 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Tailed Anomaly Detection with Learnable Class Names
Mar 29, 2024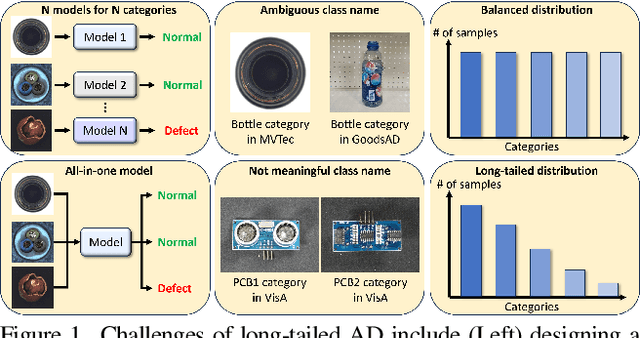
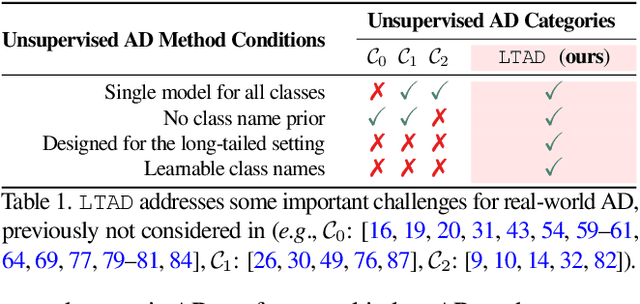
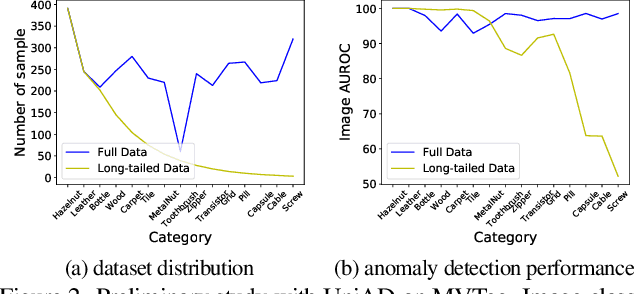

Anomaly detection (AD) aims to identify defective images and localize their defects (if any). Ideally, AD models should be able to detect defects over many image classes; without relying on hard-coded class names that can be uninformative or inconsistent across datasets; learn without anomaly supervision; and be robust to the long-tailed distributions of real-world applications. To address these challenges, we formulate the problem of long-tailed AD by introducing several datasets with different levels of class imbalance and metrics for performance evaluation. We then propose a novel method, LTAD, to detect defects from multiple and long-tailed classes, without relying on dataset class names. LTAD combines AD by reconstruction and semantic AD modules. AD by reconstruction is implemented with a transformer-based reconstruction module. Semantic AD is implemented with a binary classifier, which relies on learned pseudo class names and a pretrained foundation model. These modules are learned over two phases. Phase 1 learns the pseudo-class names and a variational autoencoder (VAE) for feature synthesis that augments the training data to combat long-tails. Phase 2 then learns the parameters of the reconstruction and classification modules of LTAD. Extensive experiments using the proposed long-tailed datasets show that LTAD substantially outperforms the state-of-the-art methods for most forms of dataset imbalance. The long-tailed dataset split is available at https://zenodo.org/records/10854201 .
ProTeCt: Prompt Tuning for Hierarchical Consistency
Jun 04, 2023Large visual-language models, like CLIP, learn generalized representations and have shown promising zero-shot performance. Few-shot adaptation methods, based on prompt tuning, have also been shown to further improve performance on downstream datasets. However, these models are not hierarchically consistent. Frequently, they infer incorrect labels at coarser taxonomic class levels, even when the inference at the leaf level (original class labels) is correct. This is problematic, given their support for open set classification and, in particular, open-grained classification, where practitioners define label sets at various levels of granularity. To address this problem, we propose a prompt tuning technique to calibrate the hierarchical consistency of model predictions. A set of metrics of hierarchical consistency, the Hierarchical Consistent Accuracy (HCA) and the Mean Treecut Accuracy (MTA), are first proposed to benchmark model performance in the open-granularity setting. A prompt tuning technique, denoted as Prompt Tuning for Hierarchical Consistency (ProTeCt), is then proposed to calibrate classification across all possible label set granularities. Results show that ProTeCt can be combined with existing prompt tuning methods to significantly improve open-granularity classification performance without degradation of the original classification performance at the leaf level.
Toward Unsupervised Realistic Visual Question Answering
Mar 09, 2023



The problem of realistic VQA (RVQA), where a model has to reject unanswerable questions (UQs) and answer answerable ones (AQs), is studied. We first point out 2 drawbacks in current RVQA research, where (1) datasets contain too many unchallenging UQs and (2) a large number of annotated UQs are required for training. To resolve the first drawback, we propose a new testing dataset, RGQA, which combines AQs from an existing VQA dataset with around 29K human-annotated UQs. These UQs consist of both fine-grained and coarse-grained image-question pairs generated with 2 approaches: CLIP-based and Perturbation-based. To address the second drawback, we introduce an unsupervised training approach. This combines pseudo UQs obtained by randomly pairing images and questions, with an RoI Mixup procedure to generate more fine-grained pseudo UQs, and model ensembling to regularize model confidence. Experiments show that using pseudo UQs significantly outperforms RVQA baselines. RoI Mixup and model ensembling further increase the gain. Finally, human evaluation reveals a performance gap between humans and models, showing that more RVQA research is needed.
DISCO: Adversarial Defense with Local Implicit Functions
Dec 11, 2022

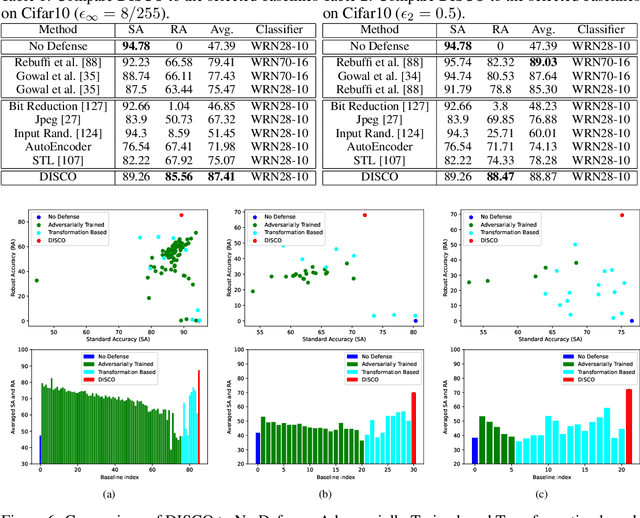
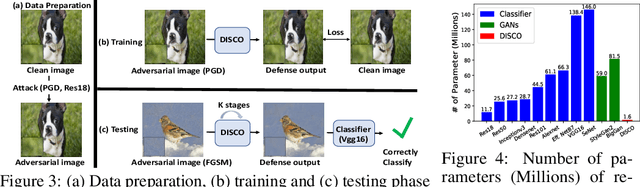
The problem of adversarial defenses for image classification, where the goal is to robustify a classifier against adversarial examples, is considered. Inspired by the hypothesis that these examples lie beyond the natural image manifold, a novel aDversarIal defenSe with local impliCit functiOns (DISCO) is proposed to remove adversarial perturbations by localized manifold projections. DISCO consumes an adversarial image and a query pixel location and outputs a clean RGB value at the location. It is implemented with an encoder and a local implicit module, where the former produces per-pixel deep features and the latter uses the features in the neighborhood of query pixel for predicting the clean RGB value. Extensive experiments demonstrate that both DISCO and its cascade version outperform prior defenses, regardless of whether the defense is known to the attacker. DISCO is also shown to be data and parameter efficient and to mount defenses that transfers across datasets, classifiers and attacks.
YORO -- Lightweight End to End Visual Grounding
Nov 15, 2022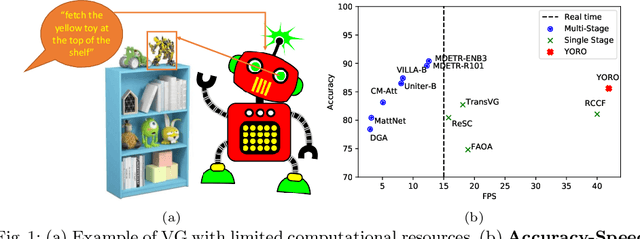
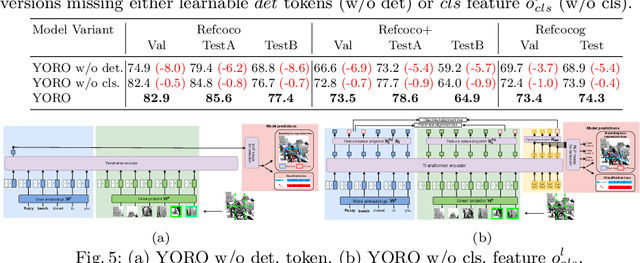
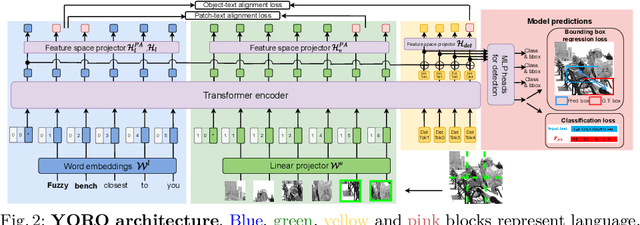

We present YORO - a multi-modal transformer encoder-only architecture for the Visual Grounding (VG) task. This task involves localizing, in an image, an object referred via natural language. Unlike the recent trend in the literature of using multi-stage approaches that sacrifice speed for accuracy, YORO seeks a better trade-off between speed an accuracy by embracing a single-stage design, without CNN backbone. YORO consumes natural language queries, image patches, and learnable detection tokens and predicts coordinates of the referred object, using a single transformer encoder. To assist the alignment between text and visual objects, a novel patch-text alignment loss is proposed. Extensive experiments are conducted on 5 different datasets with ablations on architecture design choices. YORO is shown to support real-time inference and outperform all approaches in this class (single-stage methods) by large margins. It is also the fastest VG model and achieves the best speed/accuracy trade-off in the literature.
Modeling Flash Memory Channels Using Conditional Generative Nets
Nov 19, 2021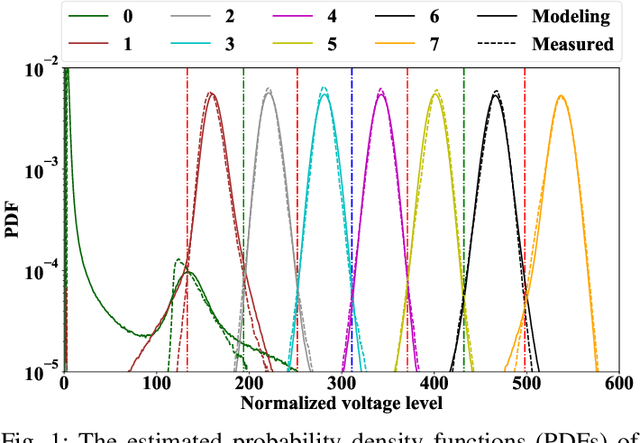
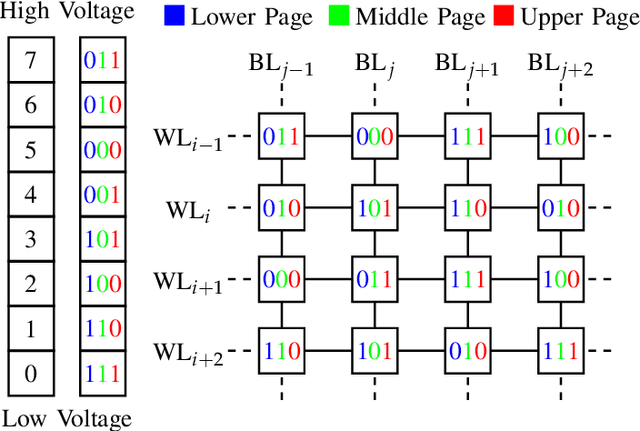
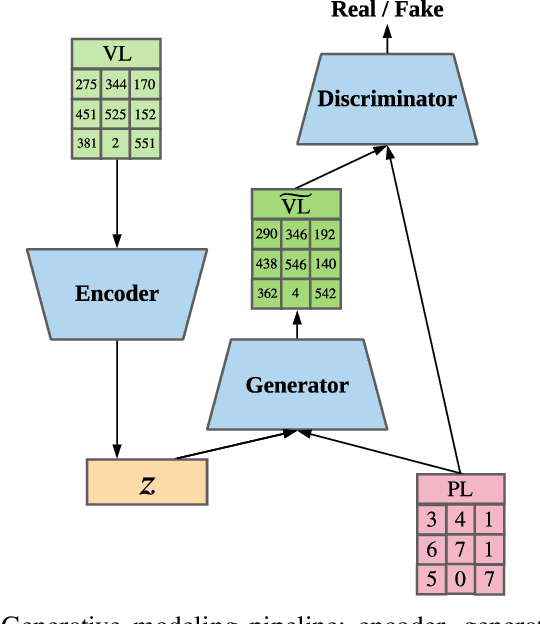
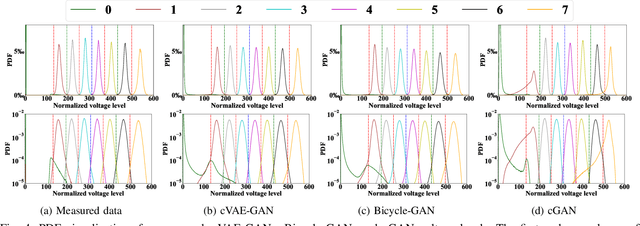
Understanding the NAND flash memory channel has become more and more challenging due to the continually increasing density and the complex distortions arising from the write and read mechanisms. In this work, we propose a data-driven generative modeling method to characterize the flash memory channel. The learned model can reconstruct the read voltage from an individual memory cell based on the program levels of the cell and its surrounding array of cells. Experimental results show that the statistical distribution of the reconstructed read voltages accurately reflects the measured distribution on a commercial flash memory chip, both qualitatively and as quantified by the total variation distance. Moreover, we observe that the learned model can capture precise inter-cell interference (ICI) effects, as verified by comparison of the error probabilities of specific patterns in wordlines and bitlines.
OOWL500: Overcoming Dataset Collection Bias in the Wild
Aug 24, 2021
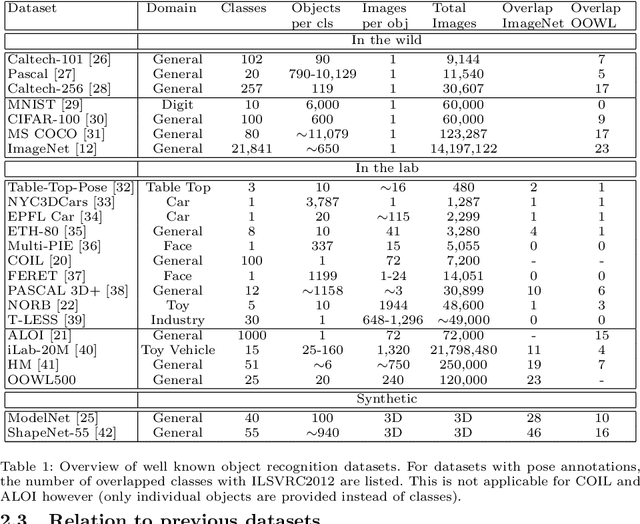

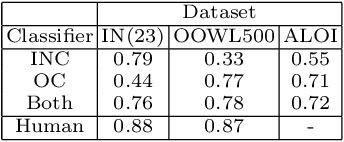
The hypothesis that image datasets gathered online "in the wild" can produce biased object recognizers, e.g. preferring professional photography or certain viewing angles, is studied. A new "in the lab" data collection infrastructure is proposed consisting of a drone which captures images as it circles around objects. Crucially, the control provided by this setup and the natural camera shake inherent to flight mitigate many biases. It's inexpensive and easily replicable nature may also potentially lead to a scalable data collection effort by the vision community. The procedure's usefulness is demonstrated by creating a dataset of Objects Obtained With fLight (OOWL). Denoted as OOWL500, it contains 120,000 images of 500 objects and is the largest "in the lab" image dataset available when both number of classes and objects per class are considered. Furthermore, it has enabled several of new insights on object recognition. First, a novel adversarial attack strategy is proposed, where image perturbations are defined in terms of semantic properties such as camera shake and pose. Indeed, experiments have shown that ImageNet has considerable amounts of pose and professional photography bias. Second, it is used to show that the augmentation of in the wild datasets, such as ImageNet, with in the lab data, such as OOWL500, can significantly decrease these biases, leading to object recognizers of improved generalization. Third, the dataset is used to study questions on "best procedures" for dataset collection. It is revealed that data augmentation with synthetic images does not suffice to eliminate in the wild datasets biases, and that camera shake and pose diversity play a more important role in object recognition robustness than previously thought.
Black-Box Test-Time Shape REFINEment for Single View 3D Reconstruction
Aug 23, 2021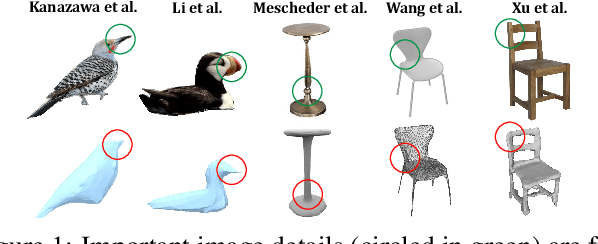
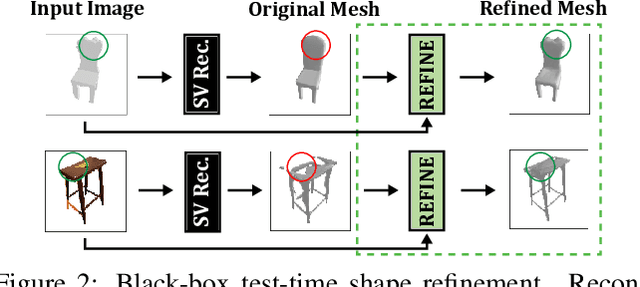
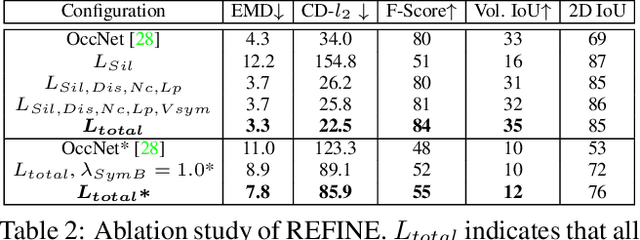
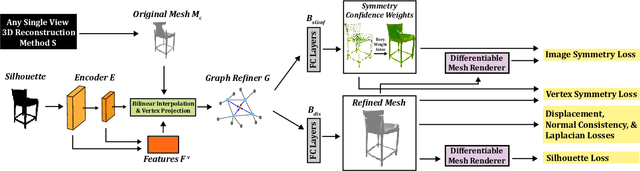
Much recent progress has been made in reconstructing the 3D shape of an object from an image of it, i.e. single view 3D reconstruction. However, it has been suggested that current methods simply adopt a "nearest-neighbor" strategy, instead of genuinely understanding the shape behind the input image. In this paper, we rigorously show that for many state of the art methods, this issue manifests as (1) inconsistencies between coarse reconstructions and input images, and (2) inability to generalize across domains. We thus propose REFINE, a postprocessing mesh refinement step that can be easily integrated into the pipeline of any black-box method in the literature. At test time, REFINE optimizes a network per mesh instance, to encourage consistency between the mesh and the given object view. This, along with a novel combination of regularizing losses, reduces the domain gap and achieves state of the art performance. We believe that this novel paradigm is an important step towards robust, accurate reconstructions, remaining relevant as new reconstruction networks are introduced.
Contrastive Learning with Adversarial Examples
Oct 22, 2020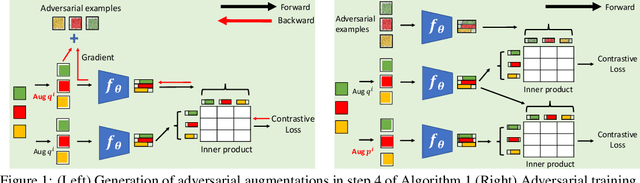

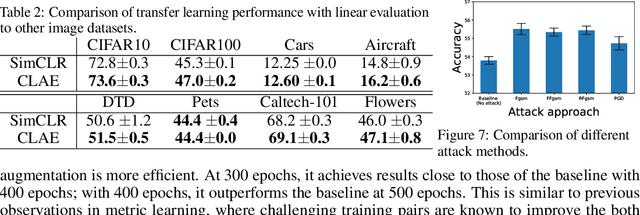
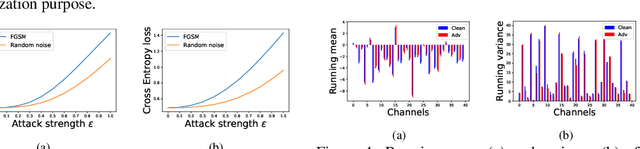
Contrastive learning (CL) is a popular technique for self-supervised learning (SSL) of visual representations. It uses pairs of augmentations of unlabeled training examples to define a classification task for pretext learning of a deep embedding. Despite extensive works in augmentation procedures, prior works do not address the selection of challenging negative pairs, as images within a sampled batch are treated independently. This paper addresses the problem, by introducing a new family of adversarial examples for constrastive learning and using these examples to define a new adversarial training algorithm for SSL, denoted as CLAE. When compared to standard CL, the use of adversarial examples creates more challenging positive pairs and adversarial training produces harder negative pairs by accounting for all images in a batch during the optimization. CLAE is compatible with many CL methods in the literature. Experiments show that it improves the performance of several existing CL baselines on multiple datasets.
Solving Long-tailed Recognition with Deep Realistic Taxonomic Classifier
Jul 20, 2020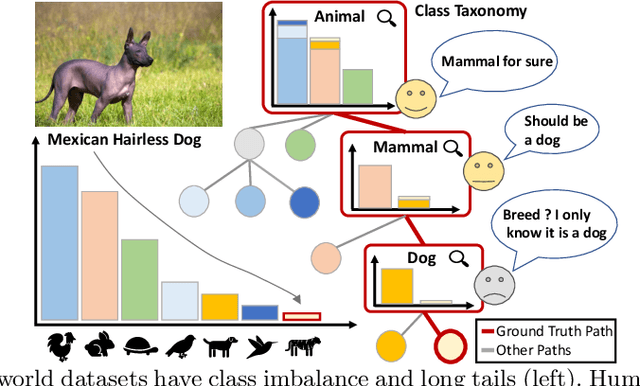
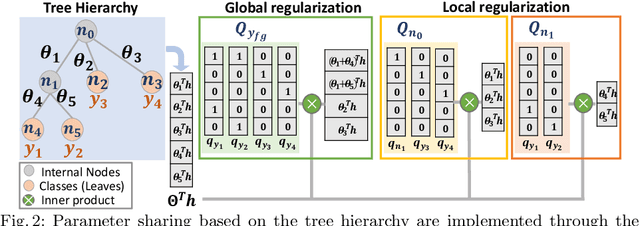
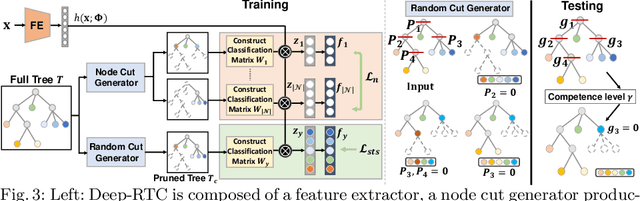
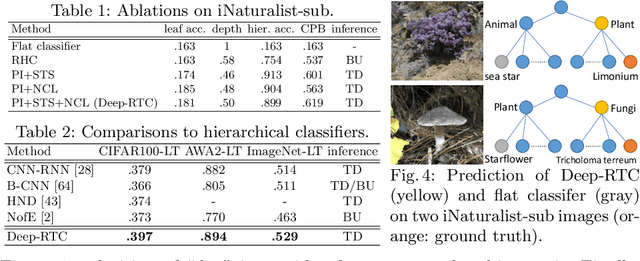
Long-tail recognition tackles the natural non-uniformly distributed data in real-world scenarios. While modern classifiers perform well on populated classes, its performance degrades significantly on tail classes. Humans, however, are less affected by this since, when confronted with uncertain examples, they simply opt to provide coarser predictions. Motivated by this, a deep realistic taxonomic classifier (Deep-RTC) is proposed as a new solution to the long-tail problem, combining realism with hierarchical predictions. The model has the option to reject classifying samples at different levels of the taxonomy, once it cannot guarantee the desired performance. Deep-RTC is implemented with a stochastic tree sampling during training to simulate all possible classification conditions at finer or coarser levels and a rejection mechanism at inference time. Experiments on the long-tailed version of four datasets, CIFAR100, AWA2, Imagenet, and iNaturalist, demonstrate that the proposed approach preserves more information on all classes with different popularity levels. Deep-RTC also outperforms the state-of-the-art methods in longtailed recognition, hierarchical classification, and learning with rejection literature using the proposed correctly predicted bits (CPB) metric.