 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Memory Addressing for describing videos
Paper and Code
Mar 23, 2017
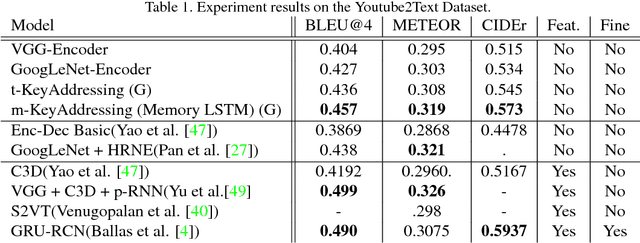
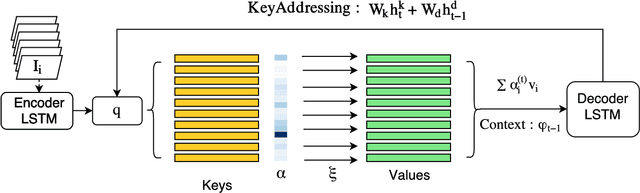
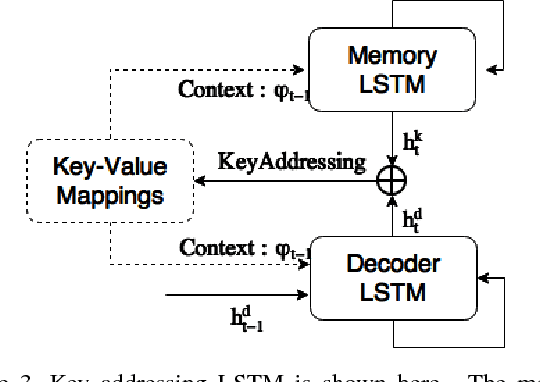
In this paper, we introduce Key-Value Memory Networks to a multimodal setting and a novel key-addressing mechanism to deal with sequence-to-sequence models. The proposed model naturally decomposes the problem of video captioning into vision and language segments, dealing with them as key-value pairs. More specifically, we learn a semantic embedding (v) corresponding to each frame (k) in the video, thereby creating (k, v) memory slots. We propose to find the next step attention weights conditioned on the previous attention distributions for the key-value memory slots in the memory addressing schema. Exploiting this flexibility of the framework, we additionally capture spatial dependencies while mapping from the visual to semantic embedding. Experiments done on the Youtube2Text dataset demonstrate usefulness of recurrent key-addressing, while achieving competitive scores on BLEU@4, METEOR metrics against state-of-the-art models.