 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Vocabulary 3D Object Detection
Dec 18, 2025



Open-vocabulary 3D object detection methods are able to localize 3D boxes of classes unseen during training. Despite the name, existing methods rely on user-specified classes both at training and inference. We propose to study Auto-Vocabulary 3D Object Detection (AV3DOD), where the classes are automatically generated for the detected objects without any user input. To this end, we introduce Semantic Score (SS) to evaluate the quality of the generated class names. We then develop a novel framework, AV3DOD, which leverages 2D vision-language models (VLMs) to generate rich semantic candidates through image captioning, pseudo 3D box generation, and feature-space semantics expansion. AV3DOD achieves the state-of-the-art (SOTA) performance on both localization (mAP) and semantic quality (SS) on the ScanNetV2 and SUNRGB-D datasets. Notably, it surpasses the SOTA, CoDA, by 3.48 overall mAP and attains a 24.5% relative improvement in SS on ScanNetV2.
Joint Training of Image Generator and Detector for Road Defect Detection
Sep 03, 2025

Road defect detection is important for road authorities to reduce the vehicle damage caused by road defects. Considering the practical scenarios where the defect detectors are typically deployed on edge devices with limited memory and computational resource, we aim at performing road defect detection without using ensemble-based methods or test-time augmentation (TTA). To this end, we propose to Jointly Train the image Generator and Detector for road defect detection (dubbed as JTGD). We design the dual discriminators for the generative model to enforce both the synthesized defect patches and overall images to look plausible. The synthesized image quality is improved by our proposed CLIP-based Fr\'echet Inception Distance loss. The generative model in JTGD is trained jointly with the detector to encourage the generative model to synthesize harder examples for the detector. Since harder synthesized images of better quality caused by the aforesaid design are used in the data augmentation, JTGD outperforms the state-of-the-art method in the RDD2022 road defect detection benchmark across various countries under the condition of no ensemble and TTA. JTGD only uses less than 20% of the number of parameters compared with the competing baseline, which makes it more suitable for deployment on edge devices in practice.
Toward Long-Tailed Online Anomaly Detection through Class-Agnostic Concepts
Jul 22, 2025Anomaly detection (AD) identifies the defect regions of a given image. Recent works have studied AD, focusing on learning AD without abnormal images, with long-tailed distributed training data, and using a unified model for all classes. In addition, online AD learning has also been explored. In this work, we expand in both directions to a realistic setting by considering the novel task of long-tailed online AD (LTOAD). We first identified that the offline state-of-the-art LTAD methods cannot be directly applied to the online setting. Specifically, LTAD is class-aware, requiring class labels that are not available in the online setting. To address this challenge, we propose a class-agnostic framework for LTAD and then adapt it to our online learning setting. Our method outperforms the SOTA baselines in most offline LTAD settings, including both the industrial manufacturing and the medical domain. In particular, we observe +4.63% image-AUROC on MVTec even compared to methods that have access to class labels and the number of classes. In the most challenging long-tailed online setting, we achieve +0.53% image-AUROC compared to baselines. Our LTOAD benchmark is released here: https://doi.org/10.5281/zenodo.16283852 .
Improving Open-World Object Localization by Discovering Background
Apr 24, 2025



Our work addresses the problem of learning to localize objects in an open-world setting, i.e., given the bounding box information of a limited number of object classes during training, the goal is to localize all objects, belonging to both the training and unseen classes in an image, during inference. Towards this end, recent work in this area has focused on improving the characterization of objects either explicitly by proposing new objective functions (localization quality) or implicitly using object-centric auxiliary-information, such as depth information, pixel/region affinity map etc. In this work, we address this problem by incorporating background information to guide the learning of the notion of objectness. Specifically, we propose a novel framework to discover background regions in an image and train an object proposal network to not detect any objects in these regions. We formulate the background discovery task as that of identifying image regions that are not discriminative, i.e., those that are redundant and constitute low information content. We conduct experiments on standard benchmarks to showcase the effectiveness of our proposed approach and observe significant improvements over the previous state-of-the-art approaches for this task.
PF3Det: A Prompted Foundation Feature Assisted Visual LiDAR 3D Detector
Apr 04, 2025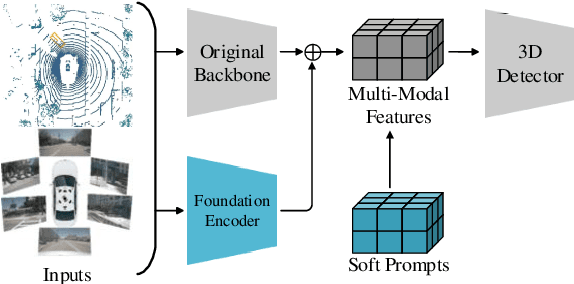
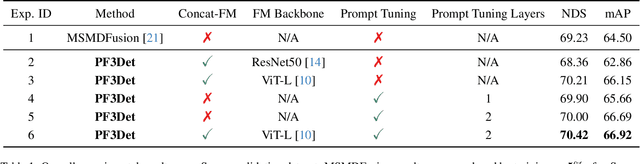
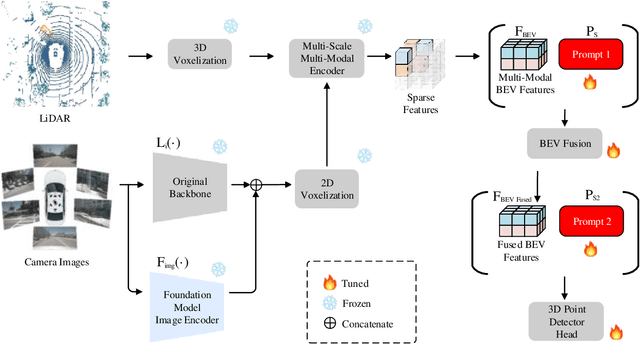

3D object detection is crucial for autonomous driving, leveraging both LiDAR point clouds for precise depth information and camera images for rich semantic information. Therefore, the multi-modal methods that combine both modalities offer more robust detection results. However, efficiently fusing LiDAR points and images remains challenging due to the domain gaps. In addition, the performance of many models is limited by the amount of high quality labeled data, which is expensive to create. The recent advances in foundation models, which use large-scale pre-training on different modalities, enable better multi-modal fusion. Combining the prompt engineering techniques for efficient training, we propose the Prompted Foundational 3D Detector (PF3Det), which integrates foundation model encoders and soft prompts to enhance LiDAR-camera feature fusion. PF3Det achieves the state-of-the-art results under limited training data, improving NDS by 1.19% and mAP by 2.42% on the nuScenes dataset, demonstrating its efficiency in 3D detection.
TailedCore: Few-Shot Sampling for Unsupervised Long-Tail Noisy Anomaly Detection
Apr 03, 2025



We aim to solve unsupervised anomaly detection in a practical challenging environment where the normal dataset is both contaminated with defective regions and its product class distribution is tailed but unknown. We observe that existing models suffer from tail-versus-noise trade-off where if a model is robust against pixel noise, then its performance deteriorates on tail class samples, and vice versa. To mitigate the issue, we handle the tail class and noise samples independently. To this end, we propose TailSampler, a novel class size predictor that estimates the class cardinality of samples based on a symmetric assumption on the class-wise distribution of embedding similarities. TailSampler can be utilized to sample the tail class samples exclusively, allowing to handle them separately. Based on these facets, we build a memory-based anomaly detection model TailedCore, whose memory both well captures tail class information and is noise-robust. We extensively validate the effectiveness of TailedCore on the unsupervised long-tail noisy anomaly detection setting, and show that TailedCore outperforms the state-of-the-art in most settings.
Towards Zero-shot 3D Anomaly Localization
Dec 05, 2024



3D anomaly detection and localization is of great significance for industrial inspection. Prior 3D anomaly detection and localization methods focus on the setting that the testing data share the same category as the training data which is normal. However, in real-world applications, the normal training data for the target 3D objects can be unavailable due to issues like data privacy or export control regulation. To tackle these challenges, we identify a new task -- zero-shot 3D anomaly detection and localization, where the training and testing classes do not overlap. To this end, we design 3DzAL, a novel patch-level contrastive learning framework based on pseudo anomalies generated using the inductive bias from task-irrelevant 3D xyz data to learn more representative feature representations. Furthermore, we train a normalcy classifier network to classify the normal patches and pseudo anomalies and utilize the classification result jointly with feature distance to design anomaly scores. Instead of directly using the patch point clouds, we introduce adversarial perturbations to the input patch xyz data before feeding into the 3D normalcy classifier for the classification-based anomaly score. We show that 3DzAL outperforms the state-of-the-art anomaly detection and localization performance.
Evaluating Large Vision-and-Language Models on Children's Mathematical Olympiads
Jun 22, 2024Recent years have seen a significant progress in the general-purpose problem solving abilities of large vision and language models (LVLMs), such as ChatGPT, Gemini, etc.; some of these breakthroughs even seem to enable AI models to outperform human abilities in varied tasks that demand higher-order cognitive skills. Are the current large AI models indeed capable of generalized problem solving as humans do? A systematic analysis of AI capabilities for joint vision and text reasoning, however, is missing in the current scientific literature. In this paper, we make an effort towards filling this gap, by evaluating state-of-the-art LVLMs on their mathematical and algorithmic reasoning abilities using visuo-linguistic problems from children's Olympiads. Specifically, we consider problems from the Mathematical Kangaroo (MK) Olympiad, which is a popular international competition targeted at children from grades 1-12, that tests children's deeper mathematical abilities using puzzles that are appropriately gauged to their age and skills. Using the puzzles from MK, we created a dataset, dubbed SMART-840, consisting of 840 problems from years 2020-2024. With our dataset, we analyze LVLMs power on mathematical reasoning; their responses on our puzzles offer a direct way to compare against that of children. Our results show that modern LVLMs do demonstrate increasingly powerful reasoning skills in solving problems for higher grades, but lack the foundations to correctly answer problems designed for younger children. Further analysis shows that there is no significant correlation between the reasoning capabilities of AI models and that of young children, and their capabilities appear to be based on a different type of reasoning than the cumulative knowledge that underlies children's mathematics and logic skills.
Multimodal 3D Object Detection on Unseen Domains
Apr 17, 2024LiDAR datasets for autonomous driving exhibit biases in properties such as point cloud density, range, and object dimensions. As a result, object detection networks trained and evaluated in different environments often experience performance degradation. Domain adaptation approaches assume access to unannotated samples from the test distribution to address this problem. However, in the real world, the exact conditions of deployment and access to samples representative of the test dataset may be unavailable while training. We argue that the more realistic and challenging formulation is to require robustness in performance to unseen target domains. We propose to address this problem in a two-pronged manner. First, we leverage paired LiDAR-image data present in most autonomous driving datasets to perform multimodal object detection. We suggest that working with multimodal features by leveraging both images and LiDAR point clouds for scene understanding tasks results in object detectors more robust to unseen domain shifts. Second, we train a 3D object detector to learn multimodal object features across different distributions and promote feature invariance across these source domains to improve generalizability to unseen target domains. To this end, we propose CLIX$^\text{3D}$, a multimodal fusion and supervised contrastive learning framework for 3D object detection that performs alignment of object features from same-class samples of different domains while pushing the features from different classes apart. We show that CLIX$^\text{3D}$ yields state-of-the-art domain generalization performance under multiple dataset shifts.
Equivariant Spatio-Temporal Self-Supervision for LiDAR Object Detection
Apr 17, 2024



Popular representation learning methods encourage feature invariance under transformations applied at the input. However, in 3D perception tasks like object localization and segmentation, outputs are naturally equivariant to some transformations, such as rotation. Using pre-training loss functions that encourage equivariance of features under certain transformations provides a strong self-supervision signal while also retaining information of geometric relationships between transformed feature representations. This can enable improved performance in downstream tasks that are equivariant to such transformations. In this paper, we propose a spatio-temporal equivariant learning framework by considering both spatial and temporal augmentations jointly. Our experiments show that the best performance arises with a pre-training approach that encourages equivariance to translation, scaling, and flip, rotation and scene flow. For spatial augmentations, we find that depending on the transformation, either a contrastive objective or an equivariance-by-classification objective yields best results. To leverage real-world object deformations and motion, we consider sequential LiDAR scene pairs and develop a novel 3D scene flow-based equivariance objective that leads to improved performance overall. We show our pre-training method for 3D object detection which outperforms existing equivariant and invariant approaches in many settings.