 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOOWL500: Overcoming Dataset Collection Bias in the Wild
Aug 24, 2021
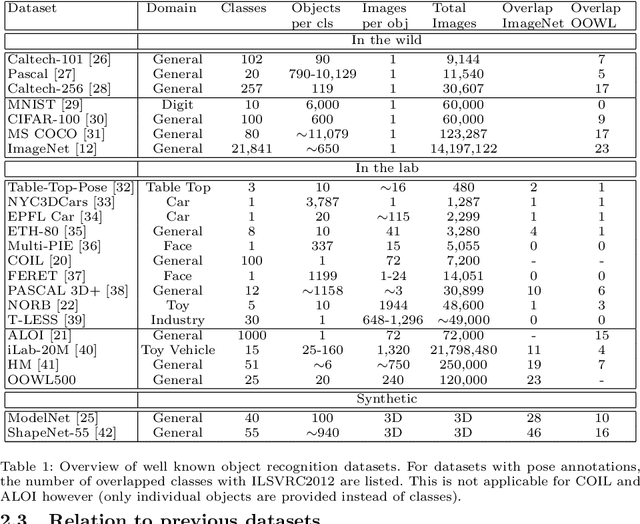

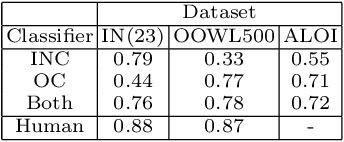
The hypothesis that image datasets gathered online "in the wild" can produce biased object recognizers, e.g. preferring professional photography or certain viewing angles, is studied. A new "in the lab" data collection infrastructure is proposed consisting of a drone which captures images as it circles around objects. Crucially, the control provided by this setup and the natural camera shake inherent to flight mitigate many biases. It's inexpensive and easily replicable nature may also potentially lead to a scalable data collection effort by the vision community. The procedure's usefulness is demonstrated by creating a dataset of Objects Obtained With fLight (OOWL). Denoted as OOWL500, it contains 120,000 images of 500 objects and is the largest "in the lab" image dataset available when both number of classes and objects per class are considered. Furthermore, it has enabled several of new insights on object recognition. First, a novel adversarial attack strategy is proposed, where image perturbations are defined in terms of semantic properties such as camera shake and pose. Indeed, experiments have shown that ImageNet has considerable amounts of pose and professional photography bias. Second, it is used to show that the augmentation of in the wild datasets, such as ImageNet, with in the lab data, such as OOWL500, can significantly decrease these biases, leading to object recognizers of improved generalization. Third, the dataset is used to study questions on "best procedures" for dataset collection. It is revealed that data augmentation with synthetic images does not suffice to eliminate in the wild datasets biases, and that camera shake and pose diversity play a more important role in object recognition robustness than previously thought.
A Real-Time Online Learning Framework for Joint 3D Reconstruction and Semantic Segmentation of Indoor Scenes
Aug 11, 2021



This paper presents a real-time online vision framework to jointly recover an indoor scene's 3D structure and semantic label. Given noisy depth maps, a camera trajectory, and 2D semantic labels at train time, the proposed neural network learns to fuse the depth over frames with suitable semantic labels in the scene space. Our approach exploits the joint volumetric representation of the depth and semantics in the scene feature space to solve this task. For a compelling online fusion of the semantic labels and geometry in real-time, we introduce an efficient vortex pooling block while dropping the routing network in online depth fusion to preserve high-frequency surface details. We show that the context information provided by the semantics of the scene helps the depth fusion network learn noise-resistant features. Not only that, it helps overcome the shortcomings of the current online depth fusion method in dealing with thin object structures, thickening artifacts, and false surfaces. Experimental evaluation on the Replica dataset shows that our approach can perform depth fusion at 37, 10 frames per second with an average reconstruction F-score of 88%, and 91%, respectively, depending on the depth map resolution. Moreover, our model shows an average IoU score of 0.515 on the ScanNet 3D semantic benchmark leaderboard.