 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocFormer: End-to-End Transformer for Document Understanding
Jun 22, 2021We present DocFormer -- a multi-modal transformer based architecture for the task of Visual Document Understanding (VDU). VDU is a challenging problem which aims to understand documents in their varied formats (forms, receipts etc.) and layouts. In addition, DocFormer is pre-trained in an unsupervised fashion using carefully designed tasks which encourage multi-modal interaction. DocFormer uses text, vision and spatial features and combines them using a novel multi-modal self-attention layer. DocFormer also shares learned spatial embeddings across modalities which makes it easy for the model to correlate text to visual tokens and vice versa. DocFormer is evaluated on 4 different datasets each with strong baselines. DocFormer achieves state-of-the-art results on all of them, sometimes beating models 4x its size (in no. of parameters).
Maximum Entropy Binary Encoding for Face Template Protection
Dec 05, 2015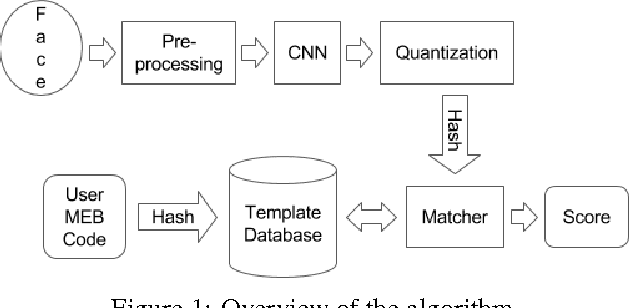
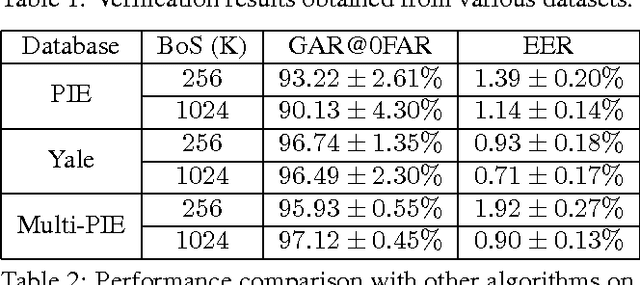
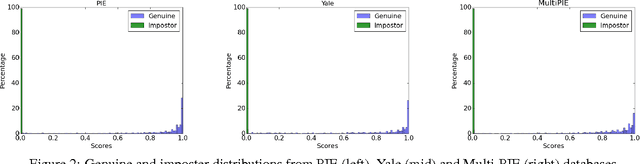
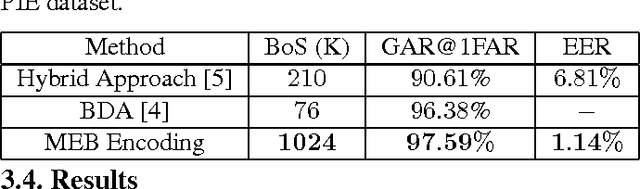
In this paper we present a framework for secure identification using deep neural networks, and apply it to the task of template protection for face authentication. We use deep convolutional neural networks (CNNs) to learn a mapping from face images to maximum entropy binary (MEB) codes. The mapping is robust enough to tackle the problem of exact matching, yielding the same code for new samples of a user as the code assigned during training. These codes are then hashed using any hash function that follows the random oracle model (like SHA-512) to generate protected face templates (similar to text based password protection). The algorithm makes no unrealistic assumptions and offers high template security, cancelability, and state-of-the-art matching performance. The efficacy of the approach is shown on CMU-PIE, Extended Yale B, and Multi-PIE face databases. We achieve high (~95%) genuine accept rates (GAR) at zero false accept rate (FAR) with up to 1024 bits of template security.