 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Scaling of Diffusion Transformers for Text-to-Image Generation
Dec 16, 2024



We empirically study the scaling properties of various Diffusion Transformers (DiTs) for text-to-image generation by performing extensive and rigorous ablations, including training scaled DiTs ranging from 0.3B upto 8B parameters on datasets up to 600M images. We find that U-ViT, a pure self-attention based DiT model provides a simpler design and scales more effectively in comparison with cross-attention based DiT variants, which allows straightforward expansion for extra conditions and other modalities. We identify a 2.3B U-ViT model can get better performance than SDXL UNet and other DiT variants in controlled setting. On the data scaling side, we investigate how increasing dataset size and enhanced long caption improve the text-image alignment performance and the learning efficiency.
ABQ-LLM: Arbitrary-Bit Quantized Inference Acceleration for Large Language Models
Aug 16, 2024



Large Language Models (LLMs) have revolutionized natural language processing tasks. However, their practical application is constrained by substantial memory and computational demands. Post-training quantization (PTQ) is considered an effective method to accelerate LLM inference. Despite its growing popularity in LLM model compression, PTQ deployment faces two major challenges. First, low-bit quantization leads to performance degradation. Second, restricted by the limited integer computing unit type on GPUs, quantized matrix operations with different precisions cannot be effectively accelerated. To address these issues, we introduce a novel arbitrary-bit quantization algorithm and inference framework, ABQ-LLM. It achieves superior performance across various quantization settings and enables efficient arbitrary-precision quantized inference on the GPU. ABQ-LLM introduces several key innovations: (1) a distribution correction method for transformer blocks to mitigate distribution differences caused by full quantization of weights and activations, improving performance at low bit-widths. (2) the bit balance strategy to counteract performance degradation from asymmetric distribution issues at very low bit-widths (e.g., 2-bit). (3) an innovative quantization acceleration framework that reconstructs the quantization matrix multiplication of arbitrary precision combinations based on BTC (Binary TensorCore) equivalents, gets rid of the limitations of INT4/INT8 computing units. ABQ-LLM can convert each component bit width gain into actual acceleration gain, maximizing performance under mixed precision(e.g., W6A6, W2A8). Based on W2*A8 quantization configuration on LLaMA-7B model, it achieved a WikiText2 perplexity of 7.59 (2.17$\downarrow $ vs 9.76 in AffineQuant). Compared to SmoothQuant, we realized 1.6$\times$ acceleration improvement and 2.7$\times$ memory compression gain.
Diffusion Soup: Model Merging for Text-to-Image Diffusion Models
Jun 12, 2024



We present Diffusion Soup, a compartmentalization method for Text-to-Image Generation that averages the weights of diffusion models trained on sharded data. By construction, our approach enables training-free continual learning and unlearning with no additional memory or inference costs, since models corresponding to data shards can be added or removed by re-averaging. We show that Diffusion Soup samples from a point in weight space that approximates the geometric mean of the distributions of constituent datasets, which offers anti-memorization guarantees and enables zero-shot style mixing. Empirically, Diffusion Soup outperforms a paragon model trained on the union of all data shards and achieves a 30% improvement in Image Reward (.34 $\to$ .44) on domain sharded data, and a 59% improvement in IR (.37 $\to$ .59) on aesthetic data. In both cases, souping also prevails in TIFA score (respectively, 85.5 $\to$ 86.5 and 85.6 $\to$ 86.8). We demonstrate robust unlearning -- removing any individual domain shard only lowers performance by 1% in IR (.45 $\to$ .44) -- and validate our theoretical insights on anti-memorization using real data. Finally, we showcase Diffusion Soup's ability to blend the distinct styles of models finetuned on different shards, resulting in the zero-shot generation of hybrid styles.
FairRAG: Fair Human Generation via Fair Retrieval Augmentation
Apr 05, 2024



Existing text-to-image generative models reflect or even amplify societal biases ingrained in their training data. This is especially concerning for human image generation where models are biased against certain demographic groups. Existing attempts to rectify this issue are hindered by the inherent limitations of the pre-trained models and fail to substantially improve demographic diversity. In this work, we introduce Fair Retrieval Augmented Generation (FairRAG), a novel framework that conditions pre-trained generative models on reference images retrieved from an external image database to improve fairness in human generation. FairRAG enables conditioning through a lightweight linear module that projects reference images into the textual space. To enhance fairness, FairRAG applies simple-yet-effective debiasing strategies, providing images from diverse demographic groups during the generative process. Extensive experiments demonstrate that FairRAG outperforms existing methods in terms of demographic diversity, image-text alignment, and image fidelity while incurring minimal computational overhead during inference.
On the Scalability of Diffusion-based Text-to-Image Generation
Apr 03, 2024Scaling up model and data size has been quite successful for the evolution of LLMs. However, the scaling law for the diffusion based text-to-image (T2I) models is not fully explored. It is also unclear how to efficiently scale the model for better performance at reduced cost. The different training settings and expensive training cost make a fair model comparison extremely difficult. In this work, we empirically study the scaling properties of diffusion based T2I models by performing extensive and rigours ablations on scaling both denoising backbones and training set, including training scaled UNet and Transformer variants ranging from 0.4B to 4B parameters on datasets upto 600M images. For model scaling, we find the location and amount of cross attention distinguishes the performance of existing UNet designs. And increasing the transformer blocks is more parameter-efficient for improving text-image alignment than increasing channel numbers. We then identify an efficient UNet variant, which is 45% smaller and 28% faster than SDXL's UNet. On the data scaling side, we show the quality and diversity of the training set matters more than simply dataset size. Increasing caption density and diversity improves text-image alignment performance and the learning efficiency. Finally, we provide scaling functions to predict the text-image alignment performance as functions of the scale of model size, compute and dataset size.
MAGID: An Automated Pipeline for Generating Synthetic Multi-modal Datasets
Mar 05, 2024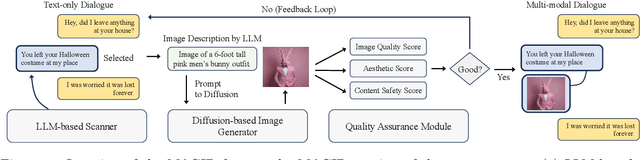



Development of multimodal interactive systems is hindered by the lack of rich, multimodal (text, images) conversational data, which is needed in large quantities for LLMs. Previous approaches augment textual dialogues with retrieved images, posing privacy, diversity, and quality constraints. In this work, we introduce \textbf{M}ultimodal \textbf{A}ugmented \textbf{G}enerative \textbf{I}mages \textbf{D}ialogues (MAGID), a framework to augment text-only dialogues with diverse and high-quality images. Subsequently, a diffusion model is applied to craft corresponding images, ensuring alignment with the identified text. Finally, MAGID incorporates an innovative feedback loop between an image description generation module (textual LLM) and image quality modules (addressing aesthetics, image-text matching, and safety), that work in tandem to generate high-quality and multi-modal dialogues. We compare MAGID to other SOTA baselines on three dialogue datasets, using automated and human evaluation. Our results show that MAGID is comparable to or better than baselines, with significant improvements in human evaluation, especially against retrieval baselines where the image database is small.
Multiple-Question Multiple-Answer Text-VQA
Nov 15, 2023



We present Multiple-Question Multiple-Answer (MQMA), a novel approach to do text-VQA in encoder-decoder transformer models. The text-VQA task requires a model to answer a question by understanding multi-modal content: text (typically from OCR) and an associated image. To the best of our knowledge, almost all previous approaches for text-VQA process a single question and its associated content to predict a single answer. In order to answer multiple questions from the same image, each question and content are fed into the model multiple times. In contrast, our proposed MQMA approach takes multiple questions and content as input at the encoder and predicts multiple answers at the decoder in an auto-regressive manner at the same time. We make several novel architectural modifications to standard encoder-decoder transformers to support MQMA. We also propose a novel MQMA denoising pre-training task which is designed to teach the model to align and delineate multiple questions and content with associated answers. MQMA pre-trained model achieves state-of-the-art results on multiple text-VQA datasets, each with strong baselines. Specifically, on OCR-VQA (+2.5%), TextVQA (+1.4%), ST-VQA (+0.6%), DocVQA (+1.1%) absolute improvements over the previous state-of-the-art approaches.
SimCon Loss with Multiple Views for Text Supervised Semantic Segmentation
Feb 07, 2023



Learning to segment images purely by relying on the image-text alignment from web data can lead to sub-optimal performance due to noise in the data. The noise comes from the samples where the associated text does not correlate with the image's visual content. Instead of purely relying on the alignment from the noisy data, this paper proposes a novel loss function termed SimCon, which accounts for intra-modal similarities to determine the appropriate set of positive samples to align. Further, using multiple views of the image (created synthetically) for training and combining the SimCon loss with it makes the training more robust. This version of the loss is termed MV-SimCon. The empirical results demonstrate that using the proposed loss function leads to consistent improvements on zero-shot, text supervised semantic segmentation and outperforms state-of-the-art by $+3.0\%$, $+3.3\%$ and $+6.9\%$ on PASCAL VOC, PASCAL Context and MSCOCO, respectively. With test time augmentations, we set a new record by improving these results further to $58.7\%$, $26.6\%$, and $33.3\%$ on PASCAL VOC, PASCAL Context, and MSCOCO, respectively. In addition, using the proposed loss function leads to robust training and faster convergence.
AIM: Adapting Image Models for Efficient Video Action Recognition
Feb 06, 2023



Recent vision transformer based video models mostly follow the ``image pre-training then finetuning" paradigm and have achieved great success on multiple video benchmarks. However, full finetuning such a video model could be computationally expensive and unnecessary, given the pre-trained image transformer models have demonstrated exceptional transferability. In this work, we propose a novel method to Adapt pre-trained Image Models (AIM) for efficient video understanding. By freezing the pre-trained image model and adding a few lightweight Adapters, we introduce spatial adaptation, temporal adaptation and joint adaptation to gradually equip an image model with spatiotemporal reasoning capability. We show that our proposed AIM can achieve competitive or even better performance than prior arts with substantially fewer tunable parameters on four video action recognition benchmarks. Thanks to its simplicity, our method is also generally applicable to different image pre-trained models, which has the potential to leverage more powerful image foundation models in the future. The project webpage is \url{https://adapt-image-models.github.io/}.
Towards Differential Relational Privacy and its use in Question Answering
Mar 30, 2022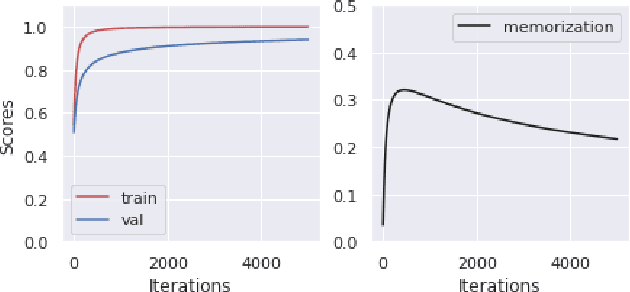

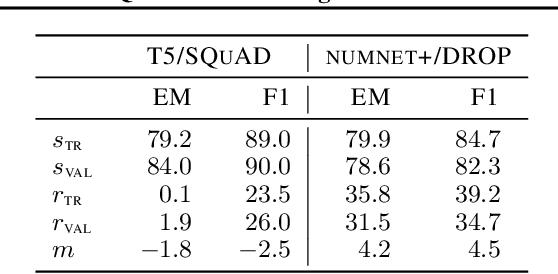
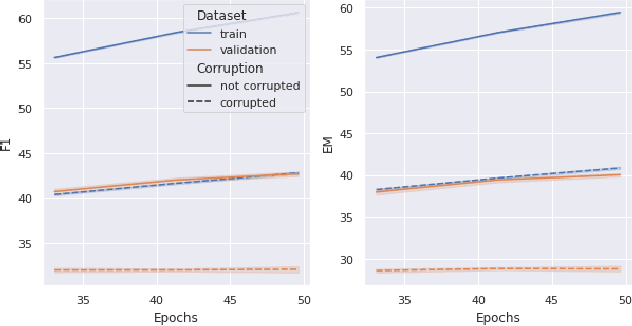
Memorization of the relation between entities in a dataset can lead to privacy issues when using a trained model for question answering. We introduce Relational Memorization (RM) to understand, quantify and control this phenomenon. While bounding general memorization can have detrimental effects on the performance of a trained model, bounding RM does not prevent effective learning. The difference is most pronounced when the data distribution is long-tailed, with many queries having only few training examples: Impeding general memorization prevents effective learning, while impeding only relational memorization still allows learning general properties of the underlying concepts. We formalize the notion of Relational Privacy (RP) and, inspired by Differential Privacy (DP), we provide a possible definition of Differential Relational Privacy (DrP). These notions can be used to describe and compute bounds on the amount of RM in a trained model. We illustrate Relational Privacy concepts in experiments with large-scale models for Question Answering.