 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Did You Learn That From? Surprising Effectiveness of Membership Inference Attacks Against Temporally Correlated Data in Deep Reinforcement Learning
Sep 08, 2021
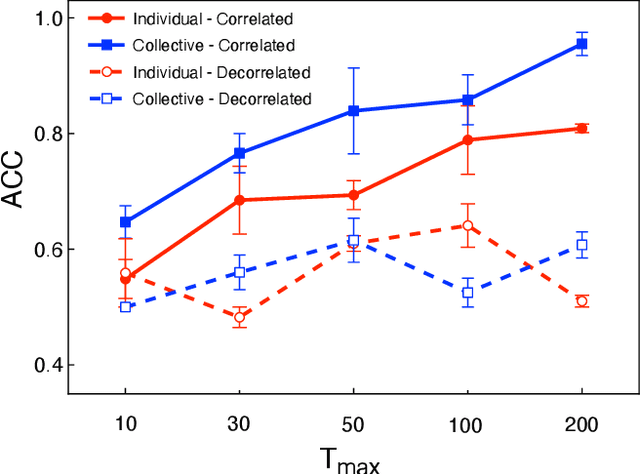

While significant research advances have been made in the field of deep reinforcement learning, a major challenge to widespread industrial adoption of deep reinforcement learning that has recently surfaced but little explored is the potential vulnerability to privacy breaches. In particular, there have been no concrete adversarial attack strategies in literature tailored for studying the vulnerability of deep reinforcement learning algorithms to membership inference attacks. To address this gap, we propose an adversarial attack framework tailored for testing the vulnerability of deep reinforcement learning algorithms to membership inference attacks. More specifically, we design a series of experiments to investigate the impact of temporal correlation, which naturally exists in reinforcement learning training data, on the probability of information leakage. Furthermore, we study the differences in the performance of \emph{collective} and \emph{individual} membership attacks against deep reinforcement learning algorithms. Experimental results show that the proposed adversarial attack framework is surprisingly effective at inferring the data used during deep reinforcement training with an accuracy exceeding $84\%$ in individual and $97\%$ in collective mode on two different control tasks in OpenAI Gym, which raises serious privacy concerns in the deployment of models resulting from deep reinforcement learning. Moreover, we show that the learning state of a reinforcement learning algorithm significantly influences the level of the privacy breach.
A Survey of Exploration Methods in Reinforcement Learning
Sep 02, 2021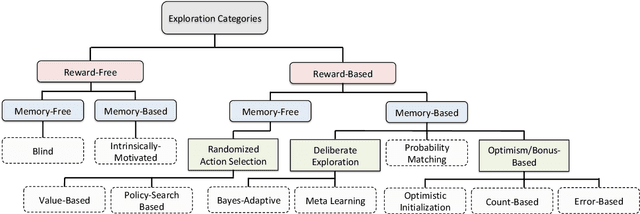
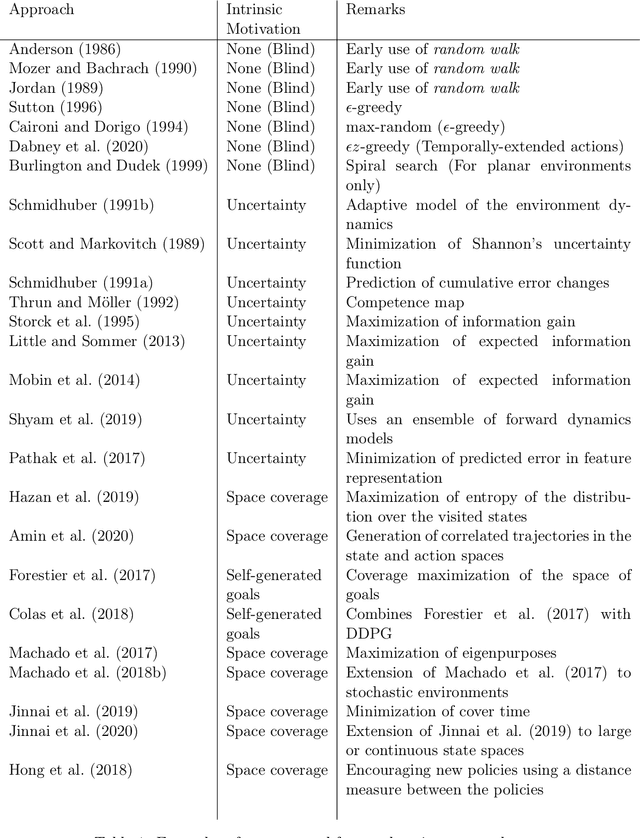
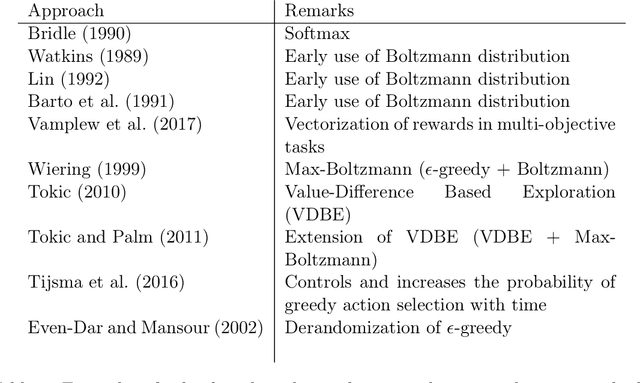
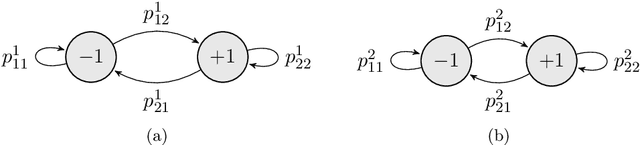
Exploration is an essential component of reinforcement learning algorithms, where agents need to learn how to predict and control unknown and often stochastic environments. Reinforcement learning agents depend crucially on exploration to obtain informative data for the learning process as the lack of enough information could hinder effective learning. In this article, we provide a survey of modern exploration methods in (Sequential) reinforcement learning, as well as a taxonomy of exploration methods.
Locally Persistent Exploration in Continuous Control Tasks with Sparse Rewards
Dec 26, 2020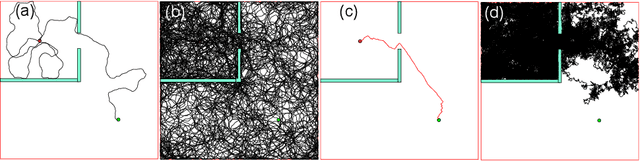
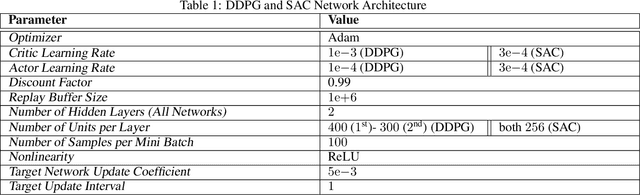
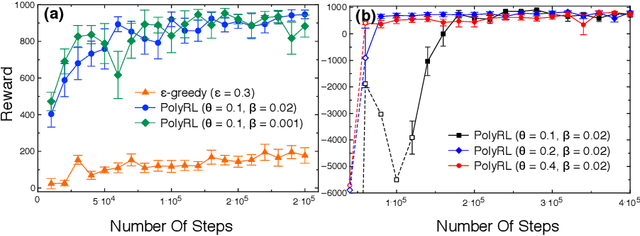
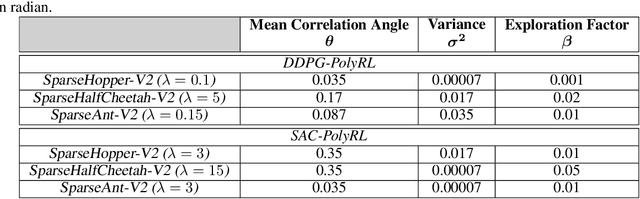
A major challenge in reinforcement learning is the design of exploration strategies, especially for environments with sparse reward structures and continuous state and action spaces. Intuitively, if the reinforcement signal is very scarce, the agent should rely on some form of short-term memory in order to cover its environment efficiently. We propose a new exploration method, based on two intuitions: (1) the choice of the next exploratory action should depend not only on the (Markovian) state of the environment, but also on the agent's trajectory so far, and (2) the agent should utilize a measure of spread in the state space to avoid getting stuck in a small region. Our method leverages concepts often used in statistical physics to provide explanations for the behavior of simplified (polymer) chains, in order to generate persistent (locally self-avoiding) trajectories in state space. We discuss the theoretical properties of locally self-avoiding walks, and their ability to provide a kind of short-term memory, through a decaying temporal correlation within the trajectory. We provide empirical evaluations of our approach in a simulated 2D navigation task, as well as higher-dimensional MuJoCo continuous control locomotion tasks with sparse rewards.
Predicting Regional Locust Swarm Distribution with Recurrent Neural Networks
Nov 29, 2020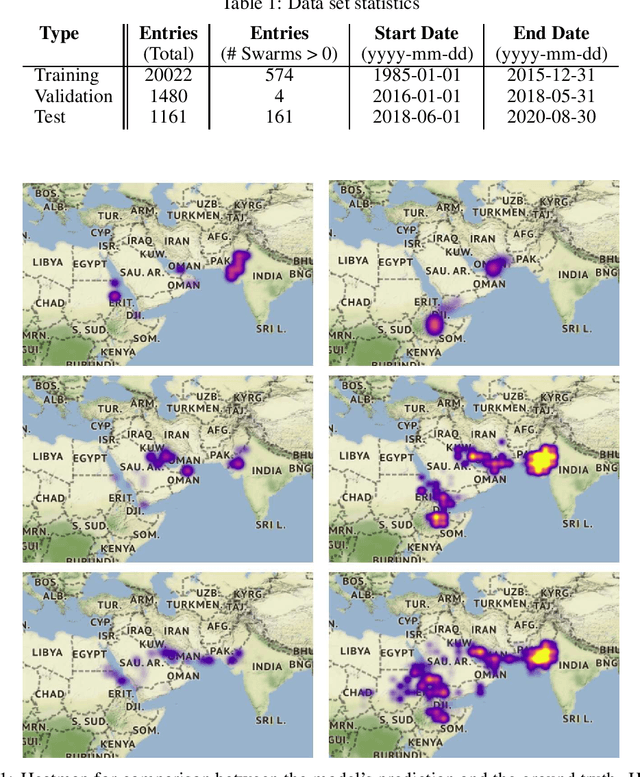
Locust infestation of some regions in the world, including Africa, Asia and Middle East has become a concerning issue that can affect the health and the lives of millions of people. In this respect, there have been attempts to resolve or reduce the severity of this problem via detection and monitoring of locust breeding areas using satellites and sensors, or the use of chemicals to prevent the formation of swarms. However, such methods have not been able to suppress the emergence and the collective behaviour of locusts. The ability to predict the location of the locust swarms prior to their formation, on the other hand, can help people get prepared and tackle the infestation issue more effectively. Here, we use machine learning to predict the location of locust swarms using the available data published by the Food and Agriculture Organization of the United Nations. The data includes the location of the observed swarms as well as environmental information, including soil moisture and the density of vegetation. The obtained results show that our proposed model can successfully, and with reasonable precision, predict the location of locust swarms, as well as their likely level of damage using a notion of density.