 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesize Step-by-Step: Tools, Templates and LLMs as Data Generators for Reasoning-Based Chart VQA
Mar 28, 2024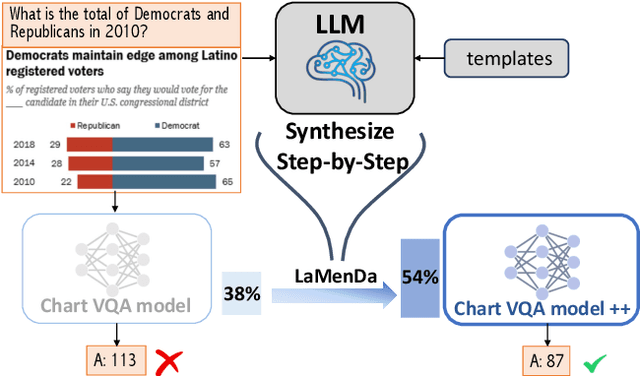
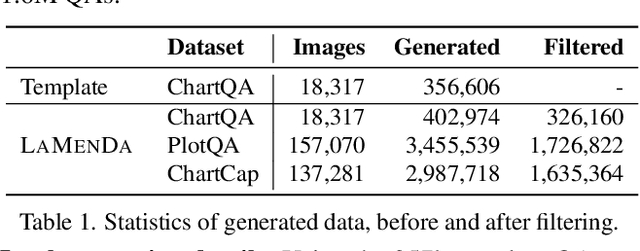
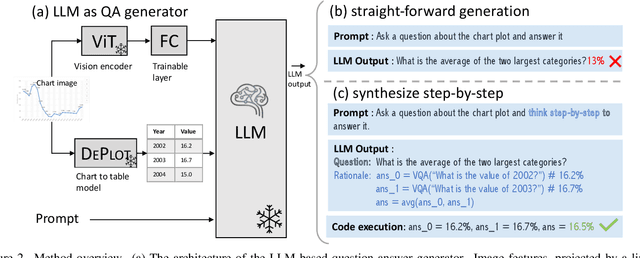
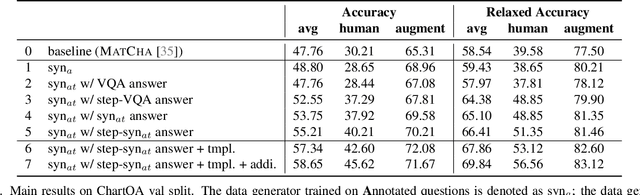
Understanding data visualizations like charts and plots requires reasoning about both visual elements and numerics. Although strong in extractive questions, current chart visual question answering (chart VQA) models suffer on complex reasoning questions. In this work, we address the lack of reasoning ability by data augmentation. We leverage Large Language Models (LLMs), which have shown to have strong reasoning ability, as an automatic data annotator that generates question-answer annotations for chart images. The key innovation in our method lies in the Synthesize Step-by-Step strategy: our LLM-based data generator learns to decompose the complex question into step-by-step sub-questions (rationales), which are then used to derive the final answer using external tools, i.e. Python. This step-wise generation procedure is trained on synthetic data generated using a template-based QA generation pipeline. Experimental results highlight the significance of the proposed step-by-step generation. By training with the LLM-augmented data (LAMENDA), we significantly enhance the chart VQA models, achieving the state-of-the-art accuracy on the ChartQA and PlotQA datasets. In particular, our approach improves the accuracy of the previous state-of-the-art approach from 38% to 54% on the human-written questions in the ChartQA dataset, which needs strong reasoning. We hope our work underscores the potential of synthetic data and encourages further exploration of data augmentation using LLMs for reasoning-heavy tasks.
YORO -- Lightweight End to End Visual Grounding
Nov 15, 2022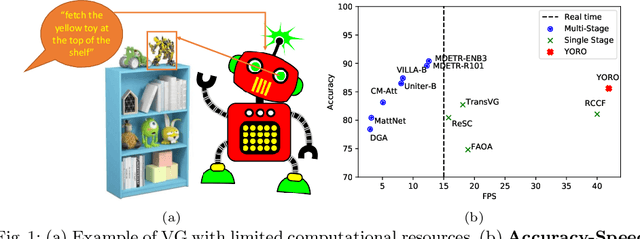
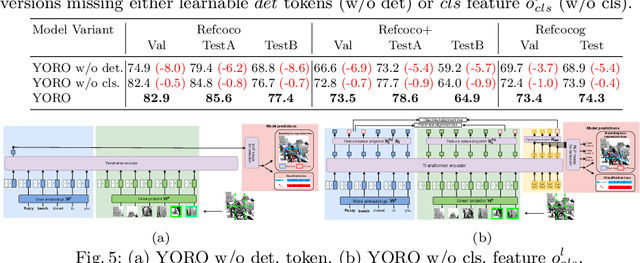
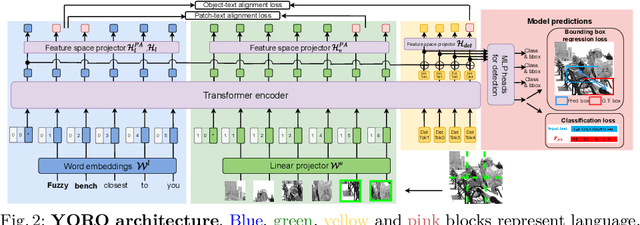

We present YORO - a multi-modal transformer encoder-only architecture for the Visual Grounding (VG) task. This task involves localizing, in an image, an object referred via natural language. Unlike the recent trend in the literature of using multi-stage approaches that sacrifice speed for accuracy, YORO seeks a better trade-off between speed an accuracy by embracing a single-stage design, without CNN backbone. YORO consumes natural language queries, image patches, and learnable detection tokens and predicts coordinates of the referred object, using a single transformer encoder. To assist the alignment between text and visual objects, a novel patch-text alignment loss is proposed. Extensive experiments are conducted on 5 different datasets with ablations on architecture design choices. YORO is shown to support real-time inference and outperform all approaches in this class (single-stage methods) by large margins. It is also the fastest VG model and achieves the best speed/accuracy trade-off in the literature.
DocFormer: End-to-End Transformer for Document Understanding
Jun 22, 2021We present DocFormer -- a multi-modal transformer based architecture for the task of Visual Document Understanding (VDU). VDU is a challenging problem which aims to understand documents in their varied formats (forms, receipts etc.) and layouts. In addition, DocFormer is pre-trained in an unsupervised fashion using carefully designed tasks which encourage multi-modal interaction. DocFormer uses text, vision and spatial features and combines them using a novel multi-modal self-attention layer. DocFormer also shares learned spatial embeddings across modalities which makes it easy for the model to correlate text to visual tokens and vice versa. DocFormer is evaluated on 4 different datasets each with strong baselines. DocFormer achieves state-of-the-art results on all of them, sometimes beating models 4x its size (in no. of parameters).
Skeleton based Zero Shot Action Recognition in Joint Pose-Language Semantic Space
Nov 26, 2019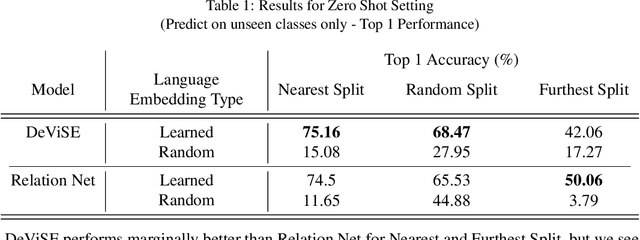
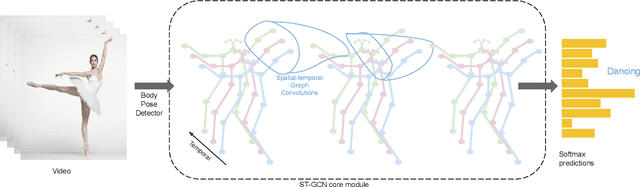
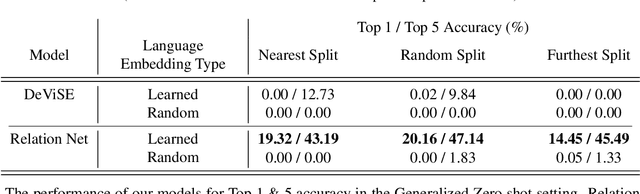
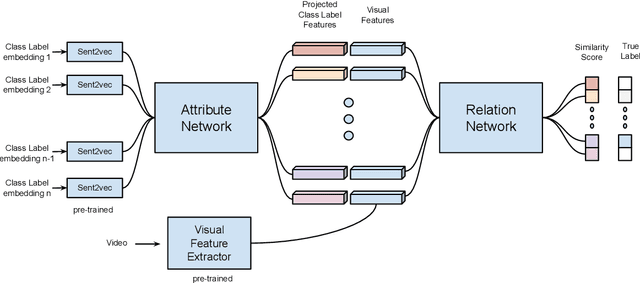
How does one represent an action? How does one describe an action that we have never seen before? Such questions are addressed by the Zero Shot Learning paradigm, where a model is trained on only a subset of classes and is evaluated on its ability to correctly classify an example from a class it has never seen before. In this work, we present a body pose based zero shot action recognition network and demonstrate its performance on the NTU RGB-D dataset. Our model learns to jointly encapsulate visual similarities based on pose features of the action performer as well as similarities in the natural language descriptions of the unseen action class names. We demonstrate how this pose-language semantic space encodes knowledge which allows our model to correctly predict actions not seen during training.
Are we asking the right questions in MovieQA?
Nov 08, 2019
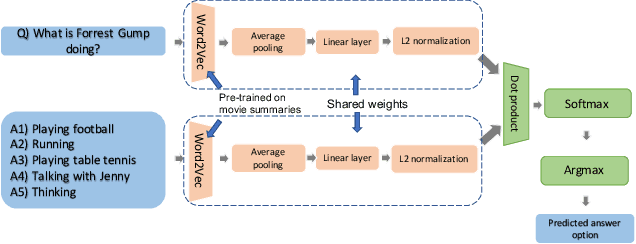

Joint vision and language tasks like visual question answering are fascinating because they explore high-level understanding, but at the same time, can be more prone to language biases. In this paper, we explore the biases in the MovieQA dataset and propose a strikingly simple model which can exploit them. We find that using the right word embedding is of utmost importance. By using an appropriately trained word embedding, about half the Question-Answers (QAs) can be answered by looking at the questions and answers alone, completely ignoring narrative context from video clips, subtitles, and movie scripts. Compared to the best published papers on the leaderboard, our simple question + answer only model improves accuracy by 5% for video + subtitle category, 5% for subtitle, 15% for DVS and 6% higher for scripts.
Learning Sampling Policies for Domain Adaptation
May 19, 2018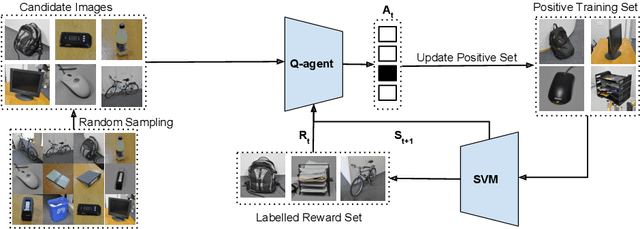

We address the problem of semi-supervised domain adaptation of classification algorithms through deep Q-learning. The core idea is to consider the predictions of a source domain network on target domain data as noisy labels, and learn a policy to sample from this data so as to maximize classification accuracy on a small annotated reward partition of the target domain. Our experiments show that learned sampling policies construct labeled sets that improve accuracies of visual classifiers over baselines.