 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-Box Test-Time Shape REFINEment for Single View 3D Reconstruction
Paper and Code
Aug 23, 2021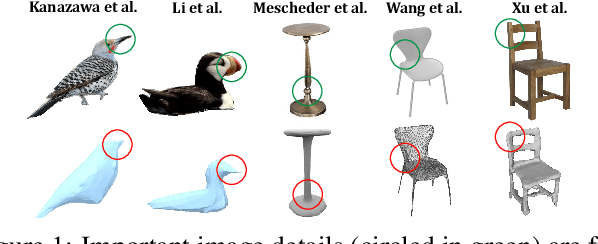
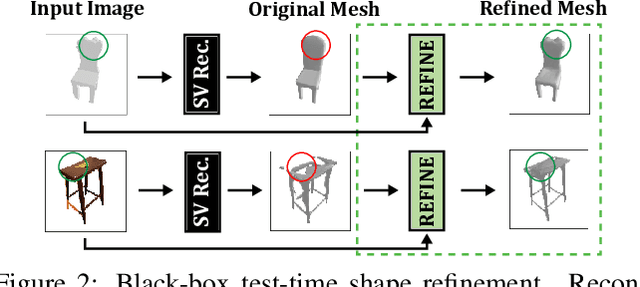
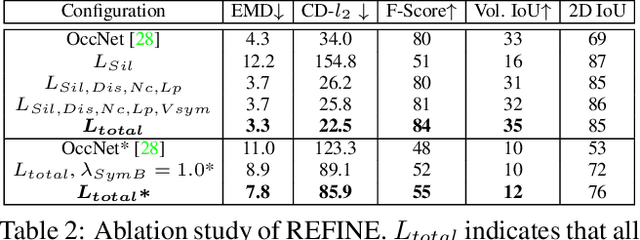
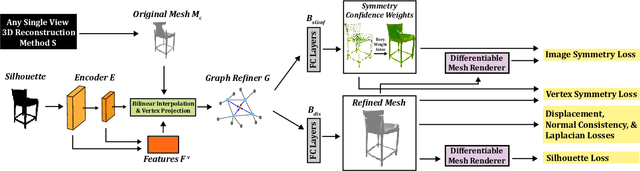
Much recent progress has been made in reconstructing the 3D shape of an object from an image of it, i.e. single view 3D reconstruction. However, it has been suggested that current methods simply adopt a "nearest-neighbor" strategy, instead of genuinely understanding the shape behind the input image. In this paper, we rigorously show that for many state of the art methods, this issue manifests as (1) inconsistencies between coarse reconstructions and input images, and (2) inability to generalize across domains. We thus propose REFINE, a postprocessing mesh refinement step that can be easily integrated into the pipeline of any black-box method in the literature. At test time, REFINE optimizes a network per mesh instance, to encourage consistency between the mesh and the given object view. This, along with a novel combination of regularizing losses, reduces the domain gap and achieves state of the art performance. We believe that this novel paradigm is an important step towards robust, accurate reconstructions, remaining relevant as new reconstruction networks are introduced.