 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOOWL500: Overcoming Dataset Collection Bias in the Wild
Aug 24, 2021
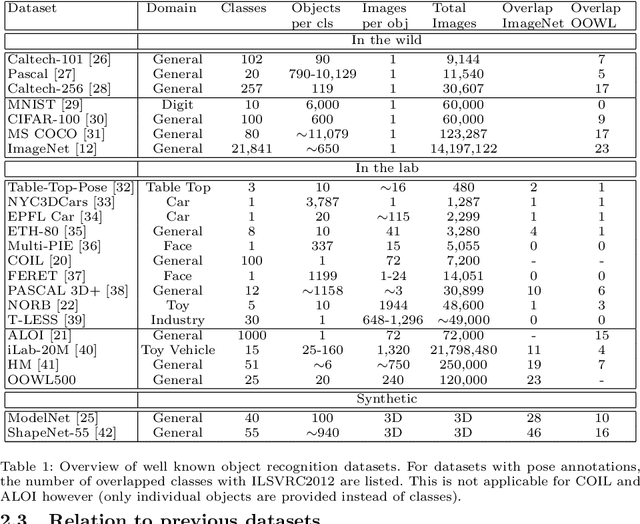

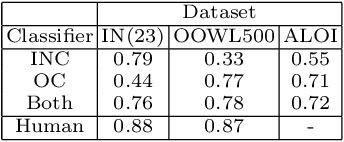
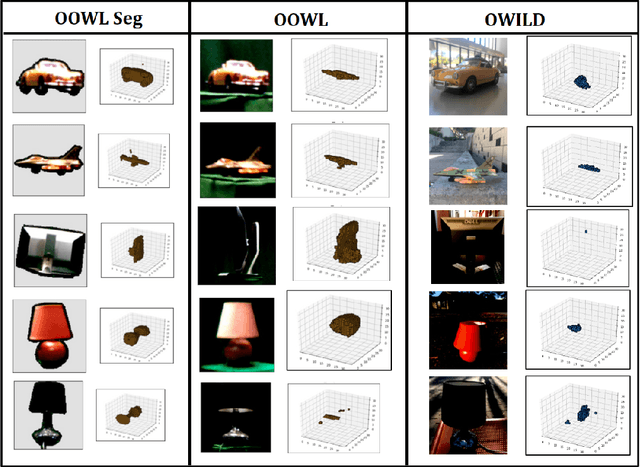
The hypothesis that image datasets gathered online "in the wild" can produce biased object recognizers, e.g. preferring professional photography or certain viewing angles, is studied. A new "in the lab" data collection infrastructure is proposed consisting of a drone which captures images as it circles around objects. Crucially, the control provided by this setup and the natural camera shake inherent to flight mitigate many biases. It's inexpensive and easily replicable nature may also potentially lead to a scalable data collection effort by the vision community. The procedure's usefulness is demonstrated by creating a dataset of Objects Obtained With fLight (OOWL). Denoted as OOWL500, it contains 120,000 images of 500 objects and is the largest "in the lab" image dataset available when both number of classes and objects per class are considered. Furthermore, it has enabled several of new insights on object recognition. First, a novel adversarial attack strategy is proposed, where image perturbations are defined in terms of semantic properties such as camera shake and pose. Indeed, experiments have shown that ImageNet has considerable amounts of pose and professional photography bias. Second, it is used to show that the augmentation of in the wild datasets, such as ImageNet, with in the lab data, such as OOWL500, can significantly decrease these biases, leading to object recognizers of improved generalization. Third, the dataset is used to study questions on "best procedures" for dataset collection. It is revealed that data augmentation with synthetic images does not suffice to eliminate in the wild datasets biases, and that camera shake and pose diversity play a more important role in object recognition robustness than previously thought.
Domain Adaptation for Real-World Single View 3D Reconstruction
Aug 24, 2021
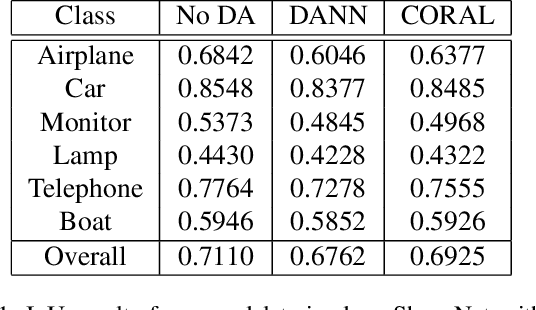
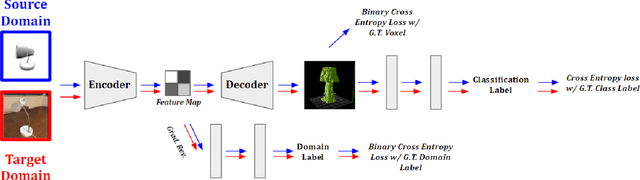
Deep learning-based object reconstruction algorithms have shown remarkable improvements over classical methods. However, supervised learning based methods perform poorly when the training data and the test data have different distributions. Indeed, most current works perform satisfactorily on the synthetic ShapeNet dataset, but dramatically fail in when presented with real world images. To address this issue, unsupervised domain adaptation can be used transfer knowledge from the labeled synthetic source domain and learn a classifier for the unlabeled real target domain. To tackle this challenge of single view 3D reconstruction in the real domain, we experiment with a variety of domain adaptation techniques inspired by the maximum mean discrepancy (MMD) loss, Deep CORAL, and the domain adversarial neural network (DANN). From these findings, we additionally propose a novel architecture which takes advantage of the fact that in this setting, target domain data is unsupervised with regards to the 3D model but supervised for class labels. We base our framework off a recent network called pix2vox. Results are performed with ShapeNet as the source domain and domains within the Object Dataset Domain Suite (ODDS) dataset as the target, which is a real world multiview, multidomain image dataset. The domains in ODDS vary in difficulty, allowing us to assess notions of domain gap size. Our results are the first in the multiview reconstruction literature using this dataset.
Black-Box Test-Time Shape REFINEment for Single View 3D Reconstruction
Aug 23, 2021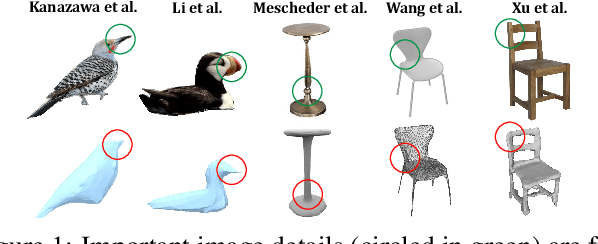
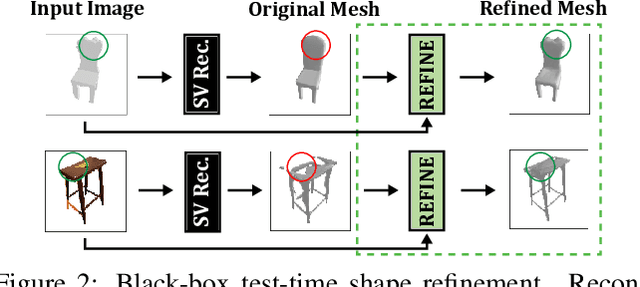
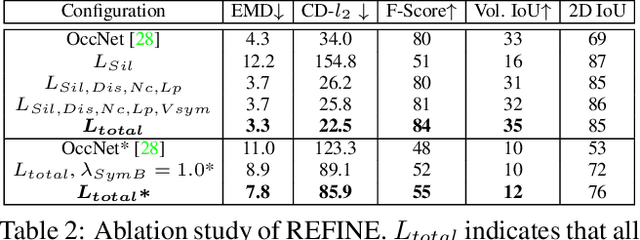
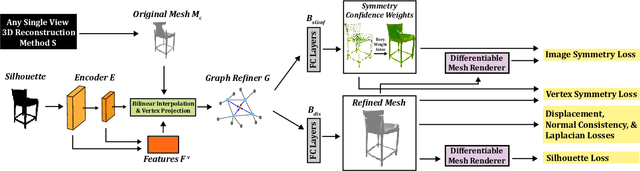
Much recent progress has been made in reconstructing the 3D shape of an object from an image of it, i.e. single view 3D reconstruction. However, it has been suggested that current methods simply adopt a "nearest-neighbor" strategy, instead of genuinely understanding the shape behind the input image. In this paper, we rigorously show that for many state of the art methods, this issue manifests as (1) inconsistencies between coarse reconstructions and input images, and (2) inability to generalize across domains. We thus propose REFINE, a postprocessing mesh refinement step that can be easily integrated into the pipeline of any black-box method in the literature. At test time, REFINE optimizes a network per mesh instance, to encourage consistency between the mesh and the given object view. This, along with a novel combination of regularizing losses, reduces the domain gap and achieves state of the art performance. We believe that this novel paradigm is an important step towards robust, accurate reconstructions, remaining relevant as new reconstruction networks are introduced.