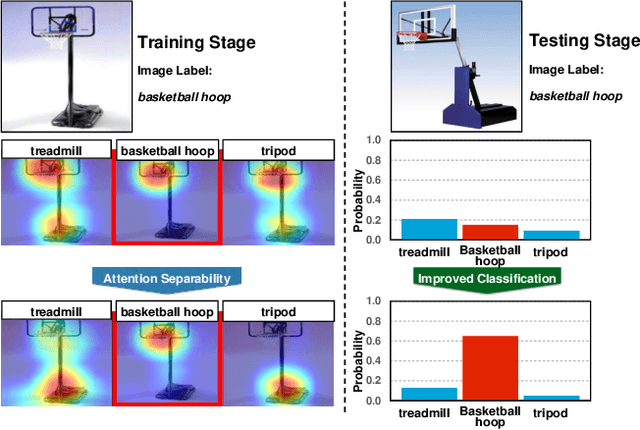
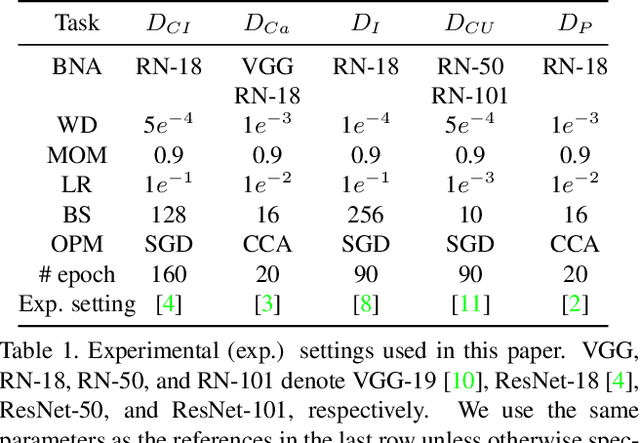
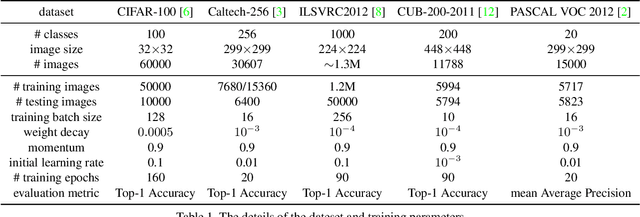
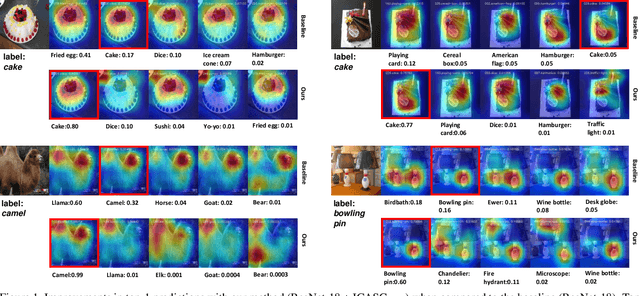
Recent developments in gradient-based attention modeling have led to improved model interpretability by means of class-specific attention maps. A key limitation, however, of these approaches is that the resulting attention maps, while being well localized, are not class discriminative. In this paper, we address this limitation with a new learning framework that makes class-discriminative attention and cross-layer attention consistency a principled and explicit part of the learning process. Furthermore, our framework provides attention guidance to the model in an end-to-end fashion, resulting in better discriminability and reduced visual confusion. We conduct extensive experiments on various image classification benchmarks with our proposed framework and demonstrate its efficacy by means of improved classification accuracy including CIFAR-100 (+3.46%), Caltech-256 (+1.64%), ImageNet (+0.92%), CUB-200-2011 (+4.8%) and PASCAL VOC2012 (+5.78%).
Dual Iterative Hard Thresholding: From Non-convex Sparse Minimization to Non-smooth Concave Maximization
Jun 21, 2017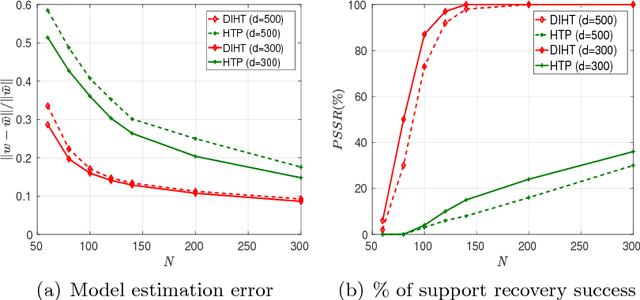
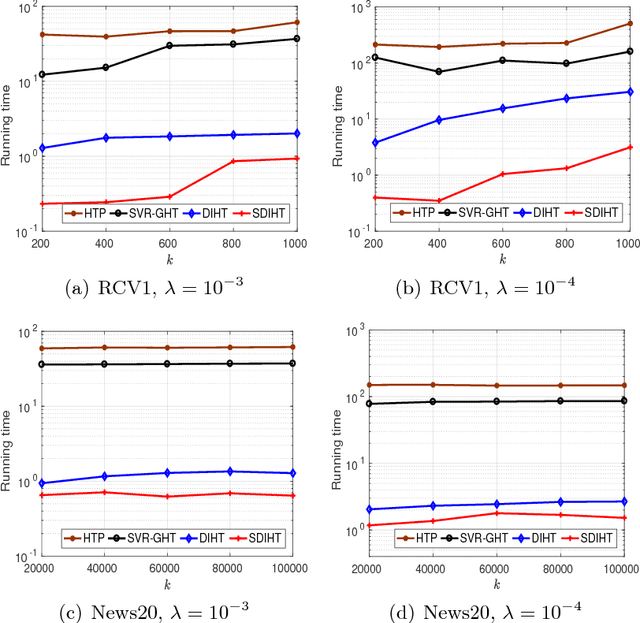
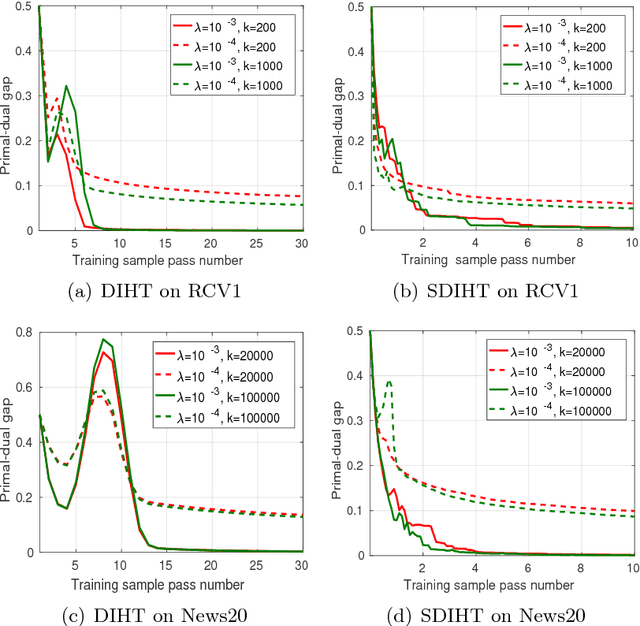
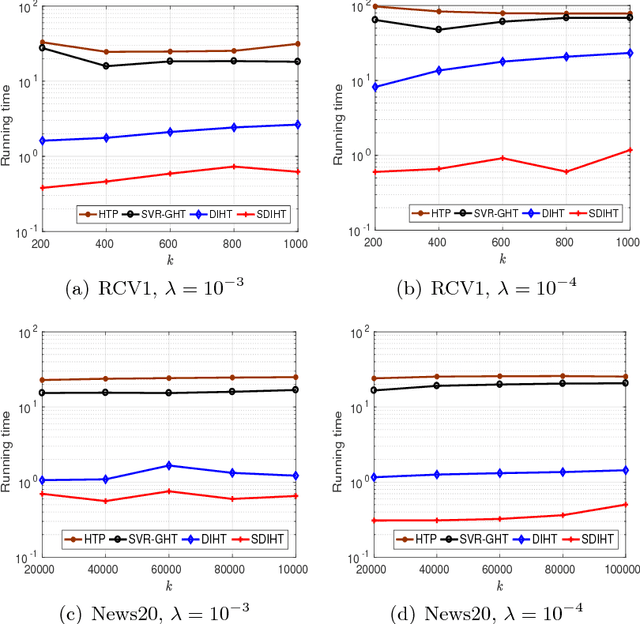
Iterative Hard Thresholding (IHT) is a class of projected gradient descent methods for optimizing sparsity-constrained minimization models, with the best known efficiency and scalability in practice. As far as we know, the existing IHT-style methods are designed for sparse minimization in primal form. It remains open to explore duality theory and algorithms in such a non-convex and NP-hard problem setting. In this paper, we bridge this gap by establishing a duality theory for sparsity-constrained minimization with $\ell_2$-regularized loss function and proposing an IHT-style algorithm for dual maximization. Our sparse duality theory provides a set of sufficient and necessary conditions under which the original NP-hard/non-convex problem can be equivalently solved in a dual formulation. The proposed dual IHT algorithm is a super-gradient method for maximizing the non-smooth dual objective. An interesting finding is that the sparse recovery performance of dual IHT is invariant to the Restricted Isometry Property (RIP), which is required by virtually all the existing primal IHT algorithms without sparsity relaxation. Moreover, a stochastic variant of dual IHT is proposed for large-scale stochastic optimization. Numerical results demonstrate the superiority of dual IHT algorithms to the state-of-the-art primal IHT-style algorithms in model estimation accuracy and computational efficiency.