Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Sampling Policies for Domain Adaptation
Paper and Code
May 19, 2018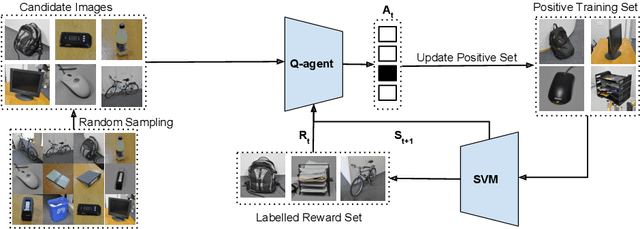

We address the problem of semi-supervised domain adaptation of classification algorithms through deep Q-learning. The core idea is to consider the predictions of a source domain network on target domain data as noisy labels, and learn a policy to sample from this data so as to maximize classification accuracy on a small annotated reward partition of the target domain. Our experiments show that learned sampling policies construct labeled sets that improve accuracies of visual classifiers over baselines.
View paper on