 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdCraft: An Advanced Reinforcement Learning Benchmark Environment for Search Engine Marketing Optimization
Jun 22, 2023We introduce AdCraft, a novel benchmark environment for the Reinforcement Learning (RL) community distinguished by its stochastic and non-stationary properties. The environment simulates bidding and budgeting dynamics within Search Engine Marketing (SEM), a digital marketing technique utilizing paid advertising to enhance the visibility of websites on search engine results pages (SERPs). The performance of SEM advertisement campaigns depends on several factors, including keyword selection, ad design, bid management, budget adjustments, and performance monitoring. Deep RL recently emerged as a potential strategy to optimize campaign profitability within the complex and dynamic landscape of SEM but it requires substantial data, which may be costly or infeasible to acquire in practice. Our customizable environment enables practitioners to assess and enhance the robustness of RL algorithms pertinent to SEM bid and budget management without such costs. Through a series of experiments within the environment, we demonstrate the challenges imposed by sparsity and non-stationarity on agent convergence and performance. We hope these challenges further encourage discourse and development around effective strategies for managing real-world uncertainties.
Where Did You Learn That From? Surprising Effectiveness of Membership Inference Attacks Against Temporally Correlated Data in Deep Reinforcement Learning
Sep 08, 2021
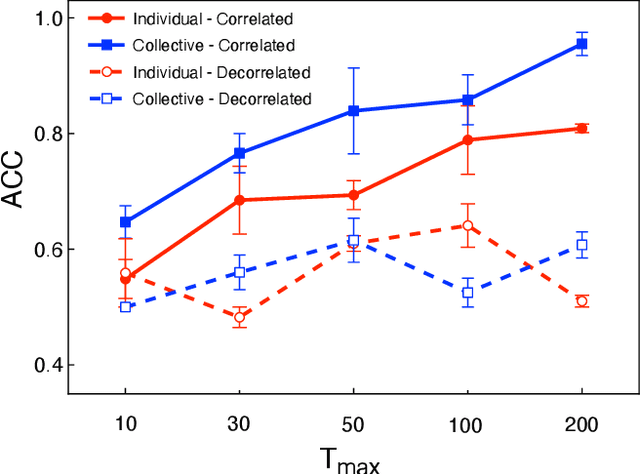

While significant research advances have been made in the field of deep reinforcement learning, a major challenge to widespread industrial adoption of deep reinforcement learning that has recently surfaced but little explored is the potential vulnerability to privacy breaches. In particular, there have been no concrete adversarial attack strategies in literature tailored for studying the vulnerability of deep reinforcement learning algorithms to membership inference attacks. To address this gap, we propose an adversarial attack framework tailored for testing the vulnerability of deep reinforcement learning algorithms to membership inference attacks. More specifically, we design a series of experiments to investigate the impact of temporal correlation, which naturally exists in reinforcement learning training data, on the probability of information leakage. Furthermore, we study the differences in the performance of \emph{collective} and \emph{individual} membership attacks against deep reinforcement learning algorithms. Experimental results show that the proposed adversarial attack framework is surprisingly effective at inferring the data used during deep reinforcement training with an accuracy exceeding $84\%$ in individual and $97\%$ in collective mode on two different control tasks in OpenAI Gym, which raises serious privacy concerns in the deployment of models resulting from deep reinforcement learning. Moreover, we show that the learning state of a reinforcement learning algorithm significantly influences the level of the privacy breach.
A Survey of Exploration Methods in Reinforcement Learning
Sep 02, 2021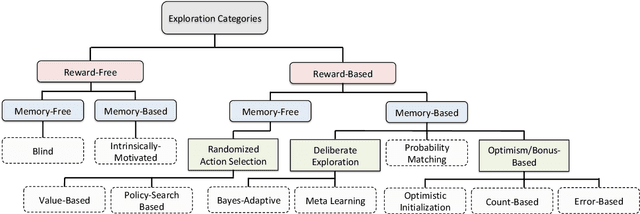
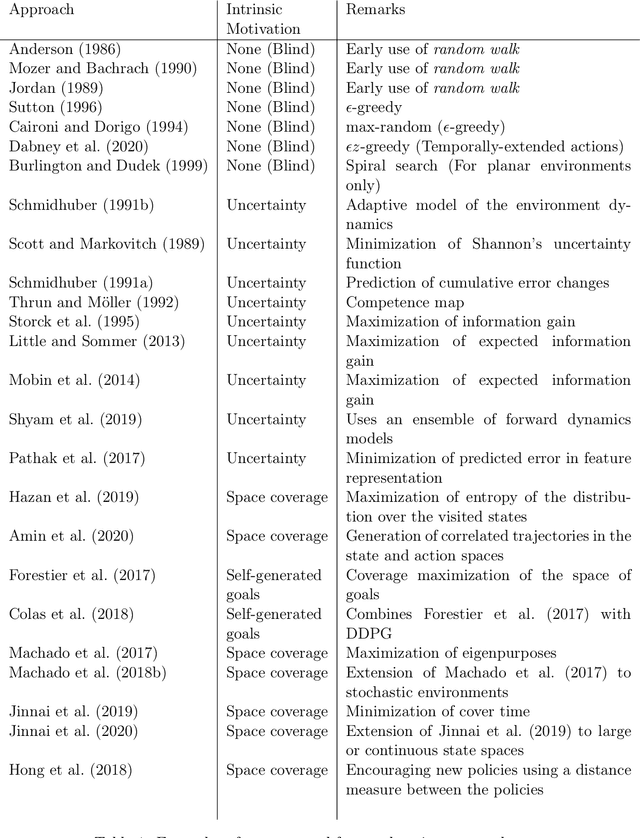
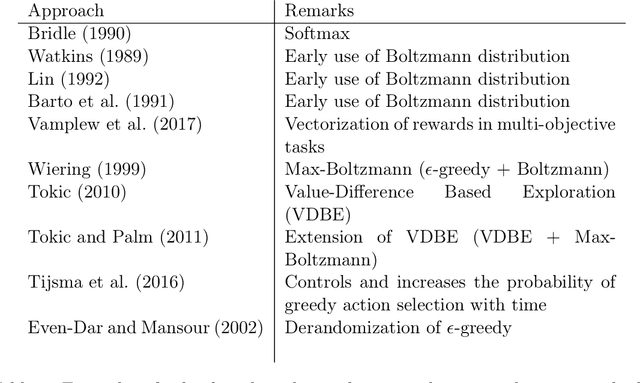
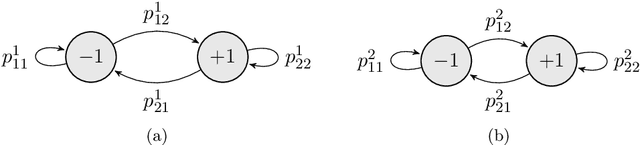
Exploration is an essential component of reinforcement learning algorithms, where agents need to learn how to predict and control unknown and often stochastic environments. Reinforcement learning agents depend crucially on exploration to obtain informative data for the learning process as the lack of enough information could hinder effective learning. In this article, we provide a survey of modern exploration methods in (Sequential) reinforcement learning, as well as a taxonomy of exploration methods.
Locally Persistent Exploration in Continuous Control Tasks with Sparse Rewards
Dec 26, 2020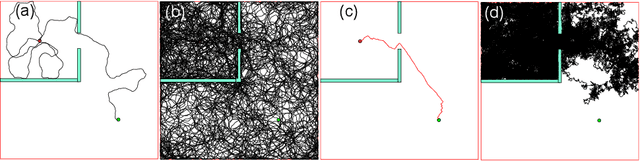
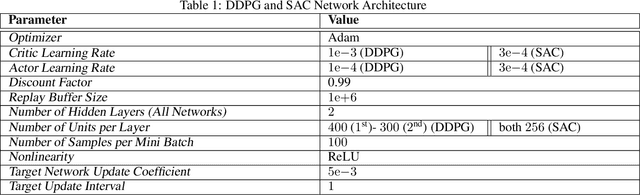
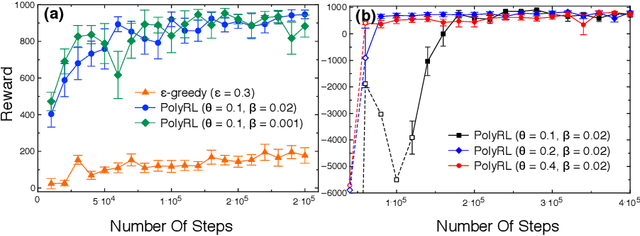
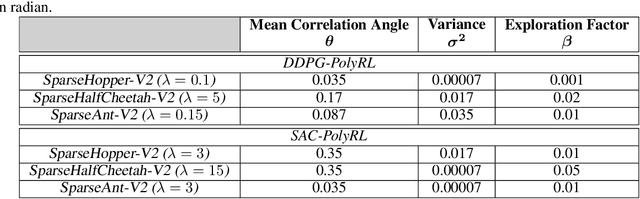
A major challenge in reinforcement learning is the design of exploration strategies, especially for environments with sparse reward structures and continuous state and action spaces. Intuitively, if the reinforcement signal is very scarce, the agent should rely on some form of short-term memory in order to cover its environment efficiently. We propose a new exploration method, based on two intuitions: (1) the choice of the next exploratory action should depend not only on the (Markovian) state of the environment, but also on the agent's trajectory so far, and (2) the agent should utilize a measure of spread in the state space to avoid getting stuck in a small region. Our method leverages concepts often used in statistical physics to provide explanations for the behavior of simplified (polymer) chains, in order to generate persistent (locally self-avoiding) trajectories in state space. We discuss the theoretical properties of locally self-avoiding walks, and their ability to provide a kind of short-term memory, through a decaying temporal correlation within the trajectory. We provide empirical evaluations of our approach in a simulated 2D navigation task, as well as higher-dimensional MuJoCo continuous control locomotion tasks with sparse rewards.
Reproducibility of Benchmarked Deep Reinforcement Learning Tasks for Continuous Control
Aug 10, 2017


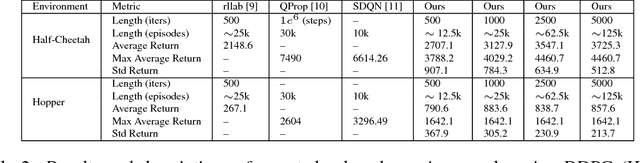
Policy gradient methods in reinforcement learning have become increasingly prevalent for state-of-the-art performance in continuous control tasks. Novel methods typically benchmark against a few key algorithms such as deep deterministic policy gradients and trust region policy optimization. As such, it is important to present and use consistent baselines experiments. However, this can be difficult due to general variance in the algorithms, hyper-parameter tuning, and environment stochasticity. We investigate and discuss: the significance of hyper-parameters in policy gradients for continuous control, general variance in the algorithms, and reproducibility of reported results. We provide guidelines on reporting novel results as comparisons against baseline methods such that future researchers can make informed decisions when investigating novel methods.
Differentially Private Policy Evaluation
Mar 07, 2016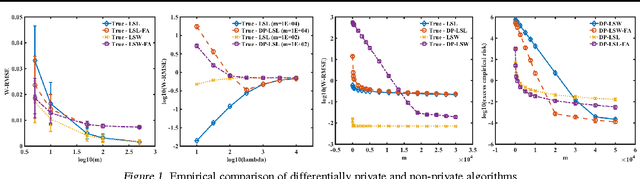
We present the first differentially private algorithms for reinforcement learning, which apply to the task of evaluating a fixed policy. We establish two approaches for achieving differential privacy, provide a theoretical analysis of the privacy and utility of the two algorithms, and show promising results on simple empirical examples.