 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Smooth Sea Never Made a Skilled $\texttt{SAILOR}$: Robust Imitation via Learning to Search
Jun 05, 2025



The fundamental limitation of the behavioral cloning (BC) approach to imitation learning is that it only teaches an agent what the expert did at states the expert visited. This means that when a BC agent makes a mistake which takes them out of the support of the demonstrations, they often don't know how to recover from it. In this sense, BC is akin to giving the agent the fish -- giving them dense supervision across a narrow set of states -- rather than teaching them to fish: to be able to reason independently about achieving the expert's outcome even when faced with unseen situations at test-time. In response, we explore learning to search (L2S) from expert demonstrations, i.e. learning the components required to, at test time, plan to match expert outcomes, even after making a mistake. These include (1) a world model and (2) a reward model. We carefully ablate the set of algorithmic and design decisions required to combine these and other components for stable and sample/interaction-efficient learning of recovery behavior without additional human corrections. Across a dozen visual manipulation tasks from three benchmarks, our approach $\texttt{SAILOR}$ consistently out-performs state-of-the-art Diffusion Policies trained via BC on the same data. Furthermore, scaling up the amount of demonstrations used for BC by 5-10$\times$ still leaves a performance gap. We find that $\texttt{SAILOR}$ can identify nuanced failures and is robust to reward hacking. Our code is available at https://github.com/arnavkj1995/SAILOR .
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Multi-Turn Code Generation Through Single-Step Rewards
Feb 27, 2025We address the problem of code generation from multi-turn execution feedback. Existing methods either generate code without feedback or use complex, hierarchical reinforcement learning to optimize multi-turn rewards. We propose a simple yet scalable approach, $\mu$Code, that solves multi-turn code generation using only single-step rewards. Our key insight is that code generation is a one-step recoverable MDP, where the correct code can be recovered from any intermediate code state in a single turn. $\mu$Code iteratively trains both a generator to provide code solutions conditioned on multi-turn execution feedback and a verifier to score the newly generated code. Experimental evaluations show that our approach achieves significant improvements over the state-of-the-art baselines. We provide analysis of the design choices of the reward models and policy, and show the efficacy of $\mu$Code at utilizing the execution feedback. Our code is available at https://github.com/portal-cornell/muCode.
Non-Adversarial Inverse Reinforcement Learning via Successor Feature Matching
Nov 11, 2024



In inverse reinforcement learning (IRL), an agent seeks to replicate expert demonstrations through interactions with the environment. Traditionally, IRL is treated as an adversarial game, where an adversary searches over reward models, and a learner optimizes the reward through repeated RL procedures. This game-solving approach is both computationally expensive and difficult to stabilize. In this work, we propose a novel approach to IRL by direct policy optimization: exploiting a linear factorization of the return as the inner product of successor features and a reward vector, we design an IRL algorithm by policy gradient descent on the gap between the learner and expert features. Our non-adversarial method does not require learning a reward function and can be solved seamlessly with existing actor-critic RL algorithms. Remarkably, our approach works in state-only settings without expert action labels, a setting which behavior cloning (BC) cannot solve. Empirical results demonstrate that our method learns from as few as a single expert demonstration and achieves improved performance on various control tasks.
Maximum State Entropy Exploration using Predecessor and Successor Representations
Jun 26, 2023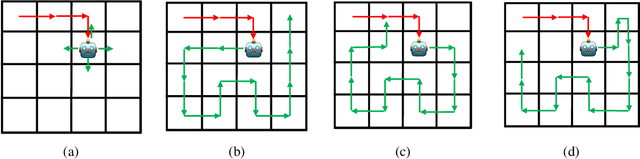

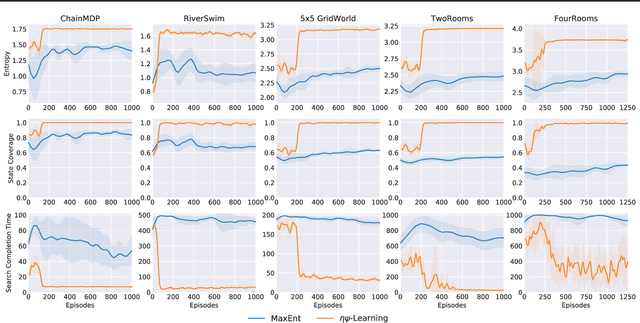

Animals have a developed ability to explore that aids them in important tasks such as locating food, exploring for shelter, and finding misplaced items. These exploration skills necessarily track where they have been so that they can plan for finding items with relative efficiency. Contemporary exploration algorithms often learn a less efficient exploration strategy because they either condition only on the current state or simply rely on making random open-loop exploratory moves. In this work, we propose $\eta\psi$-Learning, a method to learn efficient exploratory policies by conditioning on past episodic experience to make the next exploratory move. Specifically, $\eta\psi$-Learning learns an exploration policy that maximizes the entropy of the state visitation distribution of a single trajectory. Furthermore, we demonstrate how variants of the predecessor representation and successor representations can be combined to predict the state visitation entropy. Our experiments demonstrate the efficacy of $\eta\psi$-Learning to strategically explore the environment and maximize the state coverage with limited samples.
Predicting Regional Locust Swarm Distribution with Recurrent Neural Networks
Nov 29, 2020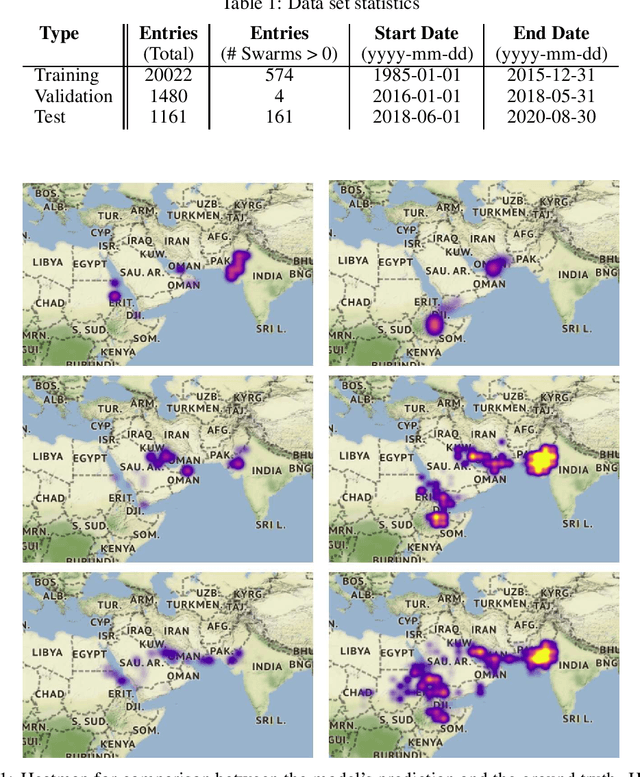
Locust infestation of some regions in the world, including Africa, Asia and Middle East has become a concerning issue that can affect the health and the lives of millions of people. In this respect, there have been attempts to resolve or reduce the severity of this problem via detection and monitoring of locust breeding areas using satellites and sensors, or the use of chemicals to prevent the formation of swarms. However, such methods have not been able to suppress the emergence and the collective behaviour of locusts. The ability to predict the location of the locust swarms prior to their formation, on the other hand, can help people get prepared and tackle the infestation issue more effectively. Here, we use machine learning to predict the location of locust swarms using the available data published by the Food and Agriculture Organization of the United Nations. The data includes the location of the observed swarms as well as environmental information, including soil moisture and the density of vegetation. The obtained results show that our proposed model can successfully, and with reasonable precision, predict the location of locust swarms, as well as their likely level of damage using a notion of density.
The Angel is in the Priors: Improving GAN based Image and Sequence Inpainting with Better Noise and Structural Priors
Aug 16, 2019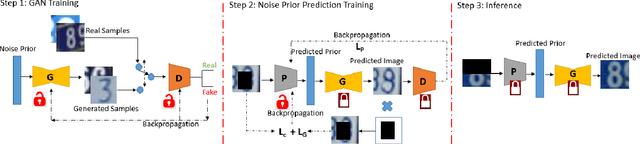
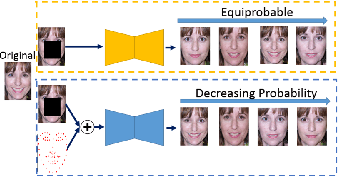
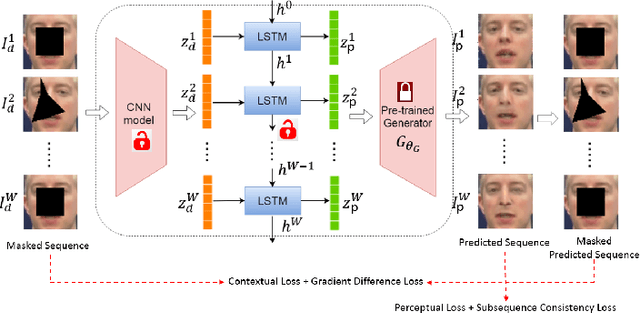

Contemporary deep learning based inpainting algorithms are mainly based on a hybrid dual stage training policy of supervised reconstruction loss followed by an unsupervised adversarial critic loss. However, there is a dearth of literature for a fully unsupervised GAN based inpainting framework. The primary aversion towards the latter genre is due to its prohibitively slow iterative optimization requirement during inference to find a matching noise prior for a masked image. In this paper, we show that priors matter in GAN: we learn a data driven parametric network to predict a matching prior for a given image. This converts an iterative paradigm to a single feed forward inference pipeline with a massive 1500X speedup and simultaneous improvement in reconstruction quality. We show that an additional structural prior imposed on GAN model results in higher fidelity outputs. To extend our model for sequence inpainting, we propose a recurrent net based grouped noise prior learning. To our knowledge, this is the first demonstration of an unsupervised GAN based sequence inpainting. A further improvement in sequence inpainting is achieved with an additional subsequence consistency loss. These contributions improve the spatio-temporal characteristics of reconstructed sequences. Extensive experiments conducted on SVHN, Standford Cars, CelebA and CelebA-HQ image datasets, synthetic sequences and ViDTIMIT video datasets reveal that we consistently improve upon previous unsupervised baseline and also achieve comparable performances(sometimes also better) to hybrid benchmarks.
Faster Unsupervised Semantic Inpainting: A GAN Based Approach
Aug 14, 2019
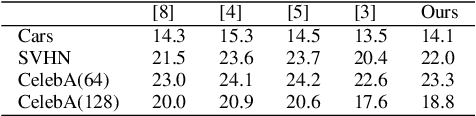


In this paper, we propose to improve the inference speed and visual quality of contemporary baseline of Generative Adversarial Networks (GAN) based unsupervised semantic inpainting. This is made possible with better initialization of the core iterative optimization involved in the framework. To our best knowledge, this is also the first attempt of GAN based video inpainting with consideration to temporal cues. On single image inpainting, we achieve about 4.5-5$\times$ speedup and 80$\times$ on videos compared to baseline. Simultaneously, our method has better spatial and temporal reconstruction qualities as found on three image and one video dataset.
Bayesian Optimisation with Prior Reuse for Motion Planning in Robot Soccer
Oct 18, 2017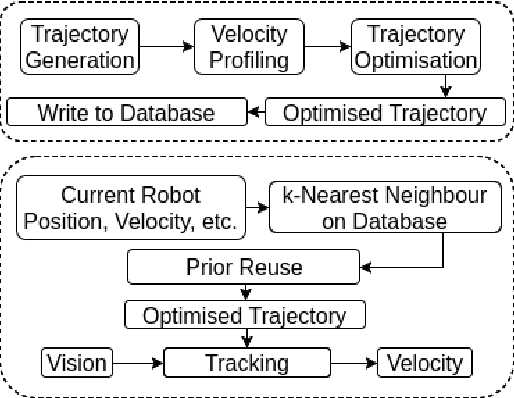

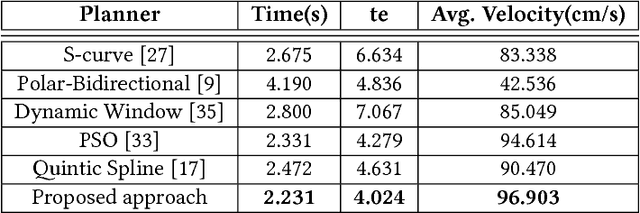
We integrate learning and motion planning for soccer playing differential drive robots using Bayesian optimisation. Trajectories generated using end-slope cubic Bezier splines are first optimised globally through Bayesian optimisation for a set of candidate points with obstacles. The optimised trajectories along with robot and obstacle positions and velocities are stored in a database. The closest planning situation is identified from the database using k-Nearest Neighbour approach. It is further optimised online through reuse of prior information from previously optimised trajectory. Our approach reduces computation time of trajectory optimisation considerably. Velocity profiling generates velocities consistent with robot kinodynamoic constraints, and avoids collision and slipping. Extensive testing is done on developed simulator, as well as on physical differential drive robots. Our method shows marked improvements in mitigating tracking error, and reducing traversal and computational time over competing techniques under the constraints of performing tasks in real time.
Recurrent Memory Addressing for describing videos
Mar 23, 2017
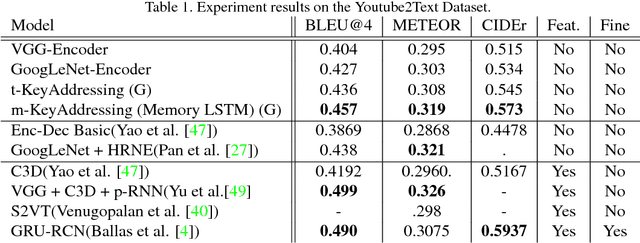
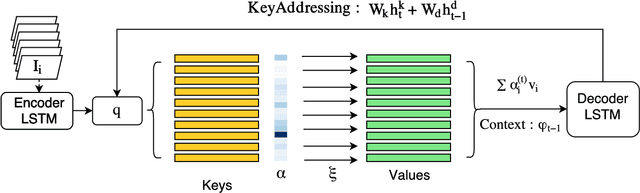
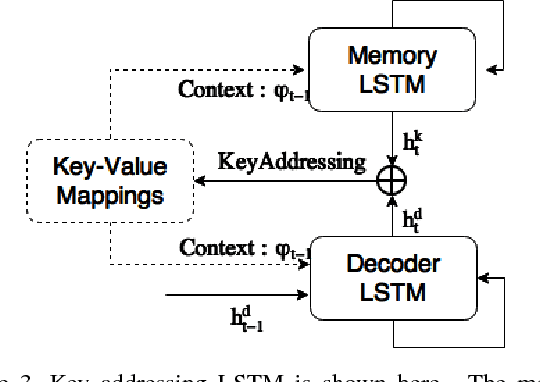
In this paper, we introduce Key-Value Memory Networks to a multimodal setting and a novel key-addressing mechanism to deal with sequence-to-sequence models. The proposed model naturally decomposes the problem of video captioning into vision and language segments, dealing with them as key-value pairs. More specifically, we learn a semantic embedding (v) corresponding to each frame (k) in the video, thereby creating (k, v) memory slots. We propose to find the next step attention weights conditioned on the previous attention distributions for the key-value memory slots in the memory addressing schema. Exploiting this flexibility of the framework, we additionally capture spatial dependencies while mapping from the visual to semantic embedding. Experiments done on the Youtube2Text dataset demonstrate usefulness of recurrent key-addressing, while achieving competitive scores on BLEU@4, METEOR metrics against state-of-the-art models.