 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAGID: An Automated Pipeline for Generating Synthetic Multi-modal Datasets
Mar 05, 2024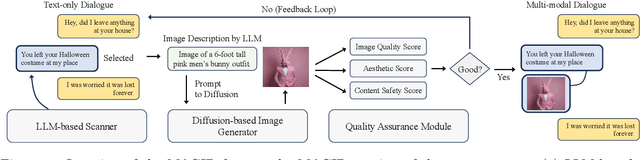



Development of multimodal interactive systems is hindered by the lack of rich, multimodal (text, images) conversational data, which is needed in large quantities for LLMs. Previous approaches augment textual dialogues with retrieved images, posing privacy, diversity, and quality constraints. In this work, we introduce \textbf{M}ultimodal \textbf{A}ugmented \textbf{G}enerative \textbf{I}mages \textbf{D}ialogues (MAGID), a framework to augment text-only dialogues with diverse and high-quality images. Subsequently, a diffusion model is applied to craft corresponding images, ensuring alignment with the identified text. Finally, MAGID incorporates an innovative feedback loop between an image description generation module (textual LLM) and image quality modules (addressing aesthetics, image-text matching, and safety), that work in tandem to generate high-quality and multi-modal dialogues. We compare MAGID to other SOTA baselines on three dialogue datasets, using automated and human evaluation. Our results show that MAGID is comparable to or better than baselines, with significant improvements in human evaluation, especially against retrieval baselines where the image database is small.
DeepfakeArt Challenge: A Benchmark Dataset for Generative AI Art Forgery and Data Poisoning Detection
Jun 11, 2023



The tremendous recent advances in generative artificial intelligence techniques have led to significant successes and promise in a wide range of different applications ranging from conversational agents and textual content generation to voice and visual synthesis. Amid the rise in generative AI and its increasing widespread adoption, there has been significant growing concern over the use of generative AI for malicious purposes. In the realm of visual content synthesis using generative AI, key areas of significant concern has been image forgery (e.g., generation of images containing or derived from copyright content), and data poisoning (i.e., generation of adversarially contaminated images). Motivated to address these key concerns to encourage responsible generative AI, we introduce the DeepfakeArt Challenge, a large-scale challenge benchmark dataset designed specifically to aid in the building of machine learning algorithms for generative AI art forgery and data poisoning detection. Comprising of over 32,000 records across a variety of generative forgery and data poisoning techniques, each entry consists of a pair of images that are either forgeries / adversarially contaminated or not. Each of the generated images in the DeepfakeArt Challenge benchmark dataset has been quality checked in a comprehensive manner. The DeepfakeArt Challenge is a core part of GenAI4Good, a global open source initiative for accelerating machine learning for promoting responsible creation and deployment of generative AI for good.
COVIDx CXR-3: A Large-Scale, Open-Source Benchmark Dataset of Chest X-ray Images for Computer-Aided COVID-19 Diagnostics
Jun 08, 2022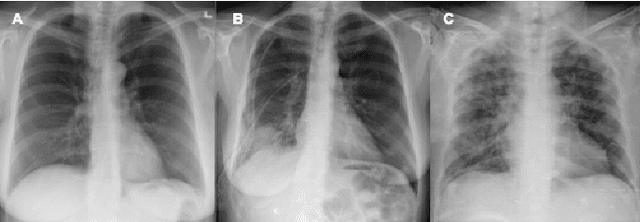
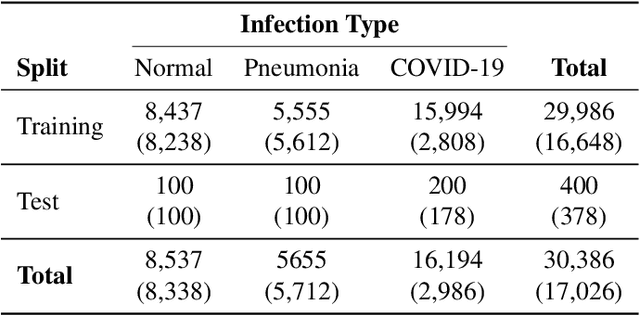
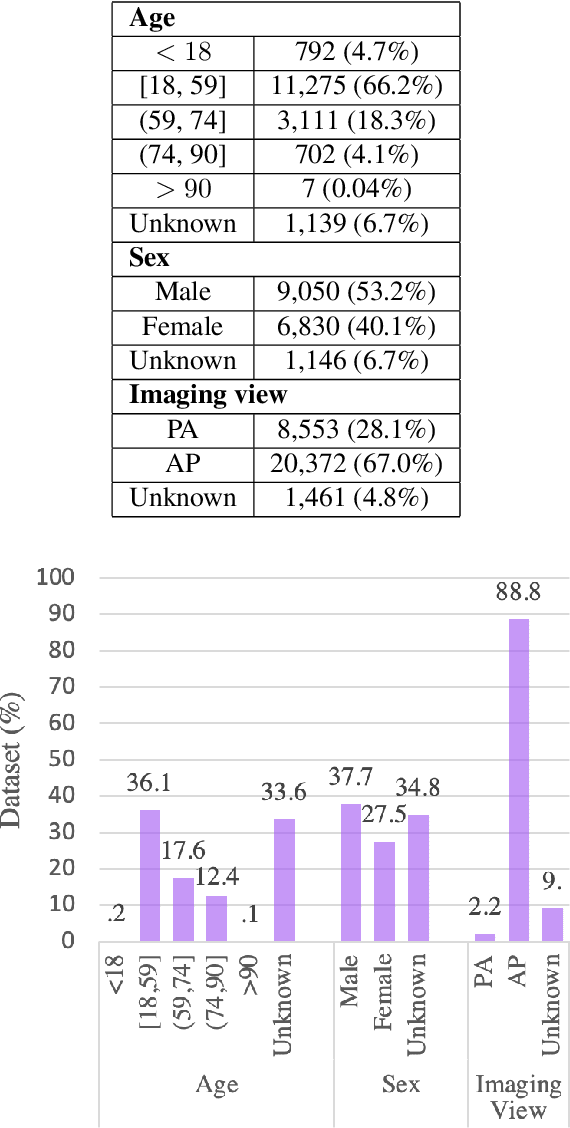
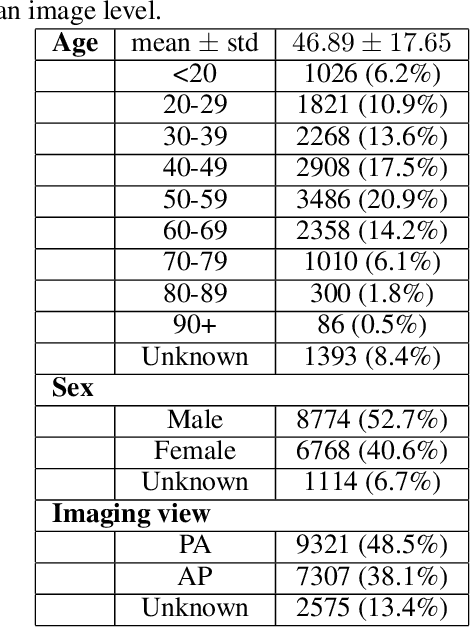
After more than two years since the beginning of the COVID-19 pandemic, the pressure of this crisis continues to devastate globally. The use of chest X-ray (CXR) imaging as a complementary screening strategy to RT-PCR testing is not only prevailing but has greatly increased due to its routine clinical use for respiratory complaints. Thus far, many visual perception models have been proposed for COVID-19 screening based on CXR imaging. Nevertheless, the accuracy and the generalization capacity of these models are very much dependent on the diversity and the size of the dataset they were trained on. Motivated by this, we introduce COVIDx CXR-3, a large-scale benchmark dataset of CXR images for supporting COVID-19 computer vision research. COVIDx CXR-3 is composed of 30,386 CXR images from a multinational cohort of 17,026 patients from at least 51 countries, making it, to the best of our knowledge, the most extensive, most diverse COVID-19 CXR dataset in open access form. Here, we provide comprehensive details on the various aspects of the proposed dataset including patient demographics, imaging views, and infection types. The hope is that COVIDx CXR-3 can assist scientists in advancing computer vision research against the COVID-19 pandemic.
COVID-Net Biochem: An Explainability-driven Framework to Building Machine Learning Models for Predicting Survival and Kidney Injury of COVID-19 Patients from Clinical and Biochemistry Data
Apr 24, 2022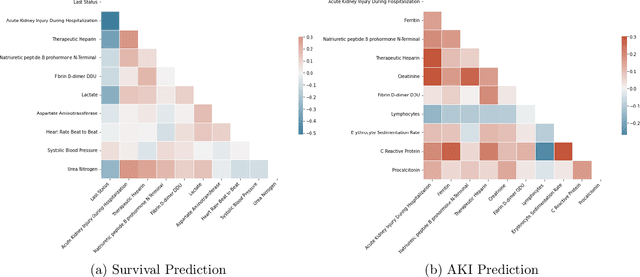
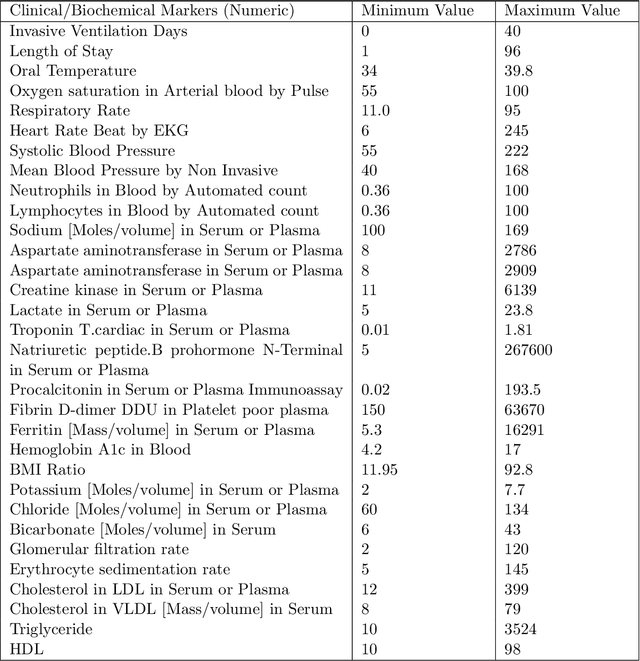
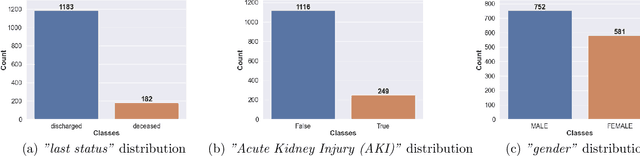
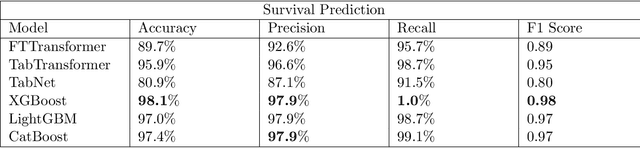
Ever since the declaration of COVID-19 as a pandemic by the World Health Organization in 2020, the world has continued to struggle in controlling and containing the spread of the COVID-19 pandemic caused by the SARS-CoV-2 virus. This has been especially challenging with the rise of the Omicron variant and its subvariants and recombinants, which has led to a significant increase in patients seeking treatment and has put a tremendous burden on hospitals and healthcare systems. A major challenge faced during the pandemic has been the prediction of survival and the risk for additional injuries in individual patients, which requires significant clinical expertise and additional resources to avoid further complications. In this study we propose COVID-Net Biochem, an explainability-driven framework for building machine learning models to predict patient survival and the chance of developing kidney injury during hospitalization from clinical and biochemistry data in a transparent and systematic manner. In the first "clinician-guided initial design" phase, we prepared a benchmark dataset of carefully selected clinical and biochemistry data based on clinician assessment, which were curated from a patient cohort of 1366 patients at Stony Brook University. A collection of different machine learning models with a diversity of gradient based boosting tree architectures and deep transformer architectures was designed and trained specifically for survival and kidney injury prediction based on the carefully selected clinical and biochemical markers.
MEDUSA: Multi-scale Encoder-Decoder Self-Attention Deep Neural Network Architecture for Medical Image Analysis
Oct 12, 2021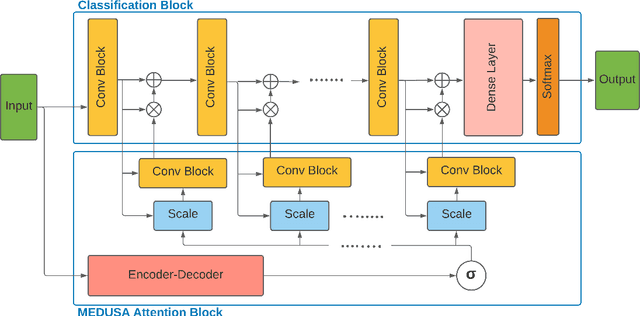
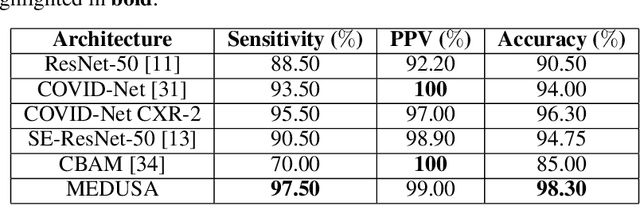

Medical image analysis continues to hold interesting challenges given the subtle characteristics of certain diseases and the significant overlap in appearance between diseases. In this work, we explore the concept of self-attention for tackling such subtleties in and between diseases. To this end, we introduce MEDUSA, a multi-scale encoder-decoder self-attention mechanism tailored for medical image analysis. While self-attention deep convolutional neural network architectures in existing literature center around the notion of multiple isolated lightweight attention mechanisms with limited individual capacities being incorporated at different points in the network architecture, MEDUSA takes a significant departure from this notion by possessing a single, unified self-attention mechanism with significantly higher capacity with multiple attention heads feeding into different scales in the network architecture. To the best of the authors' knowledge, this is the first "single body, multi-scale heads" realization of self-attention and enables explicit global context amongst selective attention at different levels of representational abstractions while still enabling differing local attention context at individual levels of abstractions. With MEDUSA, we obtain state-of-the-art performance on multiple challenging medical image analysis benchmarks including COVIDx, RSNA RICORD, and RSNA Pneumonia Challenge when compared to previous work. Our MEDUSA model is publicly available.
COVID-Net MLSys: Designing COVID-Net for the Clinical Workflow
Sep 14, 2021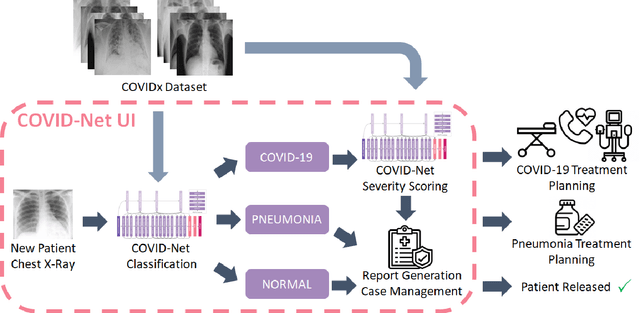
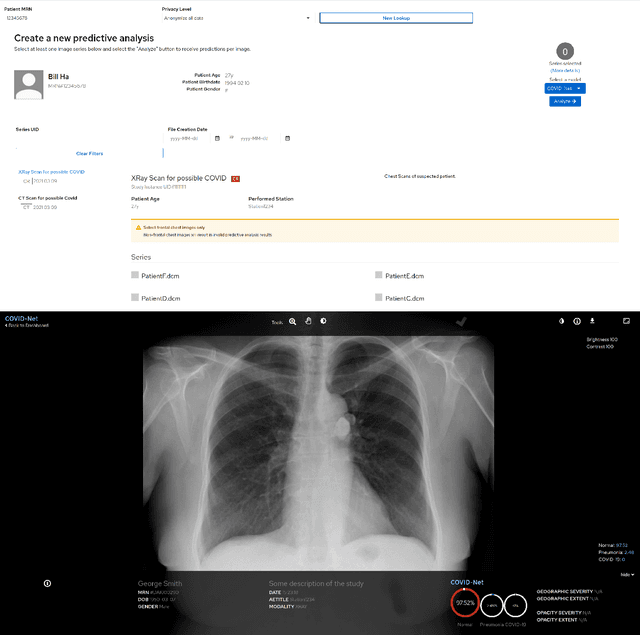
As the COVID-19 pandemic continues to devastate globally, one promising field of research is machine learning-driven computer vision to streamline various parts of the COVID-19 clinical workflow. These machine learning methods are typically stand-alone models designed without consideration for the integration necessary for real-world application workflows. In this study, we take a machine learning and systems (MLSys) perspective to design a system for COVID-19 patient screening with the clinical workflow in mind. The COVID-Net system is comprised of the continuously evolving COVIDx dataset, COVID-Net deep neural network for COVID-19 patient detection, and COVID-Net S deep neural networks for disease severity scoring for COVID-19 positive patient cases. The deep neural networks within the COVID-Net system possess state-of-the-art performance, and are designed to be integrated within a user interface (UI) for clinical decision support with automatic report generation to assist clinicians in their treatment decisions.
Where Did You Learn That From? Surprising Effectiveness of Membership Inference Attacks Against Temporally Correlated Data in Deep Reinforcement Learning
Sep 08, 2021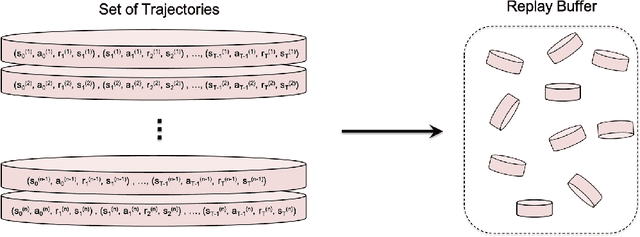
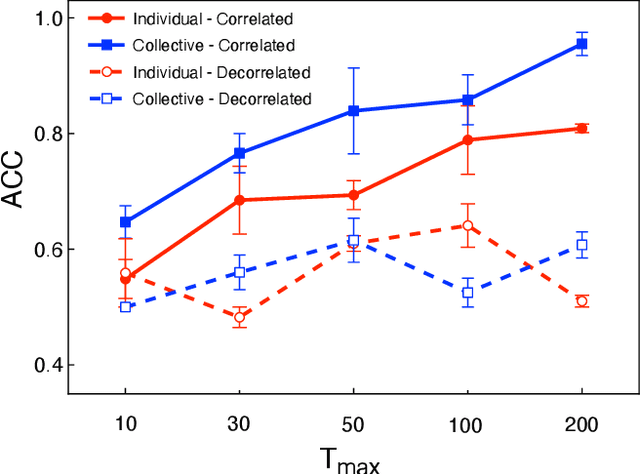
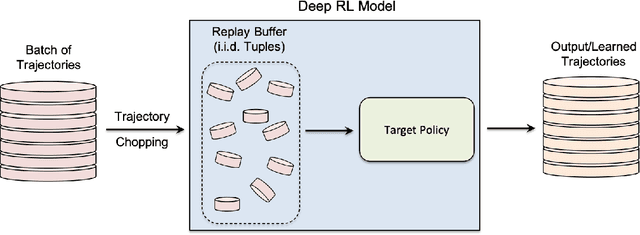

While significant research advances have been made in the field of deep reinforcement learning, a major challenge to widespread industrial adoption of deep reinforcement learning that has recently surfaced but little explored is the potential vulnerability to privacy breaches. In particular, there have been no concrete adversarial attack strategies in literature tailored for studying the vulnerability of deep reinforcement learning algorithms to membership inference attacks. To address this gap, we propose an adversarial attack framework tailored for testing the vulnerability of deep reinforcement learning algorithms to membership inference attacks. More specifically, we design a series of experiments to investigate the impact of temporal correlation, which naturally exists in reinforcement learning training data, on the probability of information leakage. Furthermore, we study the differences in the performance of \emph{collective} and \emph{individual} membership attacks against deep reinforcement learning algorithms. Experimental results show that the proposed adversarial attack framework is surprisingly effective at inferring the data used during deep reinforcement training with an accuracy exceeding $84\%$ in individual and $97\%$ in collective mode on two different control tasks in OpenAI Gym, which raises serious privacy concerns in the deployment of models resulting from deep reinforcement learning. Moreover, we show that the learning state of a reinforcement learning algorithm significantly influences the level of the privacy breach.
Residual Error: a New Performance Measure for Adversarial Robustness
Jun 18, 2021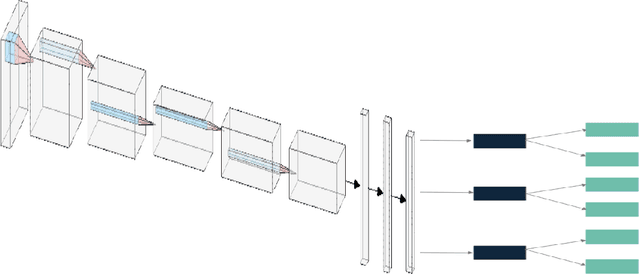

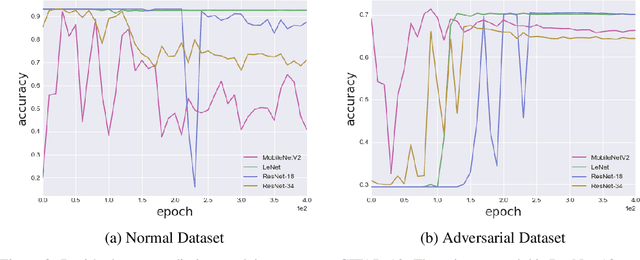

Despite the significant advances in deep learning over the past decade, a major challenge that limits the wide-spread adoption of deep learning has been their fragility to adversarial attacks. This sensitivity to making erroneous predictions in the presence of adversarially perturbed data makes deep neural networks difficult to adopt for certain real-world, mission-critical applications. While much of the research focus has revolved around adversarial example creation and adversarial hardening, the area of performance measures for assessing adversarial robustness is not well explored. Motivated by this, this study presents the concept of residual error, a new performance measure for not only assessing the adversarial robustness of a deep neural network at the individual sample level, but also can be used to differentiate between adversarial and non-adversarial examples to facilitate for adversarial example detection. Furthermore, we introduce a hybrid model for approximating the residual error in a tractable manner. Experimental results using the case of image classification demonstrates the effectiveness and efficacy of the proposed residual error metric for assessing several well-known deep neural network architectures. These results thus illustrate that the proposed measure could be a useful tool for not only assessing the robustness of deep neural networks used in mission-critical scenarios, but also in the design of adversarially robust models.
COVID-Net CXR-2: An Enhanced Deep Convolutional Neural Network Design for Detection of COVID-19 Cases from Chest X-ray Images
May 14, 2021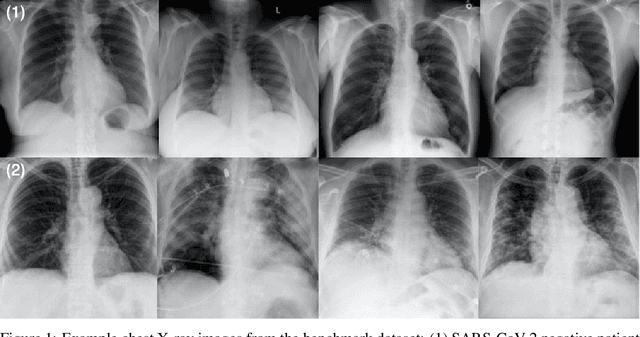
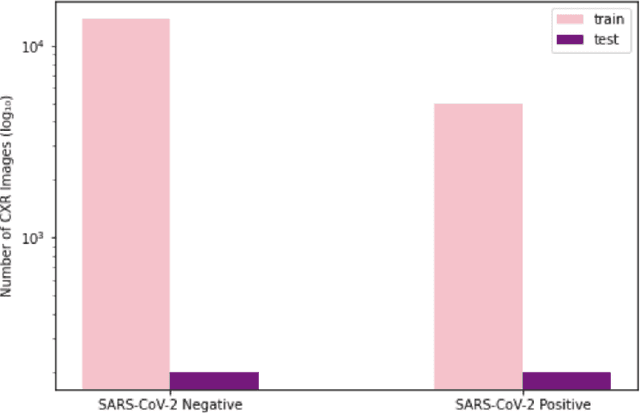
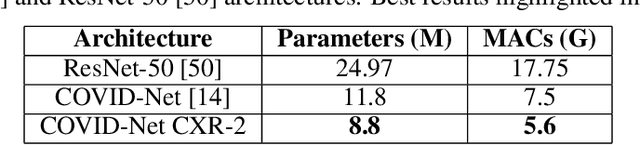
As the COVID-19 pandemic continues to devastate globally, the use of chest X-ray (CXR) imaging as a complimentary screening strategy to RT-PCR testing continues to grow given its routine clinical use for respiratory complaint. As part of the COVID-Net open source initiative, we introduce COVID-Net CXR-2, an enhanced deep convolutional neural network design for COVID-19 detection from CXR images built using a greater quantity and diversity of patients than the original COVID-Net. To facilitate this, we also introduce a new benchmark dataset composed of 19,203 CXR images from a multinational cohort of 16,656 patients from at least 51 countries, making it the largest, most diverse COVID-19 CXR dataset in open access form. The COVID-Net CXR-2 network achieves sensitivity and positive predictive value of 95.5%/97.0%, respectively, and was audited in a transparent and responsible manner. Explainability-driven performance validation was used during auditing to gain deeper insights in its decision-making behaviour and to ensure clinically relevant factors are leveraged for improving trust in its usage. Radiologist validation was also conducted, where select cases were reviewed and reported on by two board-certified radiologists with over 10 and 19 years of experience, respectively, and showed that the critical factors leveraged by COVID-Net CXR-2 are consistent with radiologist interpretations. While not a production-ready solution, we hope the open-source, open-access release of COVID-Net CXR-2 and the respective CXR benchmark dataset will encourage researchers, clinical scientists, and citizen scientists to accelerate advancements and innovations in the fight against the pandemic.
COVID-Net CT-S: 3D Convolutional Neural Network Architectures for COVID-19 Severity Assessment using Chest CT Images
May 04, 2021



The health and socioeconomic difficulties caused by the COVID-19 pandemic continues to cause enormous tensions around the world. In particular, this extraordinary surge in the number of cases has put considerable strain on health care systems around the world. A critical step in the treatment and management of COVID-19 positive patients is severity assessment, which is challenging even for expert radiologists given the subtleties at different stages of lung disease severity. Motivated by this challenge, we introduce COVID-Net CT-S, a suite of deep convolutional neural networks for predicting lung disease severity due to COVID-19 infection. More specifically, a 3D residual architecture design is leveraged to learn volumetric visual indicators characterizing the degree of COVID-19 lung disease severity. Experimental results using the patient cohort collected by the China National Center for Bioinformation (CNCB) showed that the proposed COVID-Net CT-S networks, by leveraging volumetric features, can achieve significantly improved severity assessment performance when compared to traditional severity assessment networks that learn and leverage 2D visual features to characterize COVID-19 severity.